使用 PagedAttention 为 LLMs 提供服务的高效内存管理 ¶
约 2777 个字 5 张图片 预计阅读时间 9 分钟
Abstract

- Paper: Efficient Memory Management for Large Language Model Serving with PagedAttention
- SOSP 2023: ACM Symposium on Operating Systems Principles
介绍 ¶
导言 ¶
- 运行大模型很昂贵,需要大量如 GPU 的硬件加速器资源,成本可能很高。因此我们想让 LLM serving system 提高吞吐,从而降低每个请求的平均成本。
-
LLMs 的核心是自回归(autoregressive)的 Transformer 模型,每次生成会基于当前的输入和之前的输出 token 序列。这里我们会缓存 Key 和 Value tensor,这就是 KV cache。
-
在评估 LLM 时由于模型权重是恒定的,并且激活仅占用 GPU 内存的一小部分,因此 KV 缓存的管理方式对于确定最大批处理大小至关重要。当管理效率低下时,KV 缓存会显著限制批处理大小(即一次处理多少个请求
) ,从而限制 LLM 的吞吐量。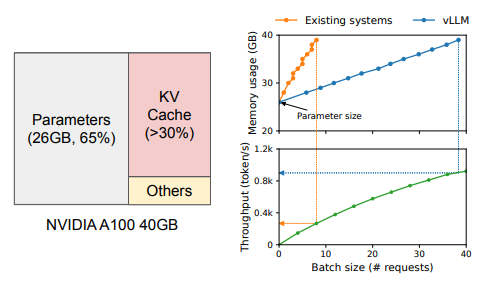
-
-
论文观察到现有的 LLM serving 系统无法有效管理 KV cache。
- 这主要是因为我们在分配 KV cache 时,像传统的 tensor 一样分配连续空间。但是 KV cache 有独特特征:随着模型生成更多的 token,KV cache 会动态增长和缩小,而且他的生存期是未知的。
- 这会导致两个问题:内部和外部碎片;无法利用内存共享的机会。具体分析见后。
- 因此论文提出了 PagedAttention,以像在操作系统的虚拟内存中一样,以更灵活的方式管理 KV 缓存:可以将 blocks 视为 pages,将 tokens 视为 bytes,将 requests 视为 proecesses,贡献如下:
- 确定了服务 LLMs 中内存分配方面的挑战,并量化了它们对服务性能的影响。
- 提出了 PagedAttention
- 设计并实现了 vLLM,一个基于 PagedAttention 的分布式 LLMs 服务引擎。
- 评估了 vLLM 的性能,其性能大大优于之前的 SOTA,比如 FasterTransformer 和 Orca。
- 源代码:https://github.com/vllm-project/vllm
背景 ¶
- 基于 Transformer 的 LLMs
-
LLM 服务与自回归生成
- 一个请求(request)给到 LLM 服务时,会提供一个 input prompt tokens 的列表 \((x_1,\ldots,x_n)\),随后 LLM 服务生成一个 output token 的列表 \((x_{n+1}, \ldots, x_{n+T})\),我们把这两个列表拼接在在一起称为一个序列 sequence。
- LLM 服务的计算可以分为两个阶段:
- prompt phase:将用户的整个 prompt \((x_1,\ldots,x_n)\) 作为输入,计算第一个 token 的概率(即 \(P(x_{n+1}|x_1,\ldots,x_n)\) 得到第一个输出的 token。同时还生成了 n 个 key vecotor \(k_1,\ldots,k_n\) 和 value vector \(v_1,\ldots,v_n\)。整个过程可以通过矩阵乘法来并行计算。
- auto-regressive phase:串行生成剩余的 token。本轮迭代只需要生成 \(k_{n+t}, v_{n+t}\) 即可,其他向量已经被缓存。每次把 \(x_{n+t}\) 作为输入,通过 kv 向量 \(k_1,\ldots,k_{n+t}\) 和 \(v_1,\ldots,v_{n+t}\) 计算下一个 token 的概率(即 \(P(x_{n+t+1}|x_1,\ldots,x_{n+t})\)。这个过程因为有依赖关系,只能用向量 - 矩阵乘法,是 memory-bound。
-
LLMs 的批处理技巧
- 请求共享相同的模型全在,移动权重的开销可以在批处理请求中均摊,当批处理大小足够大时这个开销是可以被计算开销超过的。
- 但是批处理请求存在这样的问题:
- 不同的请求到来时间不同,需要等待。
- 不同请求长度不同,需要填充,这样会浪费 GPU 的计算和内存。
- 为此有细粒度的批处理机制,这些技术在迭代级别运行。每次迭代后,都会从批处理中删除已完成的请求,并添加新的请求。因此,可以在等待单次迭代后处理新请求,而不是等待整个批处理完成。此外,使用特殊的 GPU 内核,这些技术无需填充输入和输出。
算法 ¶
LLM Serving 中的内存挑战 ¶
可以批处理在一起的请求数量仍然受到 GPU 内存容量的限制,即 memory-bound。要克服这个问题,我们需要解决内存管理中的如下挑战:
- KV cache 大
- 随着请求数量变多,KV cache 随之快速增长。e.g. 13B 的 OPT 模型里,单个 token 的会消耗 \(2\times 5120\times 40\times 2=800KB\) 空间(分别代表 key+value,隐藏层维度,层数,fp16 的字节
) ,同时 OPT 模型最大的序列长度是 2048,那么单个请求的 KV cache 就会占用 1.6GB 的空间。那么这样即使 GPU 内存全用来放 KV cache,也只能处理几十个请求。 - 低效的内存管理会进一步减小批处理大小。
- GPU 的计算增长速度快于内存容量的增长速度。
- 随着请求数量变多,KV cache 随之快速增长。e.g. 13B 的 OPT 模型里,单个 token 的会消耗 \(2\times 5120\times 40\times 2=800KB\) 空间(分别代表 key+value,隐藏层维度,层数,fp16 的字节
- 复杂的 decoding 算法
- 解码算法可以有很多种,每种算法对内存管理都有不同的影响和要求。
- KV 缓存共享的程度取决于所采用的特定解码算法。
- 未知的输入输出长度导致的调度
现有系统的内存管理方式
假设有两个请求 A 和 B,A 的最大长度为 2047,B 为 512,那么我们的分配结果如下:

这里会有 reserved slots,用来放接下来要输出的 token;内部碎片,因为预分配的空间大于实际需要的空间;外部碎片,因为两个请求的分配导致中间一段内存不可用。其中内外部碎片都不会再被使用,是 pure memory waste;reserved slots 最终会被用掉,但是保留这段空间可能会持续很长一段时间,而他们本来可以用来服务其他请求,却一直被保留。
方法 ¶
-
PagedAttention
PagedAttention 将每个序列的 KV cache 划分为 KV blocks,每个 block 包含固定数量 token 的 KV cache。于是,原有的 attention 计算将被替换成 block-wise 计算:
\[ \begin{aligned} & a_{ij}=\dfrac{\text{exp}(q_i^\top k_j\sqrt{d})}{\sum_{t=1}^i \text{exp}(q_i^\top k_t/\sqrt d)}, o_i = \sum\limits_{j=1}^i a_{ij}v_j\\ \Rightarrow & A_{ij}=\dfrac{\text{exp}(q_i^\top K_j\sqrt{d})}{\sum_{t=1}^{\lceil i/B\rceil} \text{exp}(q_i^\top K_t/\sqrt d)}, o_i = \sum\limits_{j=1}^{\lceil i/B\rceil} V_{j}A_{ij}^\top \end{aligned} \]这里 \(B\) 表示块大小,\(K_j=(k_{(j-1)B+1},\ldots,k_{jB})\),\(V_j=(v_{(j-1)B+1},\ldots,v_{jB})\),而 \(A_{ij}\) 表示第 j 个 KV block 的 attention score 行向量。
-
KV Cache Manager
- 一个请求的 KV cache 表示为一系列逻辑 KV 块,在生成新 token 时从左到右填充。最后一个 KV 块可能会有没有填充满的位置,用来存放输出的 token。
- 在 GPU worker 上,一个 block engine 分配连续的 GPU DRAM 并切分为物理 KV 块(像 CPU 的 RAM 一样
) 。 - 块管理器还维护一个 block tables,用来记录逻辑 KV 块和物理 KV 块之间的映射关系。
-
Decoding with PagedAttention and vLLM
Example
对于请求 1 有 7 个 tokens,因此我们把前两个逻辑块(0,1)分配他,这里 vLLM 映射了两个物理块(7,1
) 。在 prefill 这一步,vLLM 会生成 prompt 的 KV cache,把前 4 个 token 的 KV cache 放进逻辑块 0,剩下的放进逻辑块 1。随后在第一个自回归解码中,会生成第一个 token,放进逻辑块 1 的最后一个插槽。进行第二次解码时,vLLM 会新分配一个物理块并存储映射。
-
在其他解码场景的应用:
-
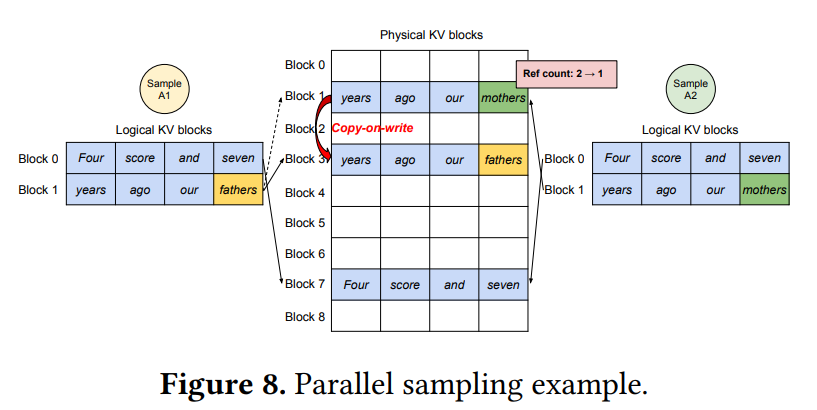
Parallel sampling:对于一个 prompt,LLM 给出多个输出,便于用户选择其中一个。
- 我们可以让输入 prompt 的 KV cache 在多个进程间共享,这样就只需要保存一份内容即可。
- 同时我们需要记录每个物理块的引用计数,当引用计数为 0 时,释放这个物理块。
- vLLM 实现了 copy-on-write 写时复制的方法,当需要修改某个共享的物理块时(如最后一个没有填满 slots 的块,我们要放输出的 token
) ,会先复制这个物理块,修改引用技术,然后写在新的块上。
-
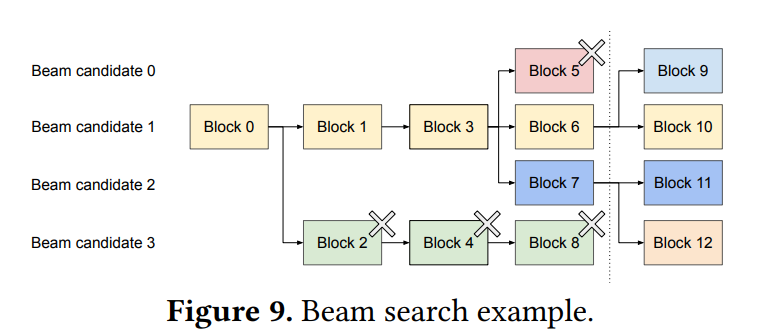
Beam search:每次迭代只保留 top-k 个候选序列。beam search 不仅共享 prompt 的 KV cache,还会共享不同候选序列之间的其他块(即公共前缀的 KV cache blocks
) 。 -
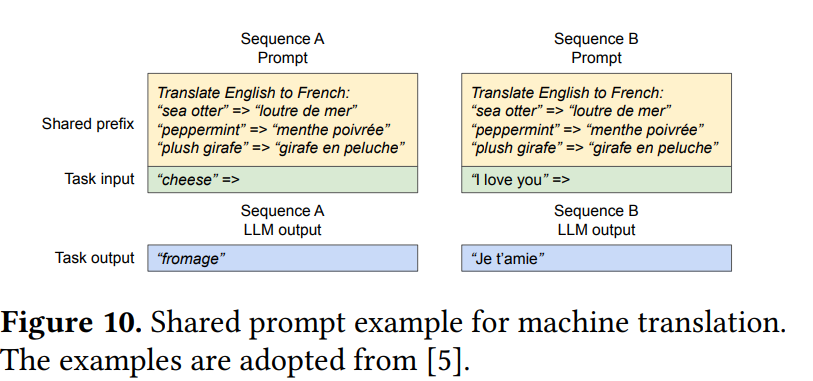
Shared prefix:通常 LLM 都会为用户提供 system prompt,用以对任务的描述。
-
-
Scheduling and Preemption
- 在 vLLM 里,我们采用 first-come-first-serve (FCFS) 的调度策略来处理请求,这样可以保证公平避免 starvation。
- LLM 服务有一个独特的挑战:输入和输出的长度都是未知的,这意味着可能用光 GPU 的物理内存。因此我们需要回答:踢出哪个块?如果被踢出的块还有用我们应该如何恢复?
- vLLM 采用的策略是,对于一个 sequence 的所有块,采用 all-or-nothing 策略,要么全部赶出去要么全部保留。进一步地,单请求多序列的情况也可以被组织安排为一个序列组。
-
对于第二个问题,我们可以使用 Swapping / Recomputation 的做法。交换和重新计算的性能取决于 CPU RAM 和 GPU 内存之间的带宽以及 GPU 的计算能力。
-
Swapping: 当一个块被踢出时,我们会把这个块的内容写到 CPU 的 DRAM 上。
当 vLLM 用光所有自由的物理块时,它会选择驱逐一个序列的集合并把他们的 KV cache 转移到 CPU。一旦它抢占一个序列,vLLM 会停止接受新的请求直到所有被抢占的序列完成。当有请求完成时它的所有块都被释放,这时可以把被抢占的序列搬回来继续执行。
-
Recomputation: 当被抢占的序列被重新调度时,我们会重新计算这个序列的 KV cache。
-
-
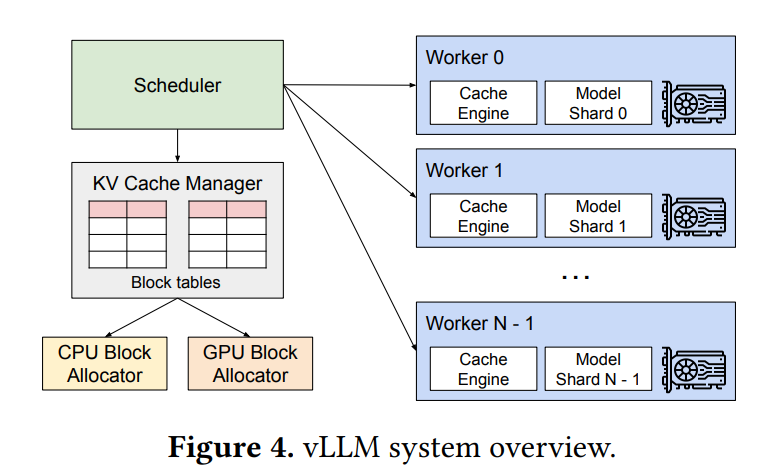
Distributed Execution
- 不同 GPU worker 共享一个 KV cache 管理器。
- 每轮迭代 scheduler 首先为批处理中的每个请求准备带有输入令牌 ID 的消息,以及每个请求的块表。接下来,调度程序将此控制消息广播给 GPU 工作线程。然后,GPU 工作线程开始使用输入令牌 ID 执行模型。在注意力层中,GPU 工作人员根据控制消息中的块表读取 KV 缓存。在执行过程中,GPU 工作线程将中间结果与 all-reduce 同步,而无需调度程序的协调。最后,GPU 工作线程将此迭代的采样令牌发送回调度程序。
{kind=link}
{kind=link}
{kind=link}
实现 ¶
vLLM 是一个端到端的服务系统,具有 FastAPI 前端和基于 GPU 的推理引擎。
- 内核级优化:融合 reshape 和块写入,融合块读取和 attention,融合块复制。
- 支持多种解码算法,提供了
fork,append,free三个方法,用来创建新序列、将新的 token 添加到已有序列、释放序列。