ZeRO: 为训练万亿参数模型而进行的内存优化 ¶
约 2796 个字 7 张图片 预计阅读时间 9 分钟
Abstract

- Paper: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- SC '20: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
- 本文中的图片均来自知乎文章
如何将数据并行运用到大型神经网络
思想:一个模型你大到一个计算单元放不下时,就把完整的模型分布式存在某个地方。计算时再取出来。
介绍 ¶
摘要 ¶
摘要中提到,零冗余优化器(Zero Redundancy Optimizer,ZeRO)用于优化内存,
- ZeRO 有潜力达到一万亿参数(不是真正达到
) 。 - 实验中发现它能在 400 个 GPU 上以超线性速度训练超过 100B 参数的大型模型。
- 可以训练 13B(130 亿)参数模型,且不需要模型并行。
- 研究人员利用 ZeRO 在系统方面的突破,创建了世界上最大的语言模型(17B 参数
) ,其准确性打破了记录。
背景 ¶
模型变大,无法容纳在单个设备(如 GPU 或 TPU)的内存中。数据并行(DP)并不能减少每台设备的内存,其他现有的解决方案有管道并行(PP
这里最好的是 MP(本论文提到的模型并行都指的是 Megatron-LM
Note
Megatron 论文说只能做到 8.3B,这篇论文称使用 Megatron 可以做到 40B,具体如何做到无从得知。
内存用在什么地方,具体的内存分析课见第二部分
- Model State ( 模型状态 ):Optimizer States 优化器状态、Gradients 和 Parameters
- Residual State ( 残余状态 ):Activations 中间值、Temporary buffers 临时缓存、内存碎片
本论文为了优化模型状态内存,提出了 ZeRO-DP;为了优化残余状态,提出了 ZeRO-R,二者合在一起就是 ZeRO。
内存分析 ¶
模型状态 ¶
这里以 Adam 优化器为例,对于每一个可训练的参数 \(w\),我们要维护一个动量和方差。
Mixed-Precision Training 混精度训练
在混精度下会有这样的问题:Nvidia 在半精度(fp16)计算更快,因此模型训练时通常使用半精度。
具体指我们在训练这个层的参数 \(w\) 时,\(w\) 和这个层的输入、输出都是 fp16。如全连接层,\(w*x=y\),那么这里 \(w,x,y\) 的精度都是 fp16。
但是 fp16 精度不够,在累计权重时会有问题。因此权重更新时使用的是 fp32,即权重有一个 fp32 的复制。更新后再将将其转为 fp16,用于前向和后向计算。
如果模型有 \(\phi\) 个可以学习的参数,那么 fp16 需要 \(2\phi\) bytes 存参数,\(2\phi\) bytes 存梯度。fp32 需要存 \(w\) 和他在 Adam 中的状态,即 \(3*4\phi = 12\phi\) bytes,即此时总共需要 \(2\phi+2\phi+12\phi=16\phi\) bytes 的内存来存储模型。e.g. GPT-2 模型有 1.5B 参数,仅保存参数只需要 3GB 内存,但是实际上至少需要 24GB 内存。
残余状态 ¶
-
Activations
前向时,要保留中间结果,后向要用。线性关系。e.g. GPT-2 模型有 1.5B 参数,如果 batch 取 32,序列长度取 1K,那么需要 60GB 的内存来存中间结果。可以使用 checkpointing 激活检查点的方法来优化。但对于较大的模型,即使使用激活检查点功能,激活内存也会变得相当大。
-
Temporary buffers
当模型大小很大时,由于某些操作 / 高性能库的原因,会等待装填或者分配一个非常大的融合缓冲区去执行操作,这虽然会带来带宽和效率上的优势,但是有时却成为了内存瓶颈。
-
Memory Fragmentation
GPU 没有虚拟内存,会出现中间变量、内存碎片。tensorflow 不会有内存碎片这个问题,因为他提前知道整个程序的运行,可以自适应分配,尽可能减少碎片。Pytorch 会有。
论文里提到最坏情况下,有 30% 的内存因为碎片无法使用。
ZeRO¶
ZeRO-DP¶
Insight:
- DP 比 MP 效率高。
- DP 对内存不有效,因为每个地方要保存整个模型。
- DP、MP 都要维护参数对应的中间状态,不是很高效。
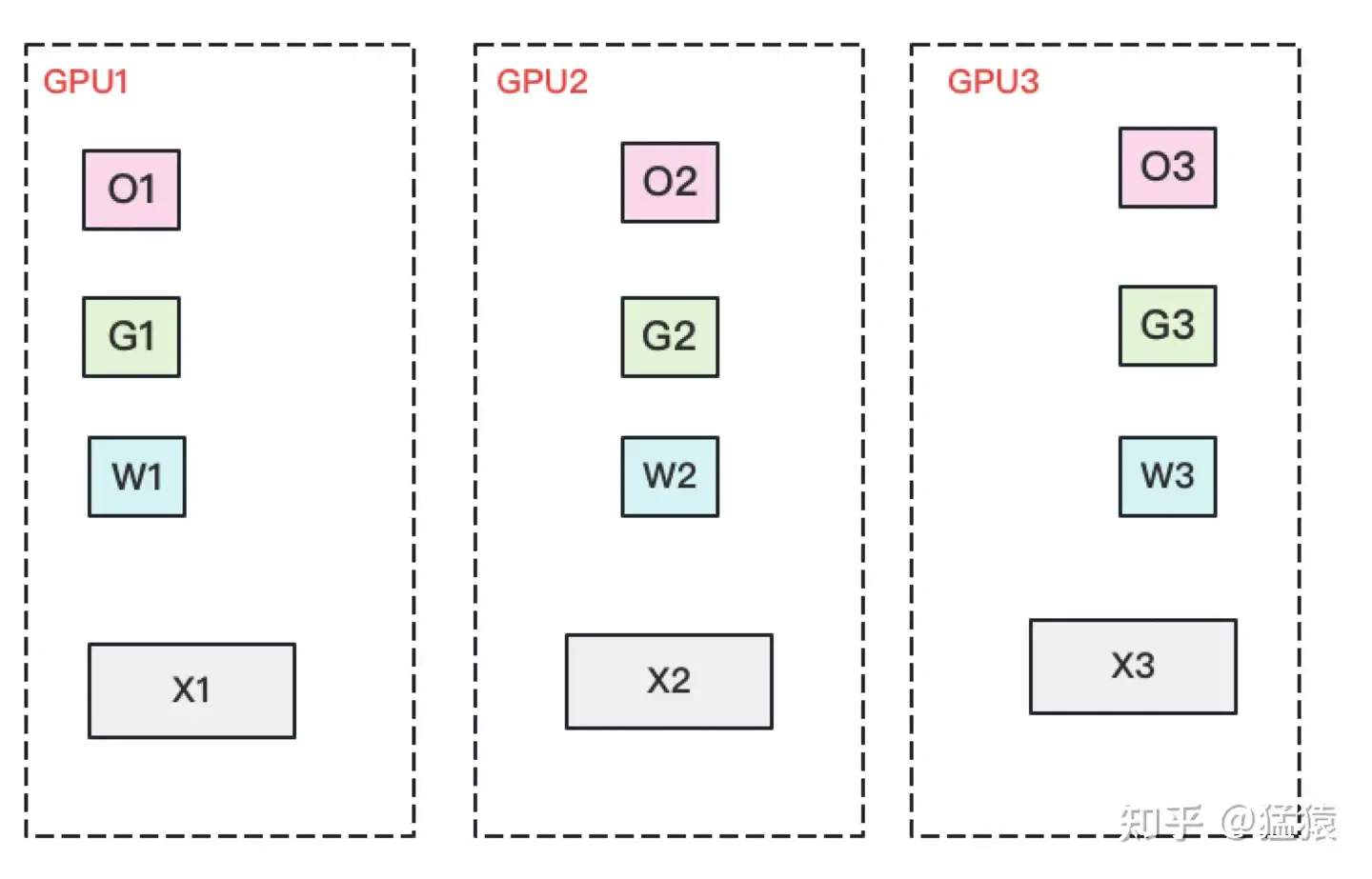
思想:模型状态在多个 GPU 上有重复的拷贝,我们可以只存一份,下次要用时向这个 GPU 要即可
具体来说,ZeRO-DP 有下面三个部分
-
\(P_{os}\) (ZeRO-1)
对优化器状态进行分割,每个并行进程只保存 \(12 \phi / N_d\) 的优化器状态,并只更新对应的参数。每轮训练中,前向和后向传递结束后,通过 reduce-scatter 让每个进程都获得对应优化器状态部分的合并梯度,更新对应参数,最后对所有数据并行进程进行 all-gather,以获全部更新后的参数。

此时单卡通信量为 \(\phi(reduce-scatter)+\phi(all-gather)=2\phi\).
-
\(P_{os+g}\) (ZeRO-2)
对梯度进行分割,每个并行进程只保存 \(2\phi / N_d\) 的梯度。每轮训练中,前向和后向传递结束后每个进程都得到的是完整梯度,通过 reduce-scatter 让每个进程都获得对应梯度部分的合并梯度,其他的梯度都丢掉,随后更新对应参数,最后对所有数据并行进程进行 all-gather,以获全部更新后的参数。
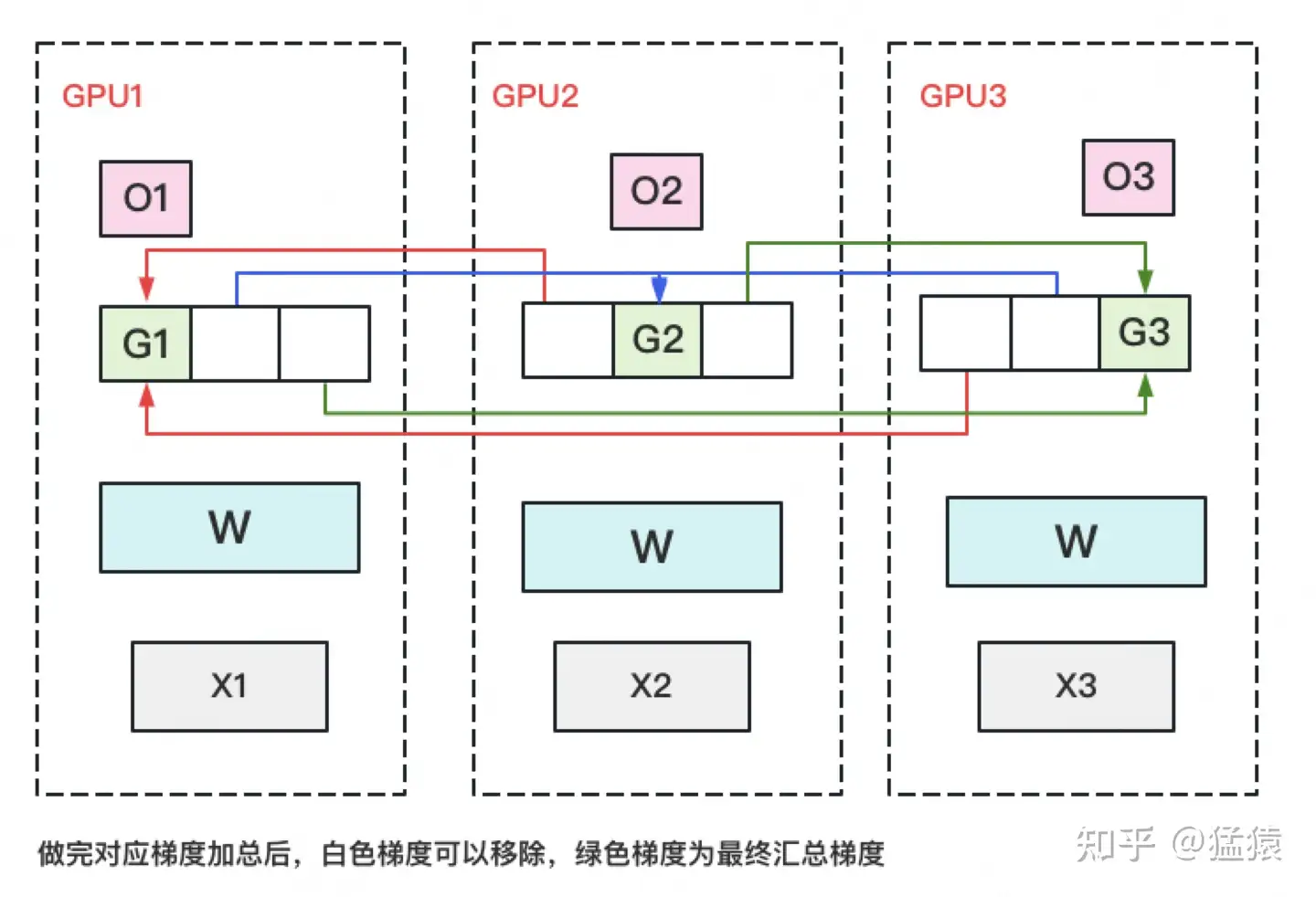
此时单卡通信量为 \(\phi(reduce-scatter)+\phi(all-gather)=2\phi\).
-
\(P_{ps+g+p}\) (ZeRO-3)
对参数进行分割,每个并行进程只保存 \(2\phi / N_d\) 的参数。每轮训练中,在 forward 时,对参数做 all-gather,forward 结束丢掉其他参数;在 backward 时同理,对参数做 all-gather。前向和后向结束后得到完整的梯度,做 reduce-scatter,更新对应参数,随后抛弃其他部分的梯度,最后不需要再做 all-gather(因为本来就只维护一部分参数
) 。此时单卡通信量为 \(\phi(reduce-scatter)+2*\phi(all-gather)=3\phi\).
可以看到,ZeRO-1/ZeRO-2 不会带来额外的通信量,而 ZeRO-3 的通信量是朴素 DP 的 1.5 倍。
ZeRO-DP 中不同优化的每设备内存消耗量:
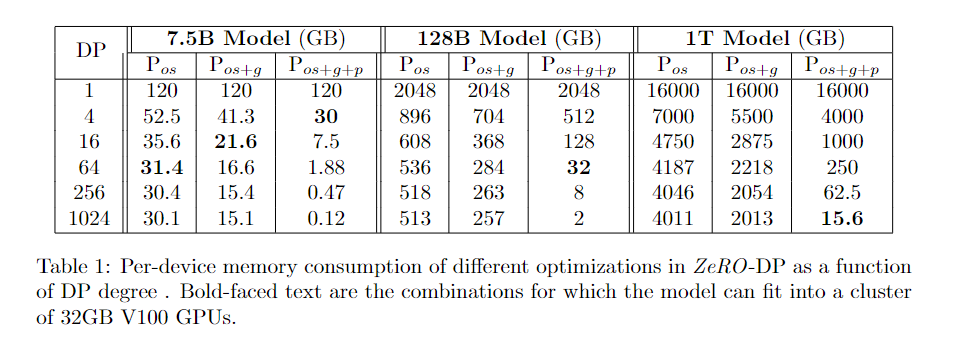
黑体表示能放到一张卡内(32GB V100 GPUs
ZeRO-R¶
具体来说:
-
\(P_a\)
Megatron-LM 每层的 Activations Memory 都对每个 GPU 复制了一份。可以把它切成很多块,每个 GPU 保存一部分,一旦计算出模型层的前向传播,输入 Activation 就会在所有 MP 进程中进行分区,直到在反向传播期间再次需要太时,我们进行 all-gather 操作
。 (类似于 activation 重算) ,这里是用带宽来换空间,区别在于不是真的重算,只是存在不同地方。此外,在模型非常大、设备内存非常有限的情况下,这些分区激活检查点也可以卸载到 CPU,从而将激活内存开销降至几乎为零,但需要额外的通信成本。
-
\(C_B\)
开一个固定大小的 buffer,用的时候分配,不用的时候拿掉(常见优化
) 。填满了再把里面的内容发出去,这样可以有效地利用带宽。类似于网络中的思想,我们可以算一个超时,如果指定时间内没有把缓冲区填满,就把 buffer 缩小。
-
\(M_D\)
内存碎片有 short-lived,有 long-lived,做内存整理。一直要维护的张量放在一起,其他的内存可以随时分配、析构。
在基于 Megatron-LM 的模型并行中,每个 transformer 块需要 \(12\times seq\_length \times hidden\_dim\) 的通信量,这是因为它在前向传播、前向重新计算和反向传播中各有两次 all-reduce 操作,每次操作的通信量是消息大小的两倍,即 \(2\phi\)。使用了 \(P_a\) 技术后,每次 Activation Checkpoints 需要一个额外的 all-reduce 操作,增加了 \(seq\_length \times hidden\_dim\) 的通信量。
此外,当 MP 和 DP 一起使用时,\(P_a\) 的引入能够允许更大的 batch size,这反过来可以将数据并行的通信量减少一个数量级。
我们还可以通过 \(P_{a+cpu}\) 将激活检查点卸载到 CPU,从而将激活内存需求降至几乎为零,但与 \(P_a\) 相比,CPU 内存间的数据移动量增加了 2 倍。
实验 ¶
实验环境:
- ZeRO-100B(参数有 170B 的模型)
- 硬件:25 个 DGX-2,400 块 V100 GPU,连接是 100GBps
- baseline: Megatron-LM
结果如图:

当达到 40 billion 参数时,Megatron 需要跨机器做模型并行,需要做大量的通讯,可以看到 baseline 很低(不能算很好的 baseline,因为别人本身不是这么设计的)
超线性增长:

卡增多,可以把模型分到更多的卡上,每台机器拿到的 batch 变大,好处:每块卡每次运算的矩阵变大了(能更好地使用单机 GPU 的核
需要注意的是测性能和真正训练模型是不同的,论文里提到只训练了 17B 参数的模型,前面说的 170B 的模型只是用来测性能。
结论和评论 ¶
论文中可以看到 ZeRO 算法相对比较简单,每次 all reduced 时不需要把结果 reduce 到所有 GPU 上,而是每个 GPU 负责自己的一块,只维护自己的。当需要用到完整的数据时,再重新发送得到完整数据。用通讯换内存。
个人的评论如下
- 这篇的写作比较啰嗦,第一节过于简单和跳跃,后面的内容比较慢,读起来费力。反复提到了 Megatron 这篇文章,但没有提 Megatron 到底是什么技术。
- 虽然论文声称 ZeRO 是一个革命性的新技术,但实际上核心思想是很简单的,而且从以前的论文、实践中也能看到类似的思想。同时在计算机网络、分布式系统里面也有类似的处理。
- 论文依然是系统领域经典的思路:做一个系统能做多大,训练一个更大的模型精度更好。
参考资料 ¶
- Mu Li 的 b 站视频“Zero 论文精读”。
- 知乎文章“ZeRO: Zero Redundancy Optimizer,一篇就够了
。 ”,对本篇论文分析,附录介绍了几种常见的通信方式(all-gather, all-reduce, reduce-scatter) 。 - 知乎文章“数据并行上篇 (DP, DDP 与 ZeRO)”,有对 Ring-AllReduce 的分析。
- 知乎文章“数据并行下篇 ( DeepSpeed ZeRO,零冗余优化 )”。