Data Storage Structures¶
约 1603 个字 6 行代码 12 张图片 预计阅读时间 5 分钟
Abstract
- File Organization
- Fixed-Length Records
- Variable-Length Records
- Organization of Records in Files
- Heap File Organization
- Sequential File Organization
- Multitable Clustering File Organization
- Table Partition
- Data-Dictionary Storage
- Storage Access & Buffer manager
- LRU strategy
- Clock algorithm
- Columnar Representation
File Organization¶
- The database is stored as a collection of files.
- Each file is a sequence of records.
- A record is a sequence of fields.
One approach:
- assume record size is fixed
- each file has records of one particular type only
- different files are used for different relations
Fixed-Length Records¶
Store record i starting from byte \(n \times (i – 1)\), where n is the size of each record.
Record access is simple but records may cross blocks
Modification: do not allow records to cross block boundaries
Deletion of record i: alternatives:
- move records \(i + 1,\ldots , n\) to \(i, \ldots. , n – 1\)
- move record n to i
- do not move records, but link all free records on a free list
要删除的条打上标记,形成一个空记录的链表。
以后如果要往这个块里插入,直接通过指针找到空记录插入即可,随后更新指针。

Variable-Length Records¶
Variable-length records arise in database systems in several ways:
- Storage of multiple record types in a file.
- Record types that allow variable lengths for one or more fields such as strings (
varchar) - Record types that allow repeating fields (used in some older data models).
Variable length attributes represented by fixed size (offset, length), with actual data stored after all fixed length attributes
Null values represented by null-value bitmap(空位图)
Example
不定长的保存在后面,定长的 (offset, length) 保存在前面。

这里位置 12 放的 65000 是定长的 salary.
位置 20 放的 0000, 表示前面四个属性均是非空的, 1 表示空。(放在前面也可以,只要在一个固定位置能找到即可)
前提:每一个记录都是被放在一起的。(有按列存储的方式)
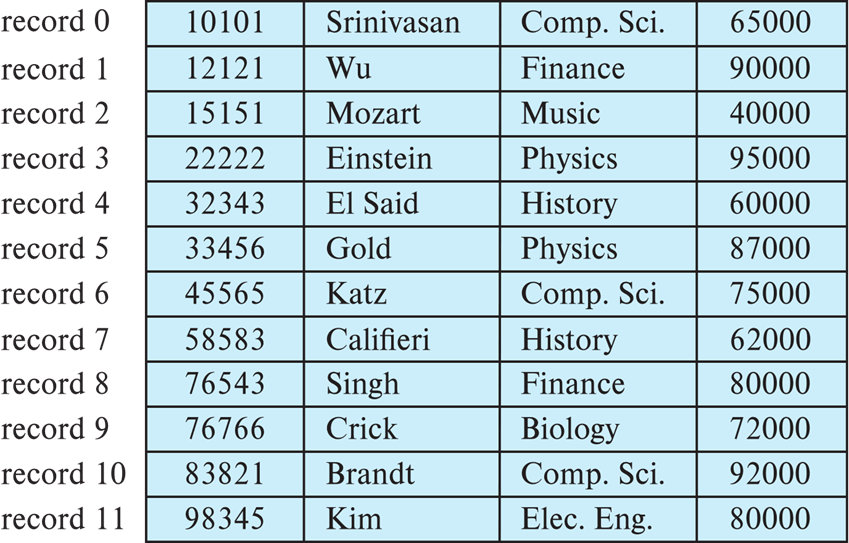
Slotted Page Structure¶
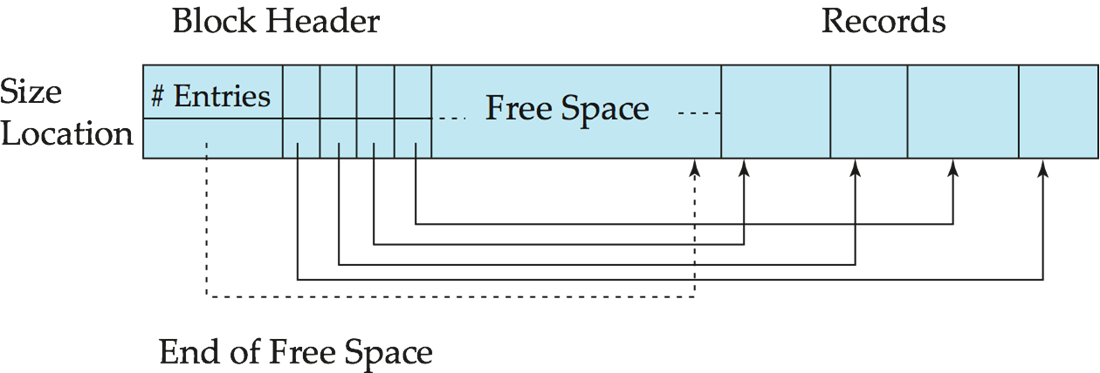
Slotted page(分槽页) header contains:
- number of record entries
- end of free space in the block
一个指针指向 free space 末尾,用来分配内存 - location and size of each record
当删除的时候,一种方法是把后面的记录挪过去,让自由空间更紧凑,这样需要修改 entries, free space 的指针 , 偏移量也要调整。也可以暂时不调整,等后面如果需要分配内存但不够用时,再一次性重整之前的空间。
Organization of Records in Files¶
插入到哪个文件的哪个位置?
- Heap – record can be placed anywhere in the file where there is space
有位置我就插进去 - Sequential – store records in sequential order, based on the value of the search key of each record
插入的元素维护一个次序 - In a multitable clustering file organization records of several different relations can be stored in the same file Motivation: store related records on the same block to minimize I/O
- B+-tree file organization - Ordered storage even with inserts/deletes
- Hashing – a hash function computed on search key; the result specifies in which block of the file the record should be placed
Heap File Organization¶
Array with 1 entry per block. Each entry is a few bits to a byte, and records fraction of block that is free
Free-space map
维护一个空闲块的地图,记录这个块的空闲程度。
Example
3 bits per block, value divided by 8 indicates
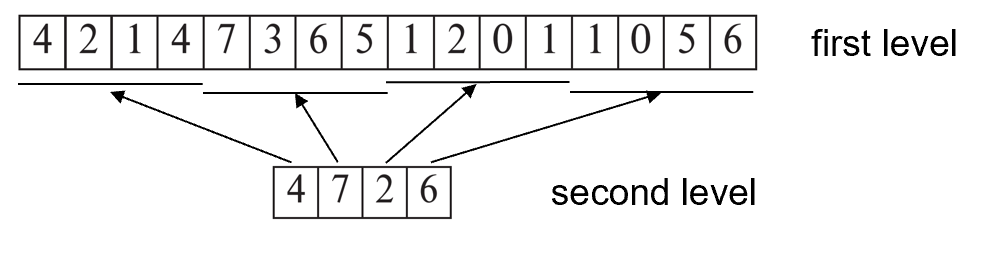
如 4 表示 4/8 空闲。
顺序访问比较低效,我们可以有第二层来表示其中的最大空闲块。
Sequential File Organization¶
Suitable for applications that require sequential processing of the entire file
The records in the file are ordered by a search-key
- Deletion – use pointer chains
- Insertion – locate the position where the record is to be inserted
要更新 pointer chain 效率低。我们把插入的放在末尾,通过指针维护秩序。
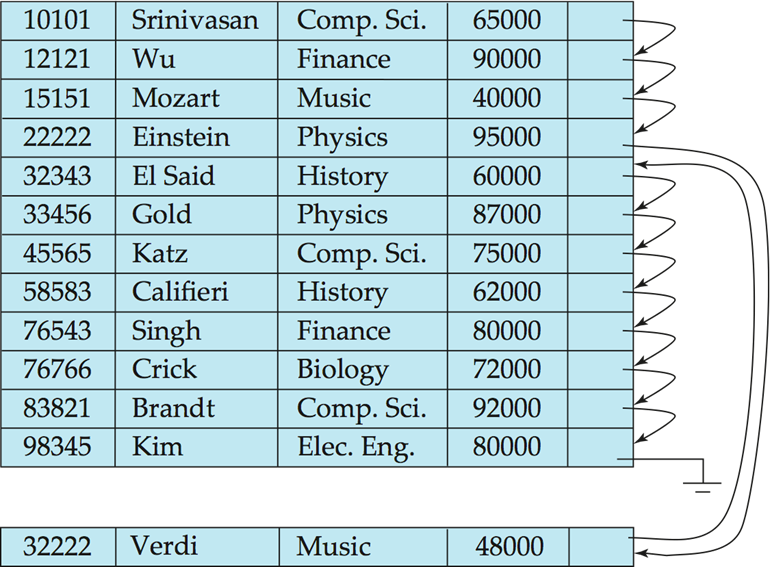
Need to reorganize the file from time to time to restore sequential order.
Multitable Clustering File Organization¶
Store several relations in one file using a multitable clustering file organization.
Example
对于老师和部分经常一起访问的情况,我们可以把这两个信息放在一起
但这样对于单独查找某个信息就不太方便。
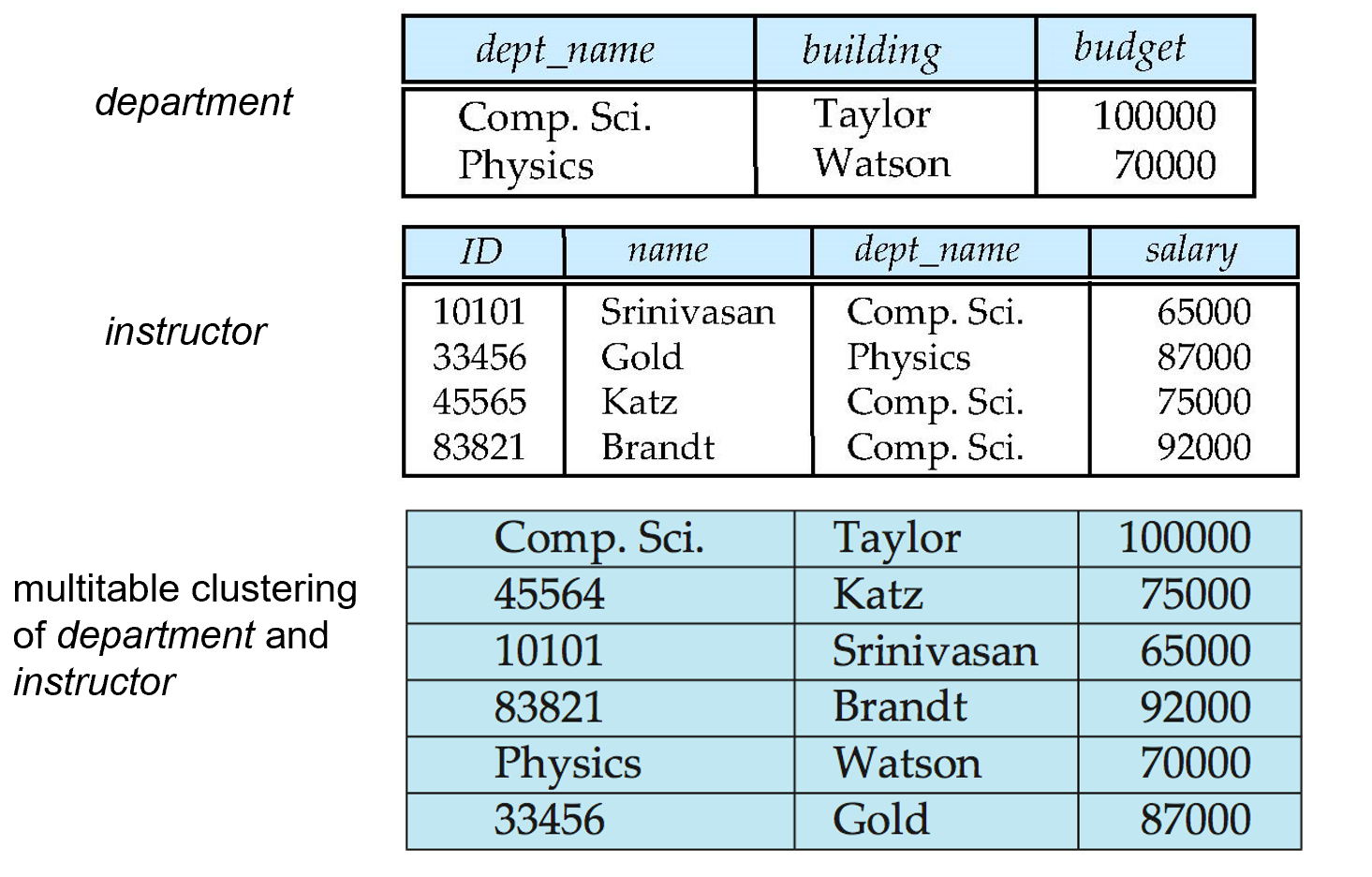
Table Partitioning¶
Table partitioning: Records in a relation can be partitioned into smaller relations that are stored separately
一个表太大,对于并行访问可能引发冲突。于是我们可以把表分开,如对于所有老师的表,我们可以把计算机系的老师分出来,数学系的老师分出来。(水平分割)也可以按列存储。
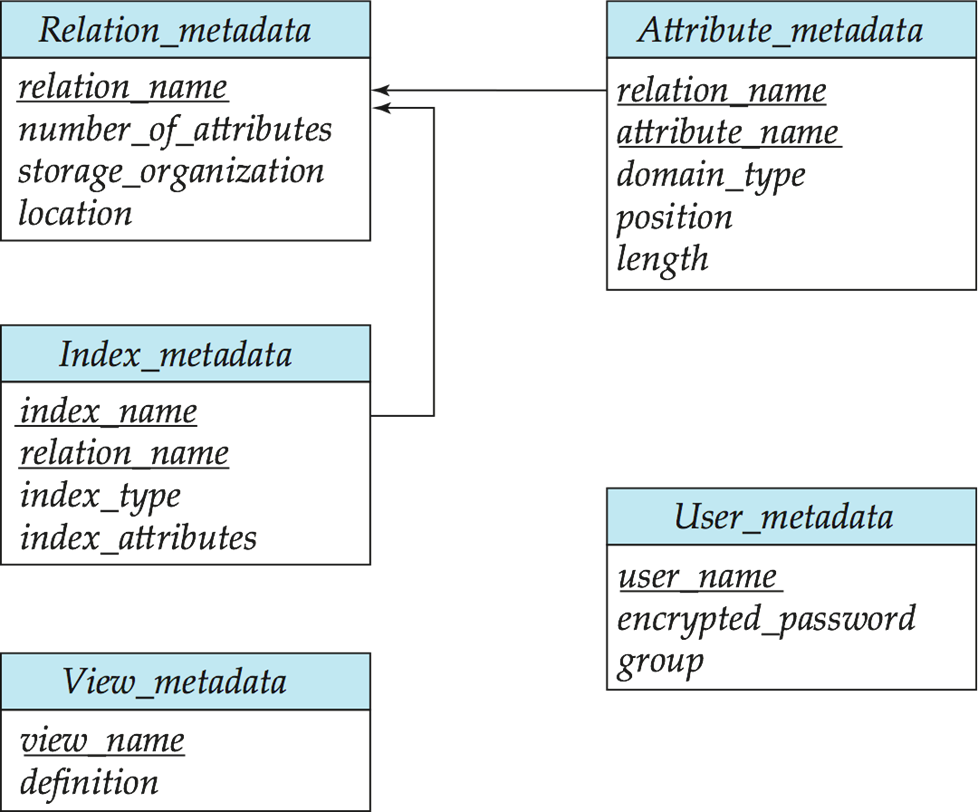
Data Dictionary Storage¶
The Data dictionary (also called system catalog) stores metadata; that is, data about data, such as
定义的数据也是数据 (metadata) 我们也需要把它们存储下来。
- Information about relations
- User and accounting information, including passwords
- Statistical and descriptive data
- Physical file organization information
- Information about indices
Storage Access & Buffer manager¶
Blocks are units of both storage allocation and data transfer.
Buffer – portion of main memory available to store copies of disk blocks.
Buffer manager – subsystem responsible for allocating buffer space in main memory.
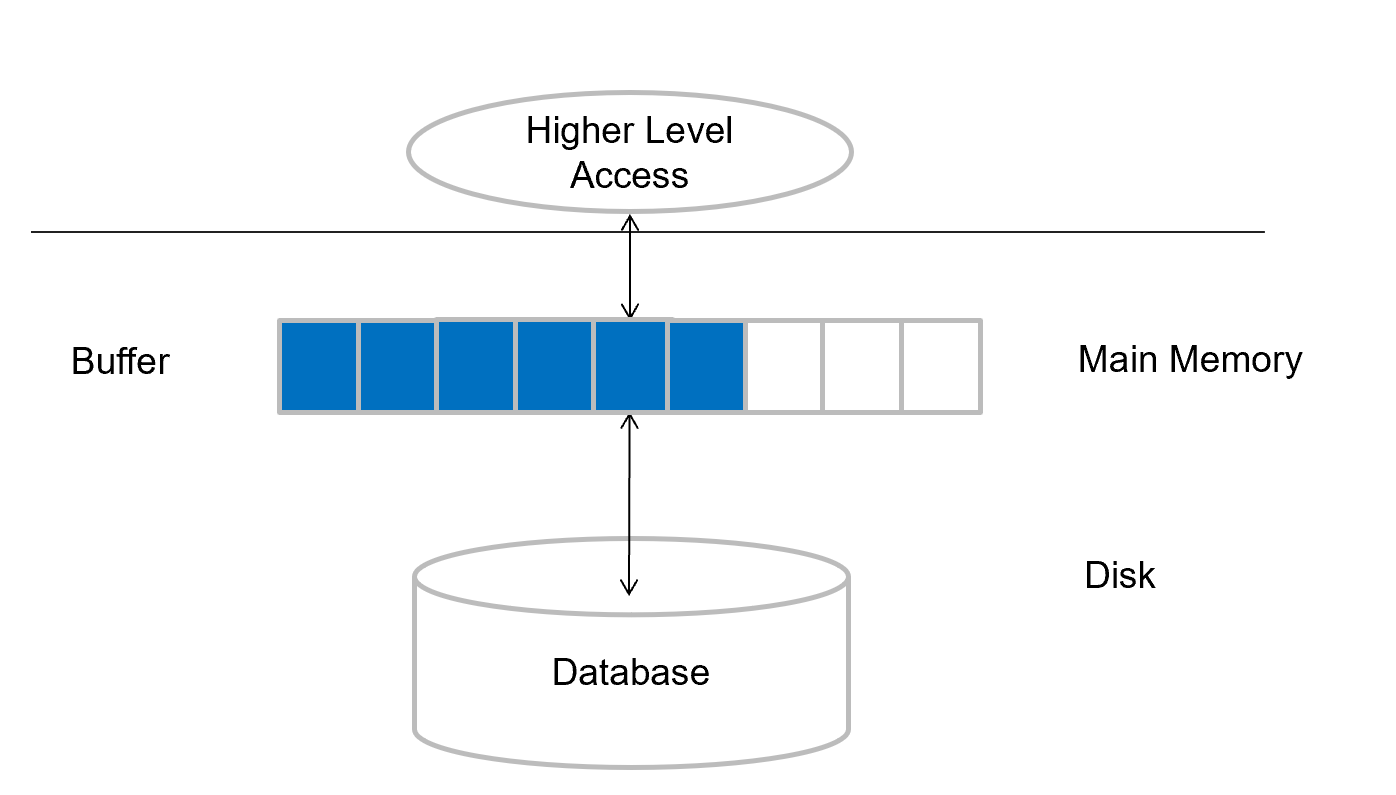
如我们要找某块,先在 buffer 中找,如果没找到就从磁盘中读出来放到 buffer 中。当 buffer 完了就需要考虑如何替换,替换哪一块。
LRU Example
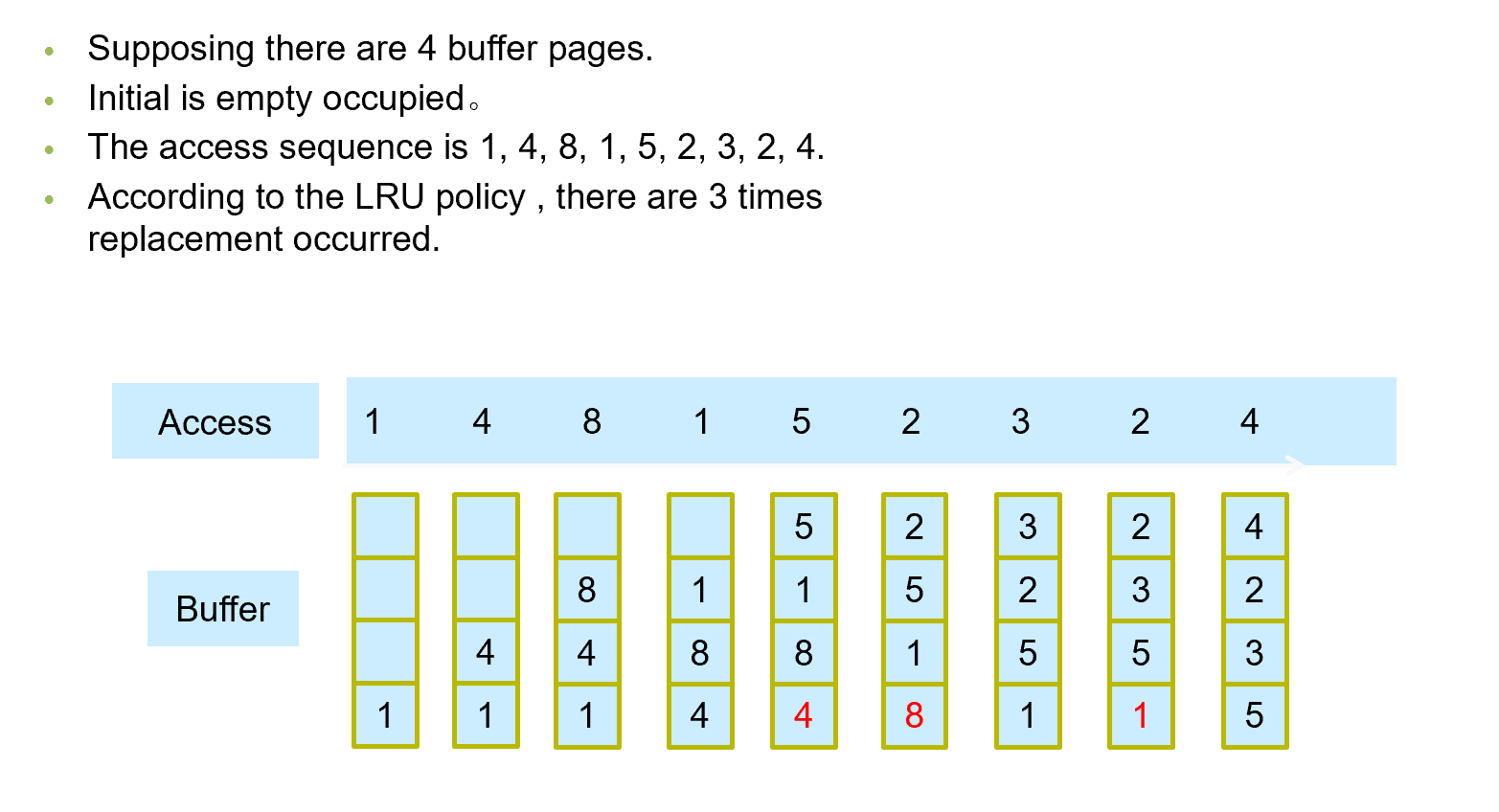
如果 4 被修改过了,那么替换时需要先把这块写回到磁盘中。写回时也要注意掉电等问题。
Programs call on the buffer manager when they need a block from disk.
- If the block is already in the buffer, buffer manager returns the address of the block in main memory
- If the block is not in the buffer, the buffer manager
- Allocates space in the buffer for the block
在 buffer 里替换空间,如果有空位可以直接分配,否则需要替换。- Replacing (throwing out) some other block, if required, to make space for the new block.
有不同的策略进行选择要丢弃的块。 - Replaced block written back to disk only if it was modified since the most recent time that it was written to/fetched from the disk.
- Replacing (throwing out) some other block, if required, to make space for the new block.
- Reads the block from the disk to the buffer, and returns the address of the block in main memory to requester.
- Allocates space in the buffer for the block
Pinned block
memory block that is not allowed to be written back to disk
正在访问这一块,那么这一块不能被替换出去
- Pin done before reading/writing data from a block
- Unpin done when read /write is complete
- Multiple concurrent pin/unpin operations possible
Keep a pin count, buffer block can be evicted only if pincount = 0
Shared and exclusive locks on buffer
Readers get shared lock, updates to a block require exclusive lock Locking rules:
- Only one process can get exclusive lock at a time
- Shared lock cannot be concurrently with exclusive lock
- Multiple processes may be given shared lock concurrently
Buffer-Replacement Policies¶
-
LRU strategy - replace the block least recently used.
- Idea behind LRU – use past pattern of block references as a predictor of future references
用过去的访问模式推断讲来的访问模式
LRU can be a bad strategy

- Idea behind LRU – use past pattern of block references as a predictor of future references
-
Toss-immediate strategy – frees the space occupied by a block as soon as the final tuple of that block has been processed
- Most recently used (MRU) strategy – system must pin the block currently being processed. After the final tuple of that block has been processed, the block is unpinned, and it becomes the most recently used block.
- Buffer managers also support forced output of blocks for the purpose of recovery
最好的策略是基于预测的,但是预测本身是很难的,需要利用人工智能的方法。
Clock: An approximation of LRU¶
Arrange block into a cycle, store one reference_bit per block
When pin_count reduces to 0, set reference_bit =1
reference_bit as the 2nd chance bit
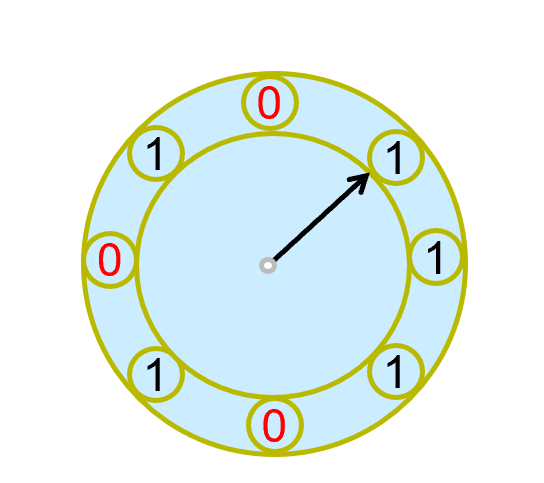
do for each block in cycle {
if (reference_bit ==1)
set reference_bit=0;
else if (reference_bit ==0)
choose this block for replacement;
} until a page is chosen;