LLM Post-Training¶
约 957 个字 12 张图片 预计阅读时间 3 分钟
Abstract
- LLM Fine-Tuning
- Supervised Fine-Tuning (SFT)
- Reinforcement Learning from Human Feedback (RLHF)
- Parameter Efficient Fine-Tuning (PEFT)
- BitFit, TinyTL, Adapter, Prompt-Tuning, Prefix-Tuning
- LoRA, QLoRA, BitDelta
- Multi-modal LLMs
- Cross-Attention Based: Flamingo
- Visual Tokens as Input: PaLM-E, VILA
- Enabling Visual Outputs: VILA-U
- Prompt Engineering
- In-Context Learning (ICL)
- Chain-of-Thought (CoT)
- Retrieval Augmented Generation (RAG)
LLM Fine-Tuning¶
-
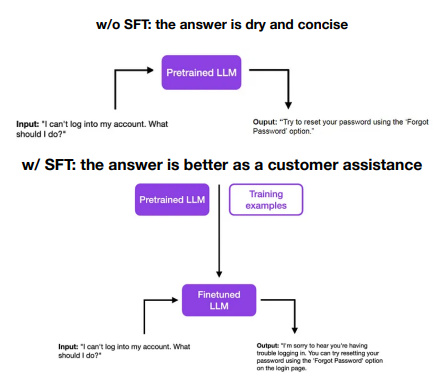
Supervised Fine-Tuning (SFT): 希望 LLMs 生成符合人类偏好的答案,因此我们把人类希望看到的答案作为 ground truth,然后用监督学习的方式微调。
Example
-
Reinforcement Learning from Human Feedback (RLHF)
-
传统的模型依赖于静态的度量(如 BLEU、ROUGE
) ,但是 RLHF 能够基于主观的,人类定义的品质(如创造性、真实性、有用性)来进行优化。ChatGPT 就是一个使用 RLHF 的例子。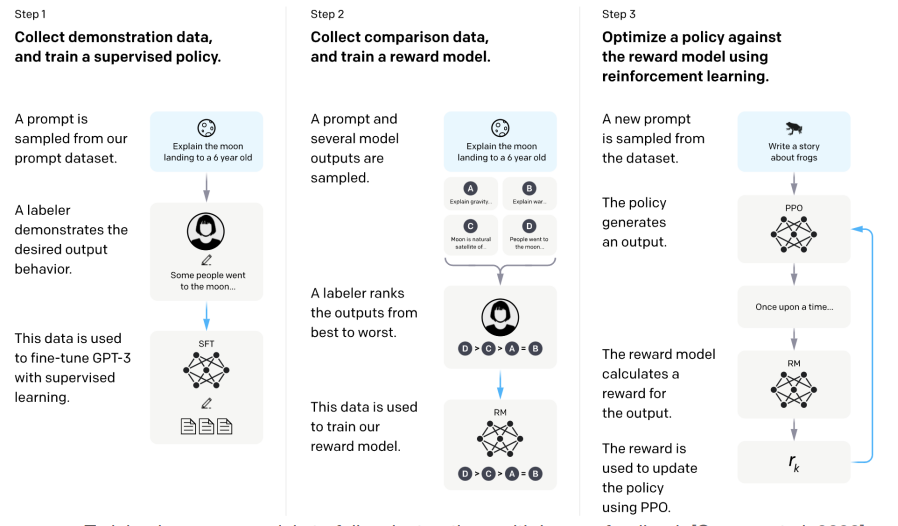
- step 1: 从数据集中采样 prompt,同时人工写出希望的答案作为 ground truth,微调 GPT-3。
- step 2: 采样 prompt,送到 SFT 后的模型进行生成,得到多个答案。由人工标注,对生成的答案进行排序,训练一个 reward model。
-
step 3: 采样 prompt,采用 PPO 进行强化学习,模型生成答案并得到 reward model 的打分,以此更新。
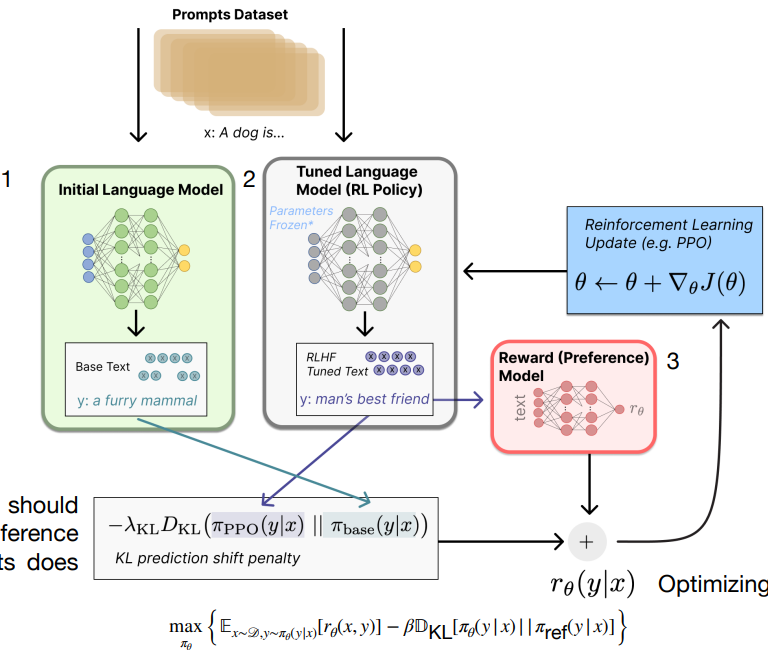
这里微调时,使用一个 KL 散度的损失加上奖励模型的损失。KL 散度用于控制微调后的模型和初始的模型差别较小。
-
-
Direct Preference Optimization (DPO)
-
RLHF 需要训练多个模型,DPO 将问题转为单次 SFT 任务。
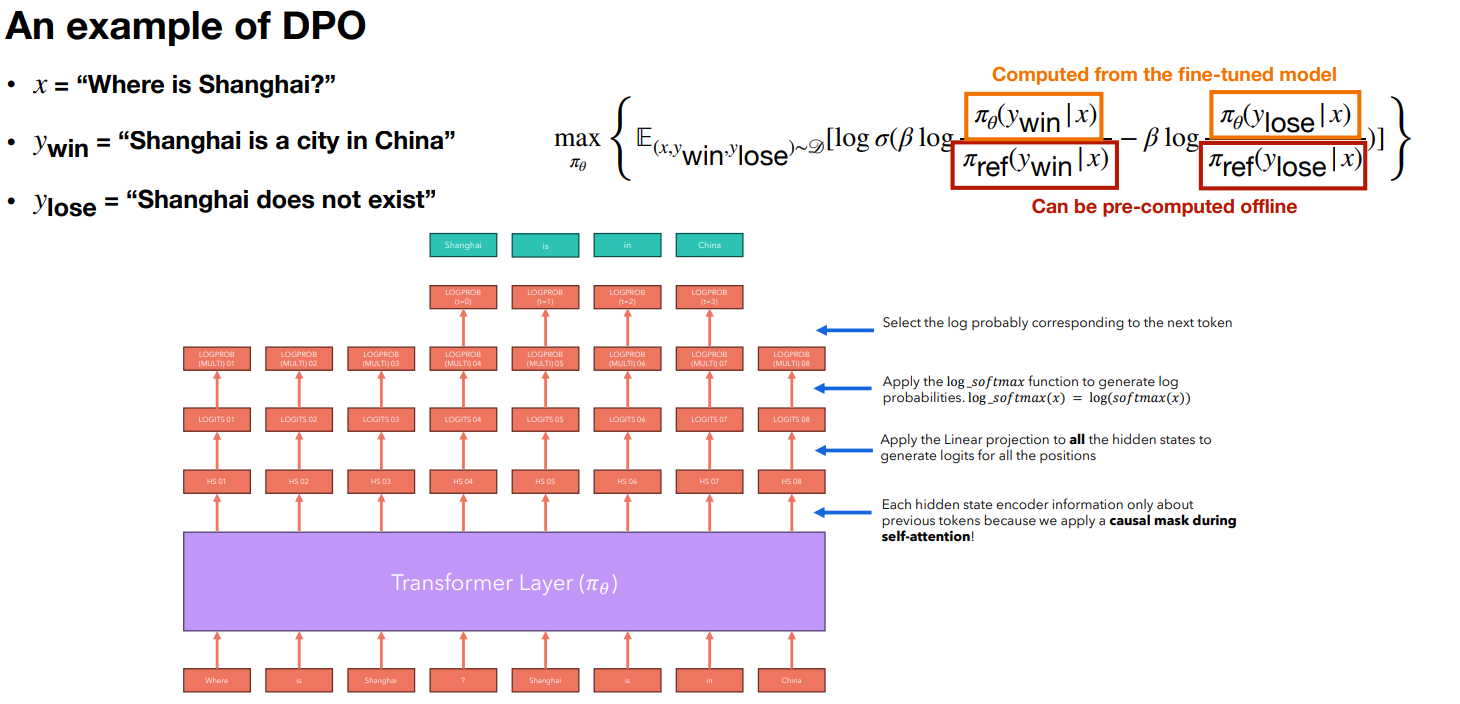
-
-
PEFT 同之前的内容,这里仅记录之前没提过的内容。
- Bit-Delta
- LoRA 微调中有很多冗余,实际上 Your Fine-Tune May Only Be Worth One Bit.
-
微调时,\(\nabla\) 由一个 fp16 scale factor (per tensor) 乘上 1-b 矩阵得到(+1/-1
) ,最终的权重是原始的权重加上 \(\nabla\)。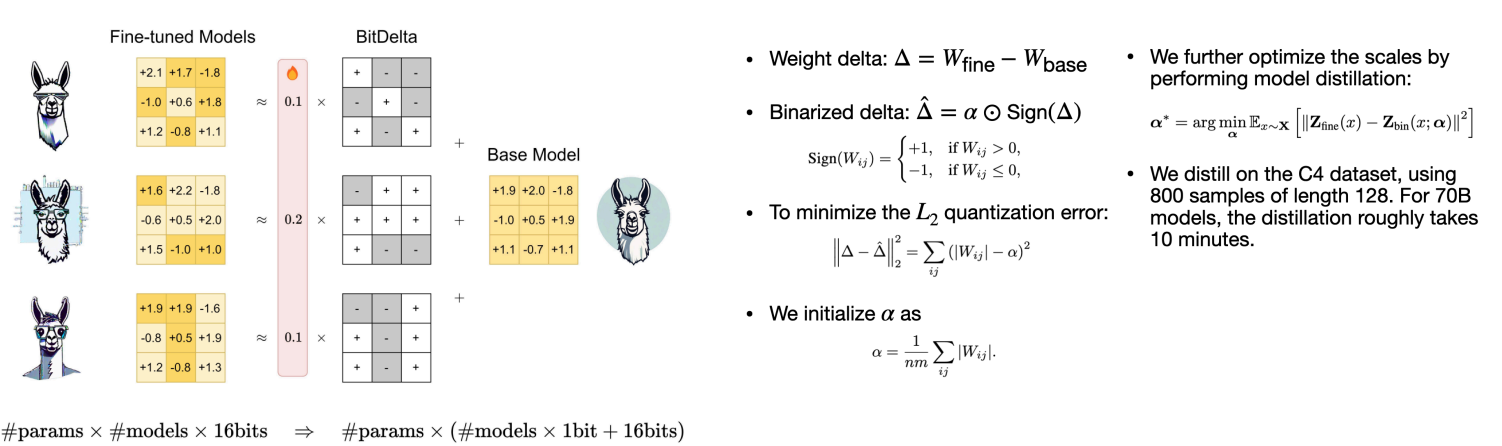
- Bit-Delta
Multi-model LLMs¶
- Vision Language Model 要同时理解文本和图像,常用两种方式:
- Cross-attention,将视觉信息注入 LLMs(Flamingo style)
- 将 Visual tokens 作为输入(PaLM-E style)
-
Flamingo
-
固定 LLM,添加 cross-attention 层来处理视觉信息。
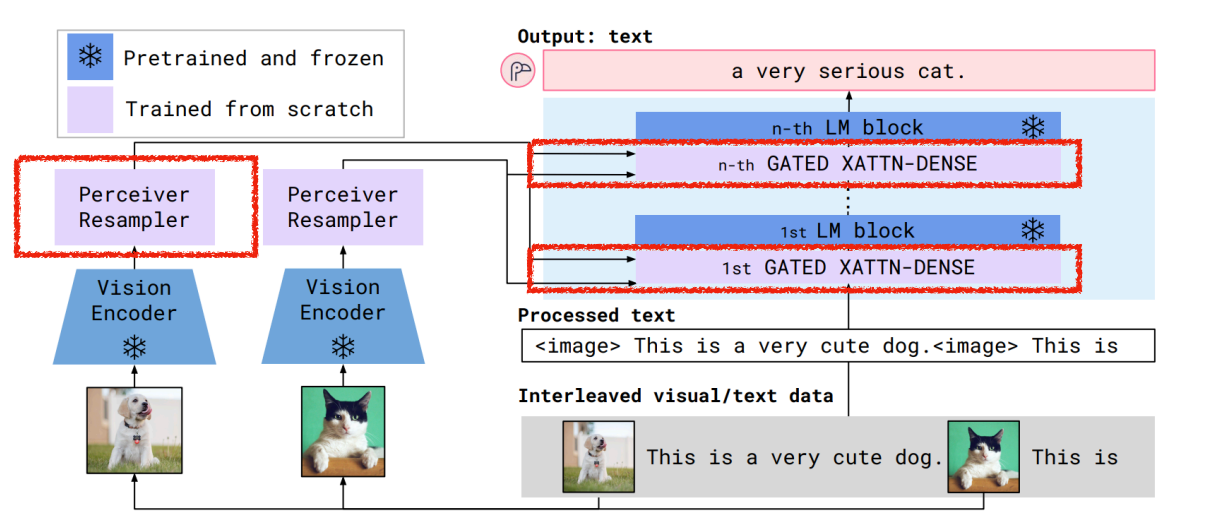
-
其中的 Perceiver Resampler 将变长的特征图映射到固定长度的 token。
Example
可以看到这里的输出与输入的 token 数量无关,5 和 dim 都是人为设定的。
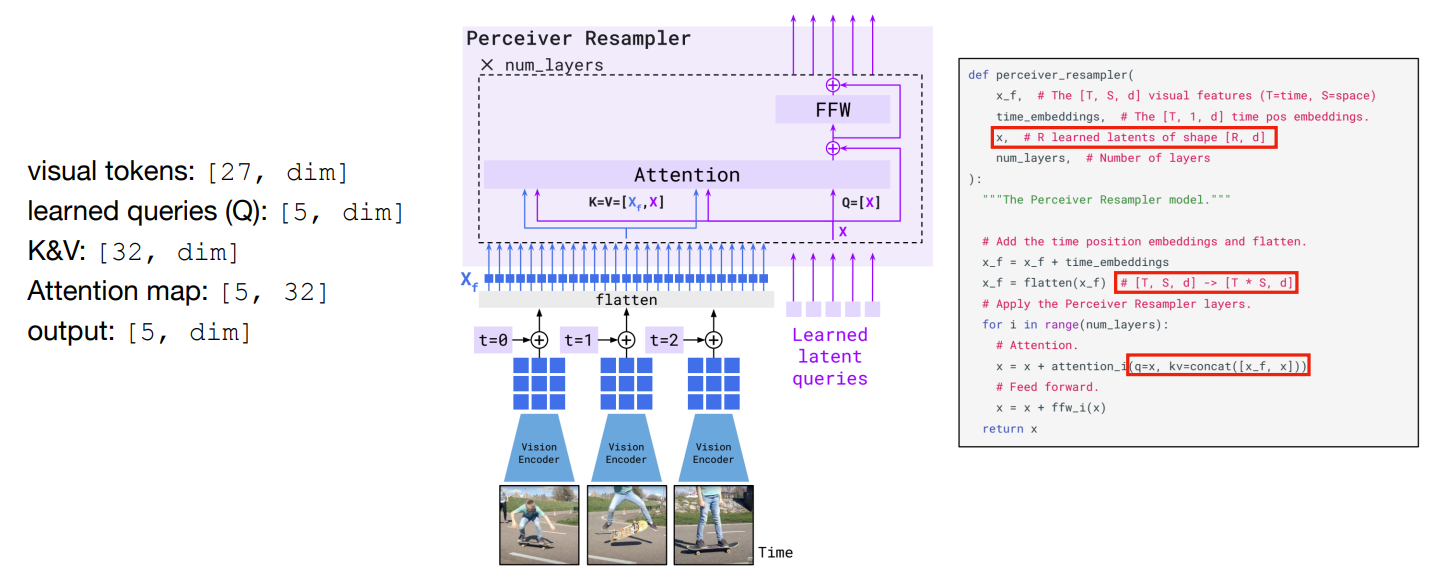
-
其中 cross-attention 的输入 K V 均来自 Perceiver Resampler 处理后的输入 X,而 Q 来自语言模型的输入 Y。这里我们有 tanh 来控制要添加多少视觉信息,因此初始化为 0。
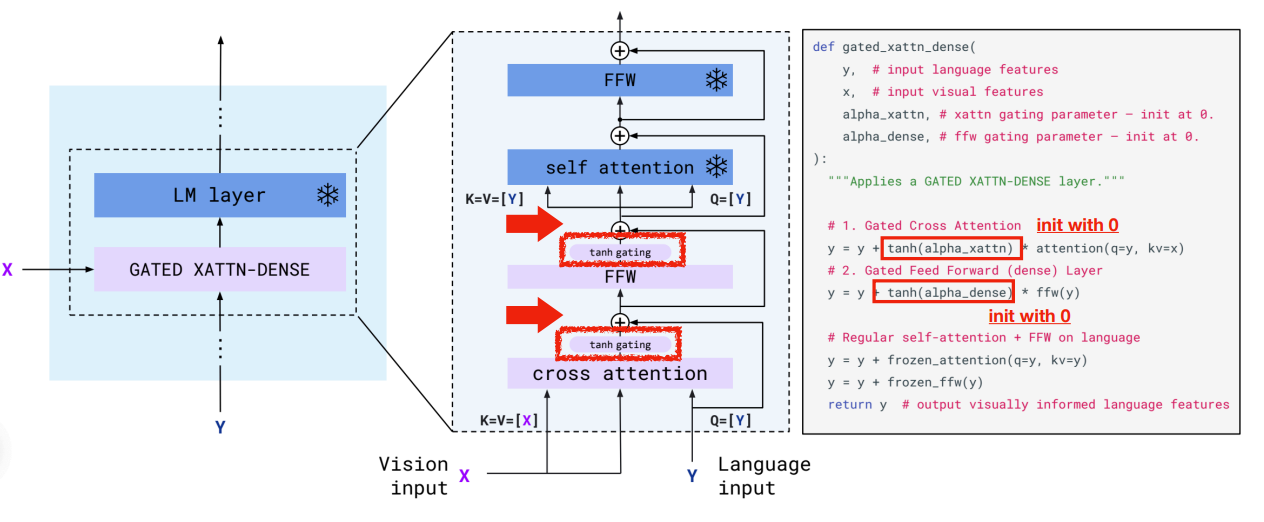
-
-
PaLM-E
-
将视觉输入(或者其他模态)作为 token 输入
。 (everything is tokenized.)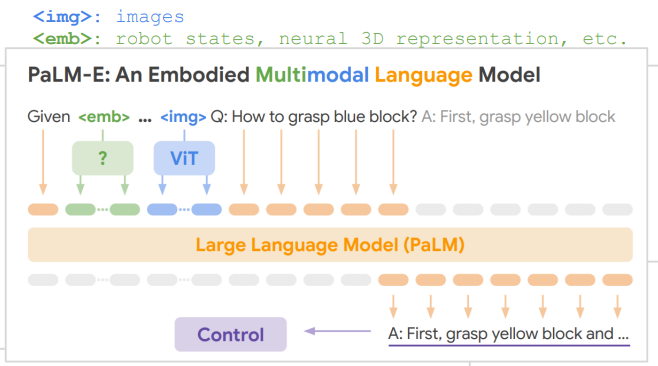
-
-
VILA: Visual Language Model
-
通过 image tokens 增强语言模型。训练时先训练 projector,再预训练,最后进行 SFT。
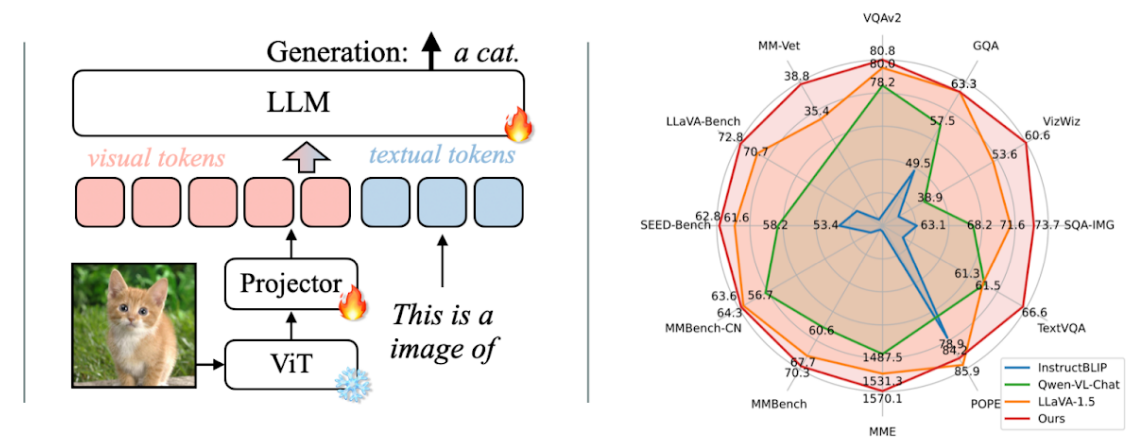
-
Findings
- 固定 LLMs 可以获得很好的 zero-shot 性能,但是缺少 in-context 学习的能力(这需要 unfreeze LLMs
) 。 - Interlevead 的预训练数据最好,image-text pairs 不是最优的。
- 即使是视觉模型,添加 text-only 的数据进行指令微调也是有必要的。
-
原始图像的分辨率比 token 的数量更重要。
High Resolution ViTs in VLMs
为了支持更高的分辨率,
- InternVL 通过 tiling + thumbnail 的方式。tiling 指有预定义好长宽的 template,将输入图像拆分为若干个 template,最后将 token 拼接起来即可;thumbnail 即对原始图像进行下采样,得到缩略图
。 (不同的视觉任务偏好不同的输入分辨率) - 另一种方式,把低分辨率的图像和文本特征作为 Q,高分辨率的图像作为 K V,。但这样需要重新训练 LLMs。
- InternVL 通过 tiling + thumbnail 的方式。tiling 指有预定义好长宽的 template,将输入图像拆分为若干个 template,最后将 token 拼接起来即可;thumbnail 即对原始图像进行下采样,得到缩略图
- 固定 LLMs 可以获得很好的 zero-shot 性能,但是缺少 in-context 学习的能力(这需要 unfreeze LLMs
-
Prompt Engineering¶
- ICL, CoT 同之前的内容
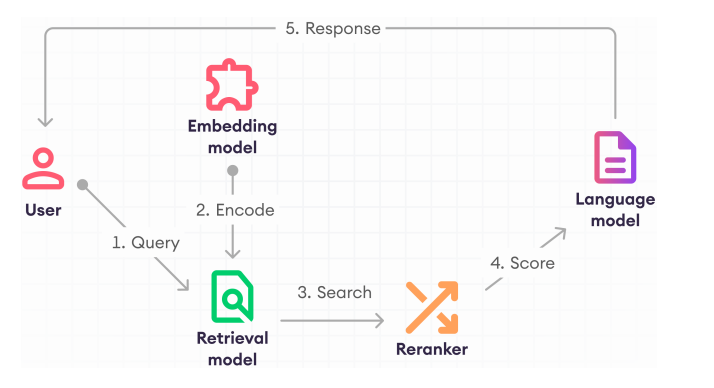
- Retrieval Augmented Generation (RAG)
- LLMs 不能把所有的知识记录在参数里,很容易过时而且很难更新。
- Pipeline
- Embedding Model: 将文本编码为向量。
- Retriever: 从数据库中检索相关的文本。
- Reranker (optional): 对检索到的文本进行排序,提供每个文档的相关分数。
-
Language model: 根据检索到的文本,以及最初的问题生成答案。