Transformer and LLM¶
约 4390 个字 48 张图片 预计阅读时间 15 分钟
Abstract
- Transformer basics
- Transformer design variants
- Large language models (LLMs)
- Efficient inference algorithms for LLMs
- Quantization: SmoothQuant, AWQ, TinyChat
- Pruning/sparsity: SpAtten, H2O, MoE
- Efficient inference systems for LLMs
- vLLM
- StreamingLLM
- FlashAttention
- Speculative decoding
- Efficient fine-tuning for LLMs
- LoRA/QLoRA
- Adapter
- Prompt Tuning
Transformer Basics¶
Revist: NLP Tasks¶
-
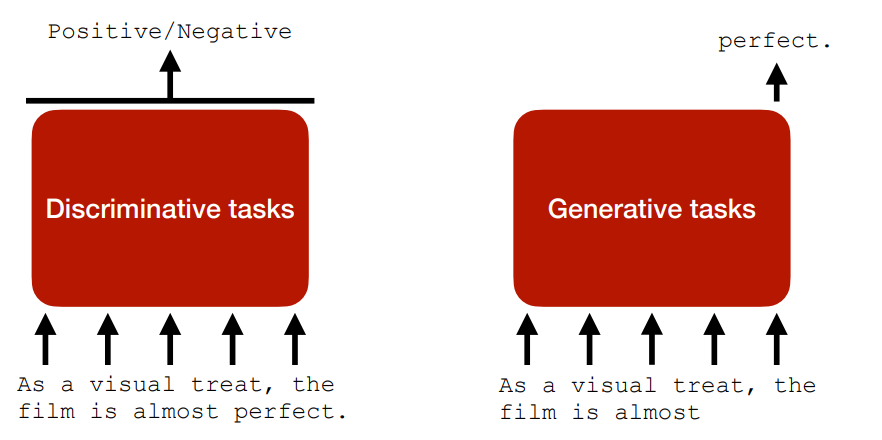
NLP 里主要有两类任务:
- Discriminative tasks 判别任务,比如文本分类、命名实体识别、情感分析等。
- Generative tasks 生成任务,比如机器翻译、文本摘要、对话生成等。
-
在 Transformer 出来之前,常用的模型有:
-
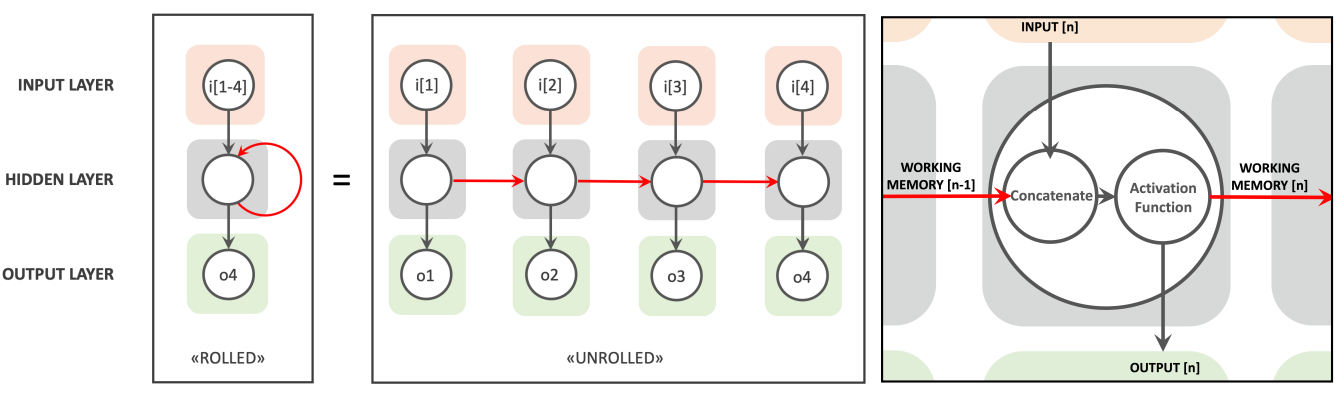
Recurrent Neural Networks (RNNs)
- 当前的状态依赖于输入和之前的状态,因此存在 cross-token 的依赖,限制了他的 scalability。
- work memory 努力保持 long-term dependencies(可以由 LSTM 解决
) 。
-
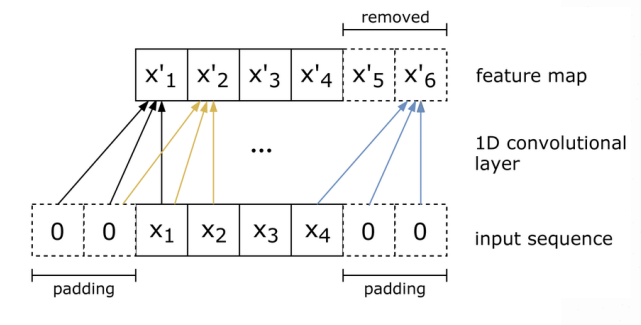
Convolutional Neural Networks (CNNs)
- tokens 之间不存在依赖,因此有更好的 scalability。
- 但限制了上下文信息,导致模型的能力不如 RNN
。 (因为 CV 中信息往往都具有局部性,但是 NLP 的任务不一定具有这个特点)
-
NLP with RNN/LSTM
- Bi-directional RNNs 用来做判别任务(encoding
) 。双向体现在可以同时看到以前和未来位置的信息,相当于离线处理。 - Uni-directional RNNs 用来做生成任务(decoding
) 。单向体现在只能看到以前的信息,相当于在线处理。
- Bi-directional RNNs 用来做判别任务(encoding
- Problems with RNN/LSTM
- 难以建模长期的关系,需要 \(O(seq\_len)\) 步才能建立两个 tokens 间的相互联系。
- 训练时的并行性差,因为状态总是严格依赖于之前的状态,需要 n 步才能到达状态 n。
-
Transformer¶
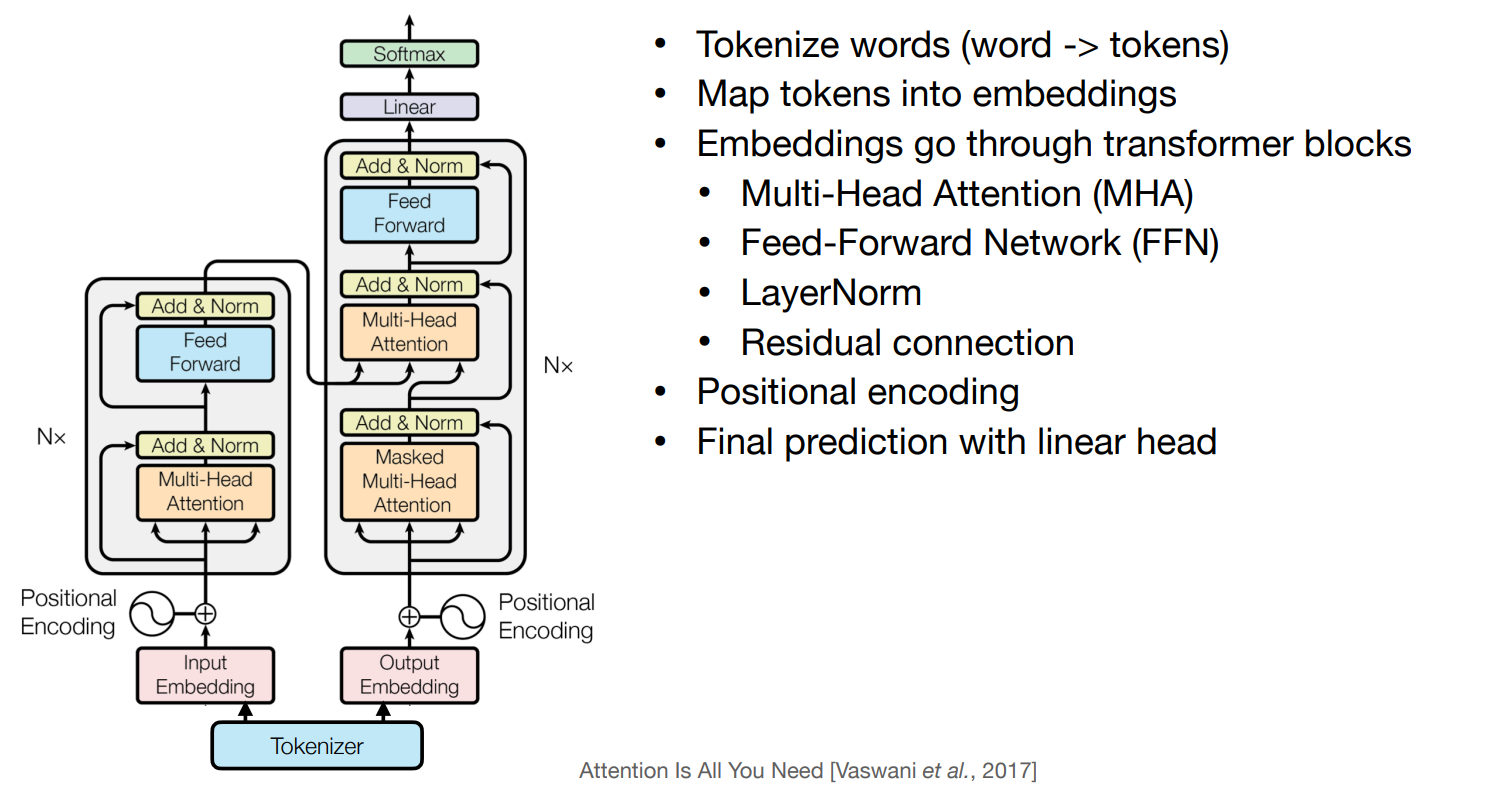
-
Tokenization
- A tokenizer maps a word to one/multiple tokens.
Example
如下图,把 110 个单词划分为了 162 个 tokens。

-
Word Representation
- One-Hot Encoding
- 一个词被表示为一个长度为词典大小的向量,只有一个位置为 1,其余为 0。
- 但是对于大词典,向量可能会变得非常长,而且除了一个地方其余位置全是 0,这被认为是一种非常稀疏的表示方法。
-
Word Embedding
-
把单词的索引,通过一个 look-up table 映射到一个连续的词嵌入。即我们可以把一个单词就看做一个向量。
Example

-
词嵌入可以 end-to-end 进行训练,来适配对应模型的下游任务。流行的预训练的词嵌入有 Word2Vec, GloVe。
-
- One-Hot Encoding
-
Multi-Head Attention(MHA)
-
Self-Attention: \(Attention(Q,K,V)=Softmax(\frac{QK^\top}{\sqrt{d_k}})V\)
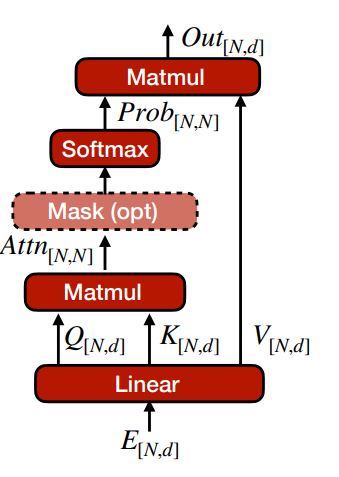
- 首先把嵌入 \(E\) 投影为 query, key, value \((Q,K,V)\)。
- 将 \(Q,K\) 乘起来得到内积,并除以 \(\sqrt{d_k}\) 来规格化。
- 经过 softmax 来得到 \(N\times N\) 的 attention 权重(attention 计算的复杂度是 \(O(N^2)\)
) 。- softmax 是为了将权重视为概率,使得权重和为 1。
- 最后将 attention weights 与 \(V\) 相乘得到输出。
Example
(Q, K, V) 可以类比于一个 Youtube 搜索的过程:Query 是我们在搜索框输入的内容,Key 是 Youtube 上所有视频的标题或者描述,Value 是对应的视频。我们通过 Query 和 Key 的相似度来计算出每个视频的权重,最后将权重和视频相乘得到最终的输出。
-
MHA: Each head captures different semantics
- 我们需要不同的注意力映射来捕捉不同的语义关系,因此我们使用了多头注意力机制。
-
模型有 \(H>1\) attention heads(\(QKV\) 的并行分支
) ,最终结果由不同的注意力结果拼接而成。\[ \begin{aligned} MultiHead(Q,K,V) & =Concat(head_1, /ldots, head_h)W^O\\ where\ head_i & =Attention(QW_i^Q,KW_i^K,VW_i^V) \end{aligned} \]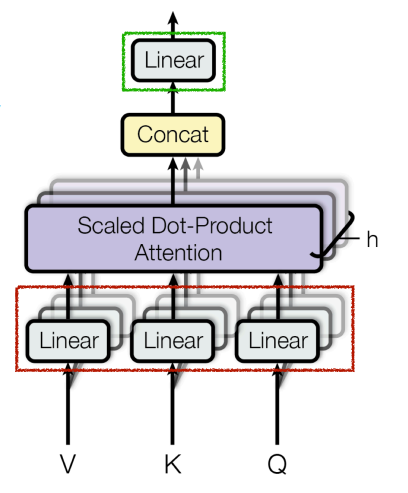
-
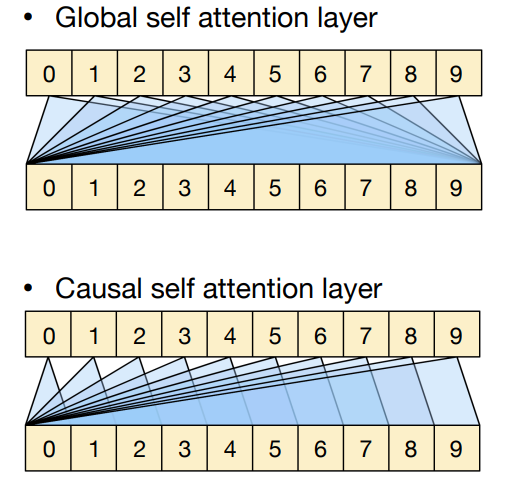
Attention Masking
有 global/causal 两种 mask,其中 global 能看到前后的值,但是 causal 只能看到之前的值。
-
-
Feed-Forward Network (FFN)
- 自注意力只建立了 tokens 之间的关系,没有涉及到 elementwise non-linearity.
- 因此我们添加了一个前馈神经网络来帮助特征的建模。
-
朴素实现就是一个 2 层 MLP(隐藏状态维度更大)以及使用 ReLU/GeLU 作为激活函数。
\[ FFN(x)=ReLU(xW_1+b_1)W_2+b_2 \]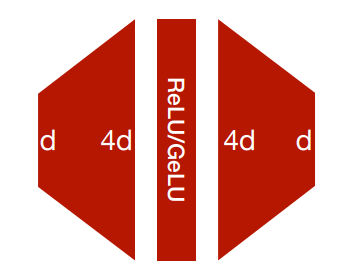
-
LayerNorm & Residual connection
-
Layer Normalization(LN) 对每个 token 进行规范化,随后作用仿射变化
。 (BatchNorm 会对整个 batch 进行规范化)\[ LN(x)=\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}*\gamma+\beta \]这里的放射变化的参数是可学习的。
-
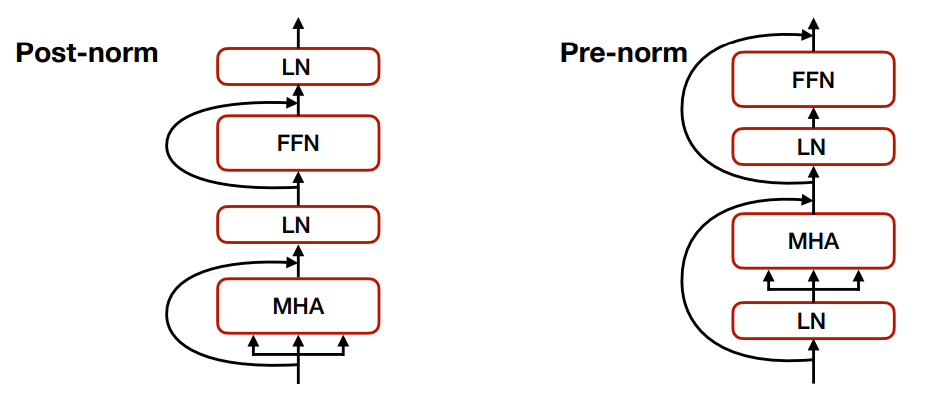
Transformer Block
- 我们会添加 LayerNorm 和 Residual Connections 来促进训练的稳定性。
-
有两种放置方法:Post-norm 和 Pre-norm,现在更多地使用 Pre-norm。
-
-
Positional Encoding (PE)
- 问题:attention 和 FFN 并没有区分输入 token 的次序,即将输入 token 打乱顺序后得到的结果是一样的。相当于我们只是对 set encoding 而非 sequence encoding。
-
解决方法:位置编码,即为每个 token 添加一个位置信息。
-
每个单词的在句子中的位置都有一个独一无二的 encoding。
\[ \vec{p_t}^{(i)} = f(t)^{(i)} := \begin{cases} \sin(w_k\cdot t) & \text{if $i=2k$} \\ \cos(w_k\cdot t) & \text{if $i=2k+1$} \end{cases}, w_k=(10000^{2k/d}) \] -
我们将位置编码和词嵌入相加,得到最终的输入。
-
Transformer Design Variants¶
- 大部分从最初的 transformer paper 中的设计都已经被社区广泛使用。
- 但是,有一些变种的 transformer 也被提出:
- Encoder-decoder(T5), encoder-only(BERT), decoder-only(GPT)
- Absolute positional encoding => Relative positional encoding
- KV cache optimizations
- Multi-Head Attention (MHA) -> Multi-Query Attention (MQA) -> Grouped-Query Attention (GQA)
- FFN -> GLU (gated linear unit)
Encoder & Decoder¶
-
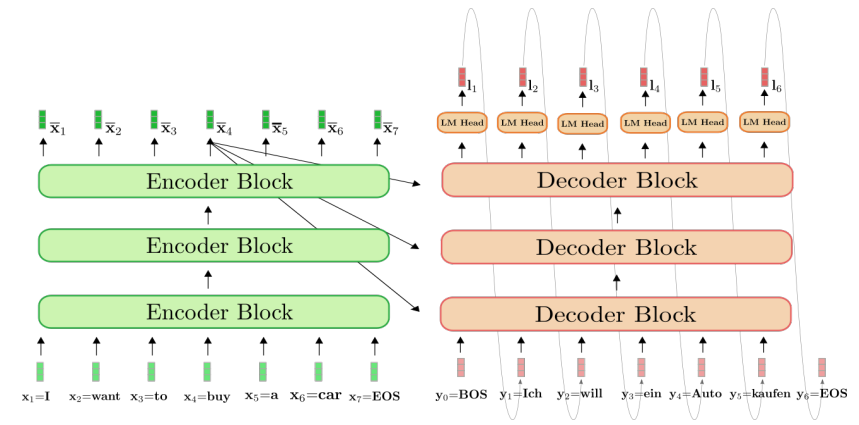
Encoder-Decoder
- 原始的 transformer 就是一个 Encoder-Decoder 结构。
- T5 提供了一个统一的 text-to-text 的模型,可以在不同的 NLP 任务上进行迁移学习。
-
prompt 会被送到 encoder 中,decoder 会生成答案。
-
Encoder-Only (BERT)
- Bidirectional Encoder Representations from Transformers (BERT) 是一个 encoder-only 的预训练模型。
- 有两个预训练任务:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。MLM 类似于完形填空,即通过看上下文来决定被 mask 的词是什么;NSP 是判断两个句子是否是连续的。
- 预训练模型通过 fine-tune 来适配对应的下游任务。

-
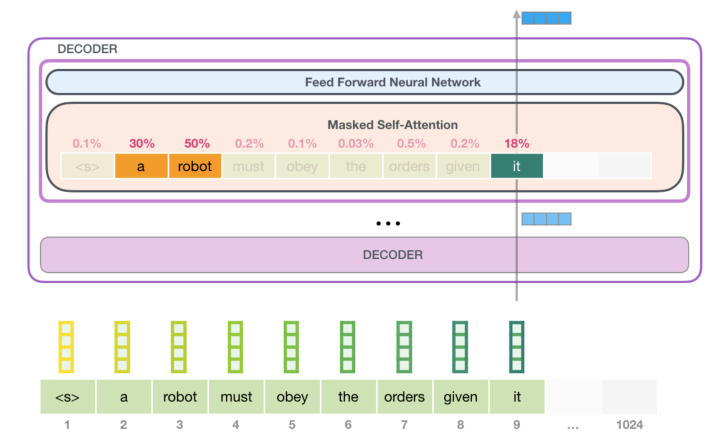
Decoder-only (GPT)
- Generative Pre-trained Transformer (GPT) 是一个 decoder-only 的预训练模型。
- 预训练的目标是 Next word prediction,即给定前面的词,预测下一个词。
- 对于小模型(比如 GPT-2
) ,预训练模型需要通过 fine-tune 来适配对应的下游任务。更大的模型可以 zero-shot/few-shot 适配下游任务,不再需要微调。
Positional Encoding¶
- Absolute Positional Encoding
- 绝对位置编码把位置信息直接加到词嵌入上,因此会同时影响 Q K V,整个模型里面都会有位置信息。
- Relative Positional Encoding
- 相对位置编码将位置信息加到 attention score 上,因此只会影响 Q K,不会影响 V。好处是可以更好地泛化序列长度,即 train short, test long.
-
Attention with Linear Biases (ALiBi)
-
使用相对距离来代替绝对的索引。将偏移量加到 attention matrix 上,再做 softmax 操作并与 V 相乘。
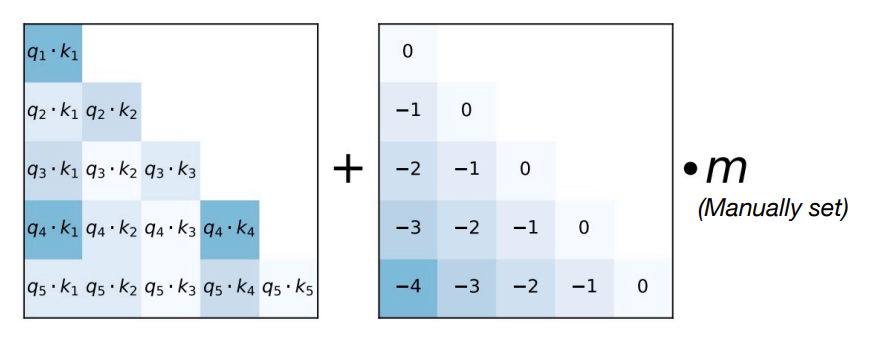
-
Rotary Positional Embedding (RoPE)
-
把 embedding 在 2D 空间里旋转:首先将 \(d\) 维的 embedding 分为 \(d/2\) 对,每对认为是一个 2D 的坐标。随后根据位置 \(m\) 将这个坐标旋转 \(m\theta\) 度。
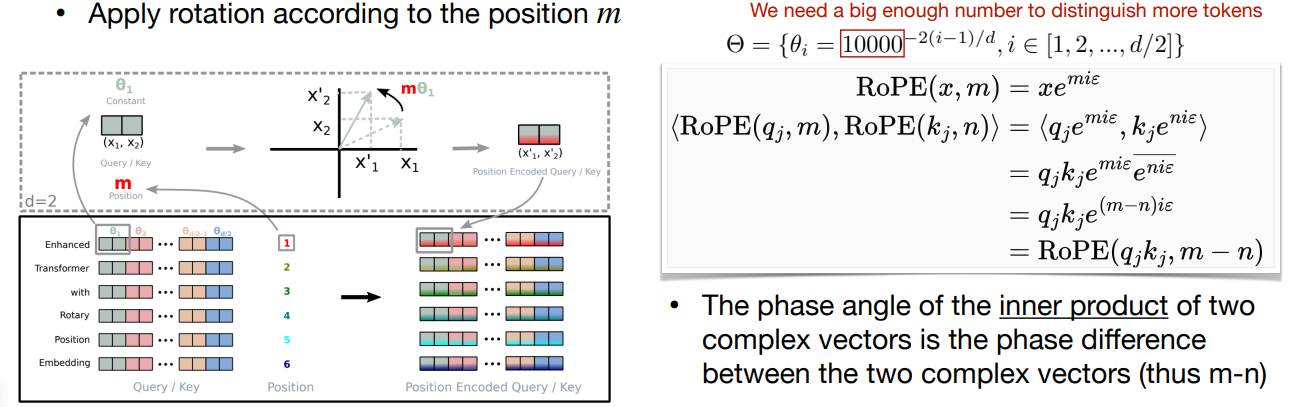
-
一般形式可以写作:

-
好处是 LLM 通常训练时都有上下文长度的限制 e.g. 2k for LLaMA, 4k for LLaMA-2, 8k for GPT-4. 我们可以延长上下文长度,通过插值 RoPE PE 来实现
。 (即使用更小的 \(\theta_i\))Extend the context length of LLaMA from 2k to 32k
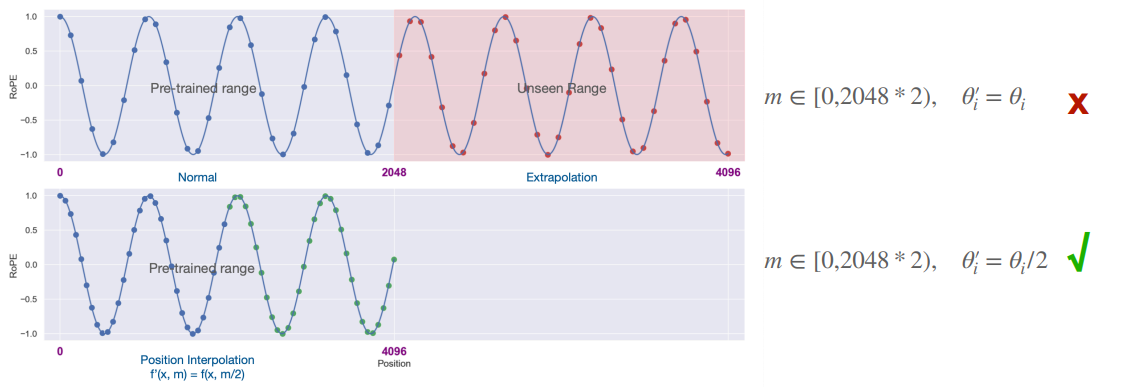
-
-
KV Cache Optimizations¶
-
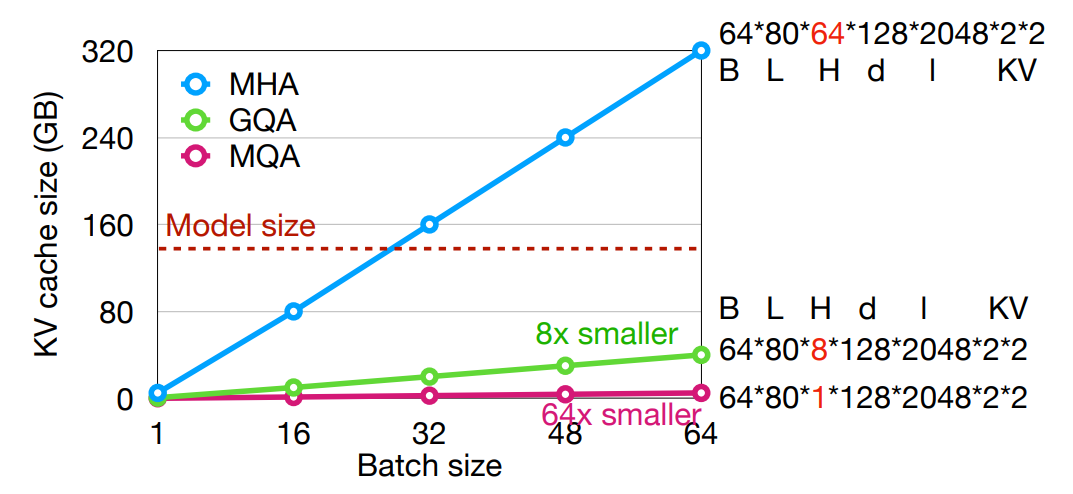
The KV cache could be large with long context.
- 在 transformer decoding 中,我们需要存储所有之前 tokens 的 key 和 value,以此来计算 attention,这就是 KV cache。
-
随着上下文长度的增加,KV cache 会变得非常大,因此我们需要一些优化来减少存储空间。
Example

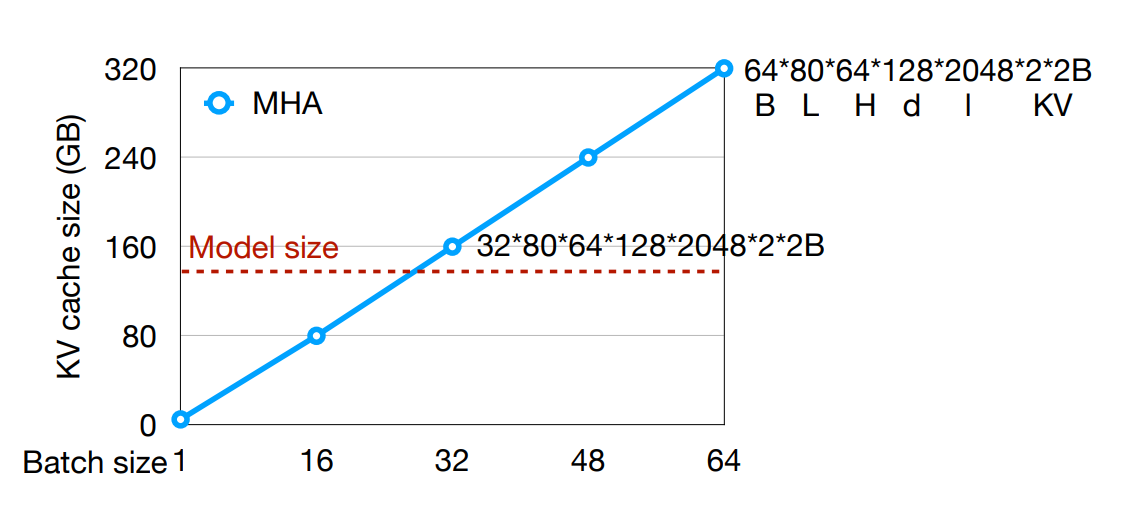
-
Multi-Query Attention
- 通过减少
#kv-heads来降低 KV cache 的大小。 - Multi-head attention (MHA): \(N\) heads for query, \(N\) heads for key/value
- Multi-query attention (MQA): \(N\) heads for query, 1 heads for key/value
- Grouped-query attention (GQA): \(N\) heads for query, \(G\) heads for key/value (typically \(G=N/8\))
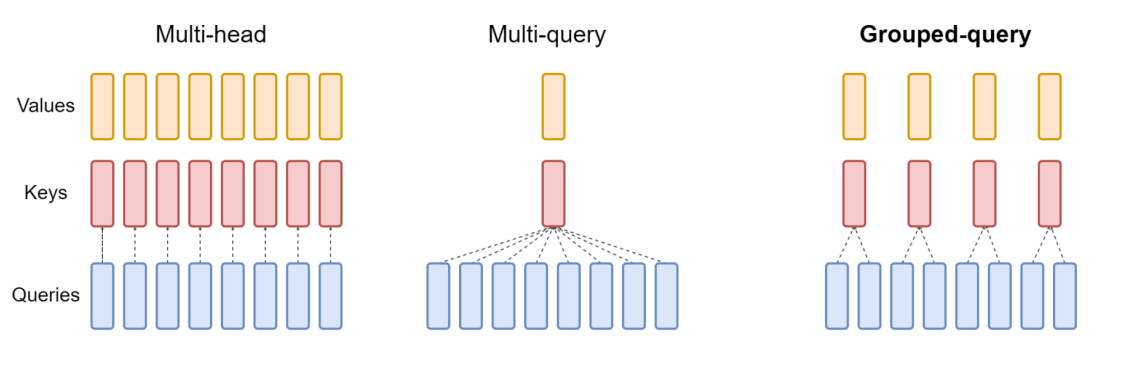
- 通过减少
Improving over FFN¶
-
Gated Linear Units (GLU)
-
我们可以使用 GLU 代替朴素的 FFN,以此来提高模型的性能。
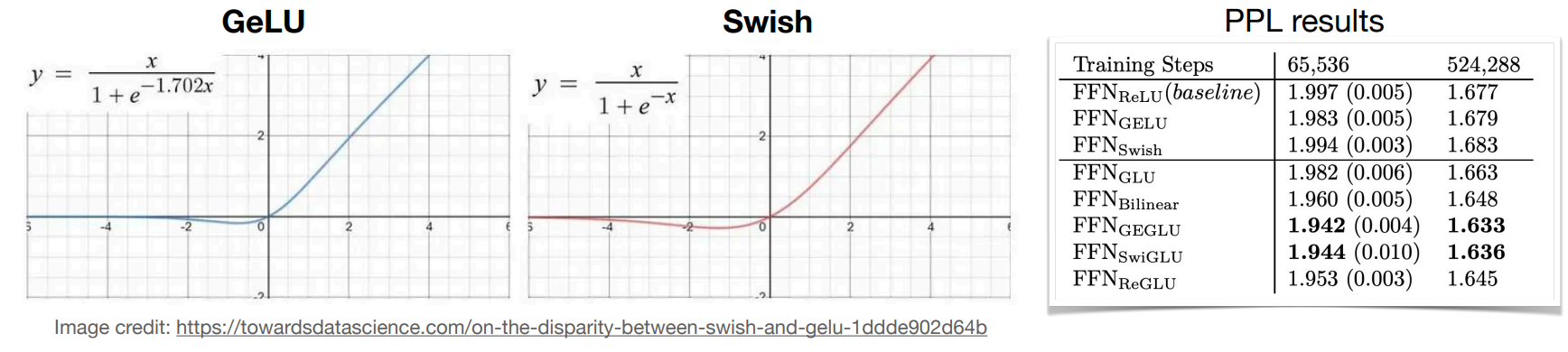
\[ FFN_{SwiGLU}(x,W,V,W_2)=(Swish_1(xW)\otimes xV)W_2 \]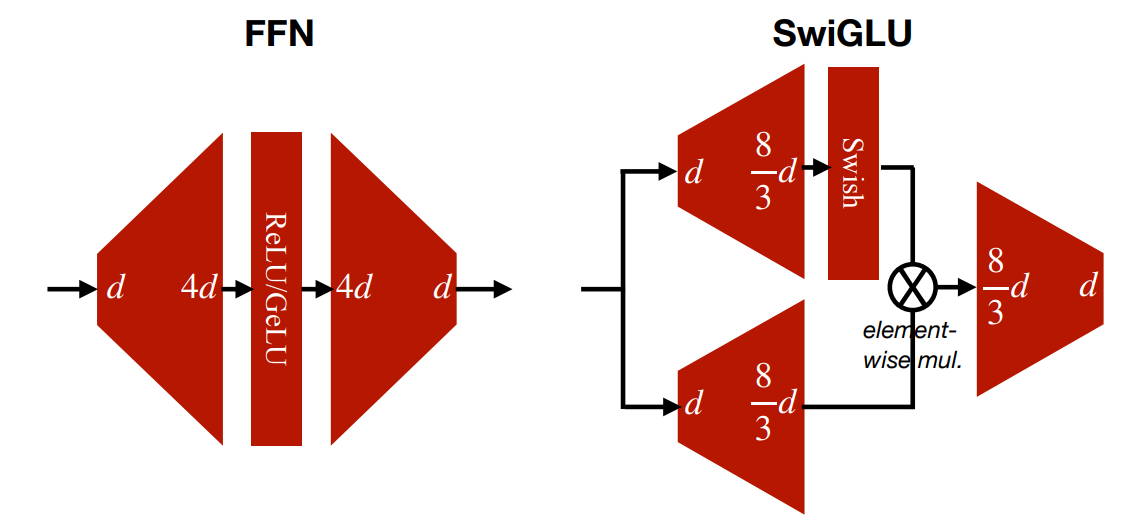
-
其中 Swish 的定义为:\(Swish(x)=x\cdot sigmoid(x)\)
-
Large language models (LLMs)¶
-
LLMs 表现出一些只有在足够大的模型下才能获得的突现能力。

上面图中可以看到,在 size 超过 \(10^{22}\) 后,LLMs 在 Modified arithmetic 等任务上的准确度显著提升。
-
GPT-3
- 将 transformer 扩展为 few-shot learners (in-context learning). 传统的 NLP pipeline 是先预训练,随后对下游任务进行微调。而 GPT-3 可以直接在下游任务上进行学习,不再需要微调。
-
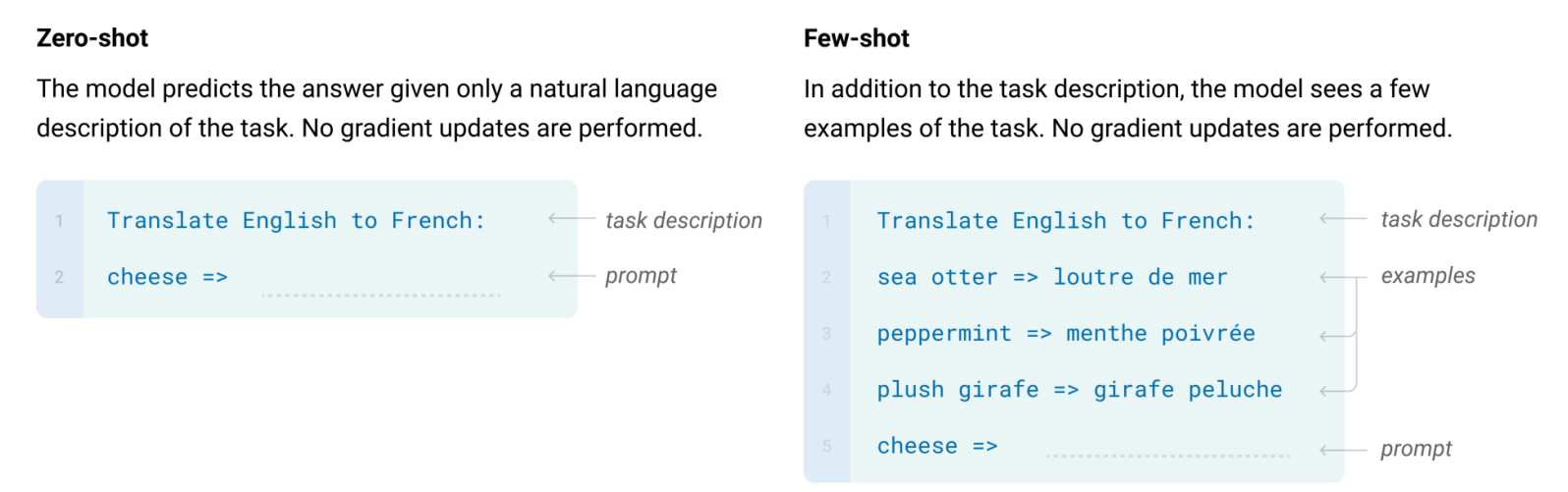
Scaled-up LLM (175B) 可以泛化到新的任务,通过 zero/few-shot:
- Zero-shot: 给定任务描述,回答问题。
- Few-shot: 给定 demonstrations 示范,回答问题。
-
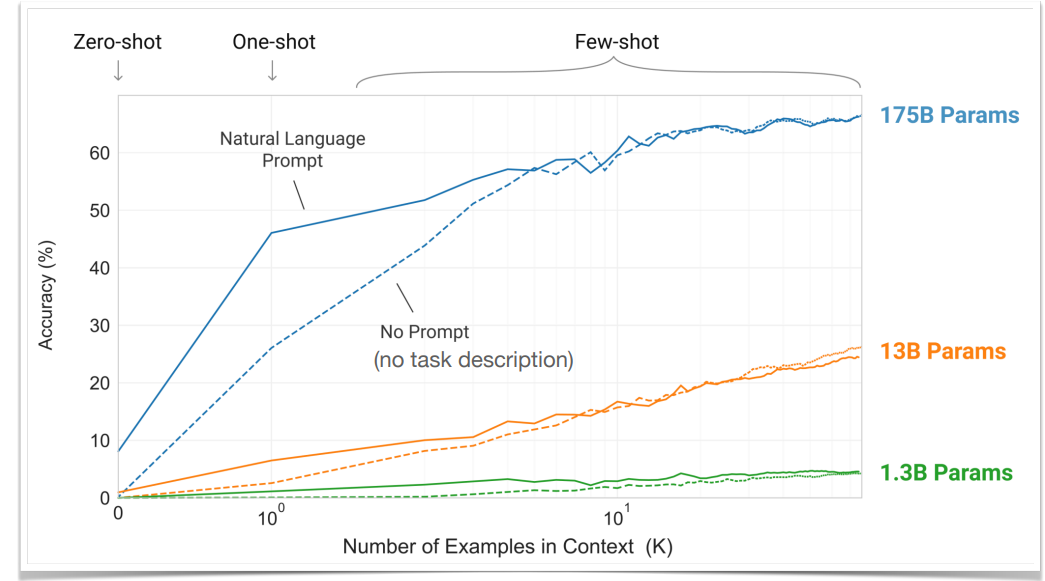
我们发现更大的模型可以更有效地利用 few-shot 的示范。而且给更多的示范,no-prompt 的精确度也可以赶上 task-prompted 的精确度。
-
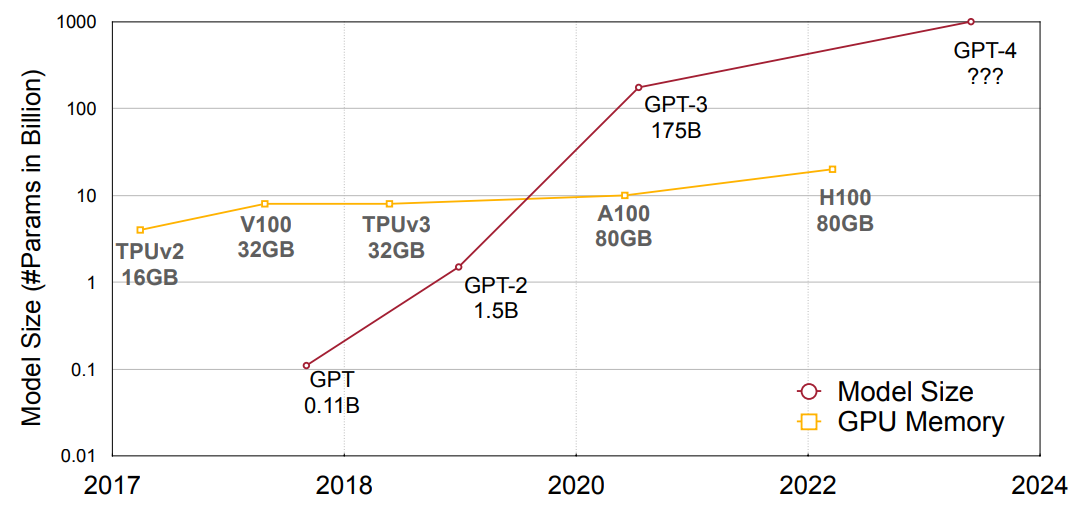
GPT Family:
- GPT-1 (2018): 117 million
- GPT-2 (2019): 1.5B
- GPT-3 (2020): 175B
- GPT-4 (2023): ???
-
OPT
- Open Pre-trained Transformer Language Models (OPT) 是来自 Meta 2022 的开源预训练大模型。
- 模型大小:125M/350M/1.3B/2.7B/6.7B/13B/30B/66B/175B
- Decoder-only, Pren-norm(Post-norm for 350M), ReLU in FFN.
- 175B model: 隐藏层维度 12288,96 个注意力头,词典大小 50k,上下文长度 2048。
- 性能与 GPT 模型很接近。
- BLOOM
- BLOOM 是来自 BigScience 的开源预训练大模型。
- 模型大小:560M/1.1B/1.7B/3B/7.1B/176B
- Decoder-only, Pre-norm, GeLU in FFN, ALiBI
- 176B model: 隐藏层维度 14336,112 个注意力头,词典大小 250k,上下文长度 2048。
- 支持多语言(语料库中包括了 59 种语言
) 。
- LLaMA
- Large Language Model Archive (LLaMA) 是来自 Meta 的开源预训练大模型。
- 模型大小:7B/13B/33B/65B
- Decoder-decoder, Pre-norm, SwiGLU, RoPE
- 7B model: 隐藏层维度 4096,32 个注意力头,32 层,词典大小 32k,上下文长度 2048。
- 65B model: 隐藏层维度 8192,64 个注意力头,80 层,词典大小 32k,上下文长度 2048。
- 和之前的开源模型相比,性能更好。
- LLaMA 2
- 更大的上下文长度(2k->4k)
- 更多的训练 tokens(1T/1.4T->2T,没有饱和的迹象)
- GQA for lager models(70B,64 个注意力头,8 个 kv 头)
- 也包括了 Llama-2-chat,一个 instruction-tuned 的模型。
- Falcon
- 模型大小:1.3B/7.5B/40B/180B
- 与 Llama 2 相比有类似的性能。
- Mistral-7B
- 更小的模型但是有更好的性能:7B 模型在 SuperGLUE 上超过了 Llama-2-13B, Llama-34B。
- 隐藏层维度 4096,32 个注意力头,8 个 kv 头,32 层,词典大小 32k,上下文长度 8k。
- 有 sliding windows attention (SWA) 来以较小的代价处理更长的上下文。
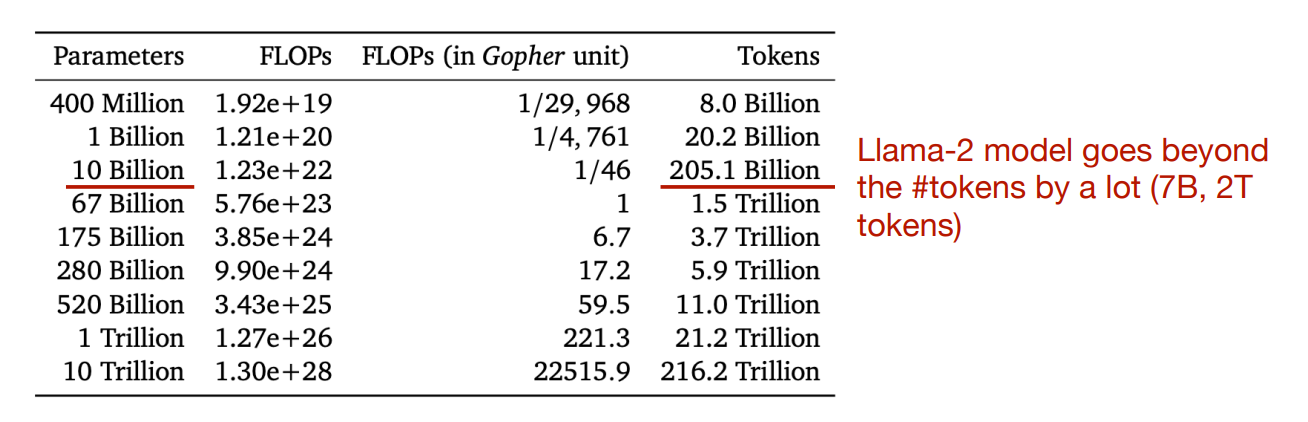
How to scale up? - The Chinchilla Law
- 我们需要同时扩大模型大小和训练用的数据大小,才能实现最好的训练计算和精度之间的平衡。
- 如果我们考虑推理时计算的 trade-off,那么这个权衡有所不同。你想要训练一个更小的模型以节省推理成本。
{kind=link}
Efficient inference algorithms for LLMs¶
Quantization¶
-
SmoothQuant (W8A8)
-
我们希望平滑激活值来降低量化的误差。但是我们发现权重是容易量化的(因为分布均匀
) ,但激活值有很多 outliers,所以难以量化。但我们发现 outliers 总是出现在固定的 channels,因此我们可以把量化的复杂度从激活值转移到权重,这样二者都容易被量化了。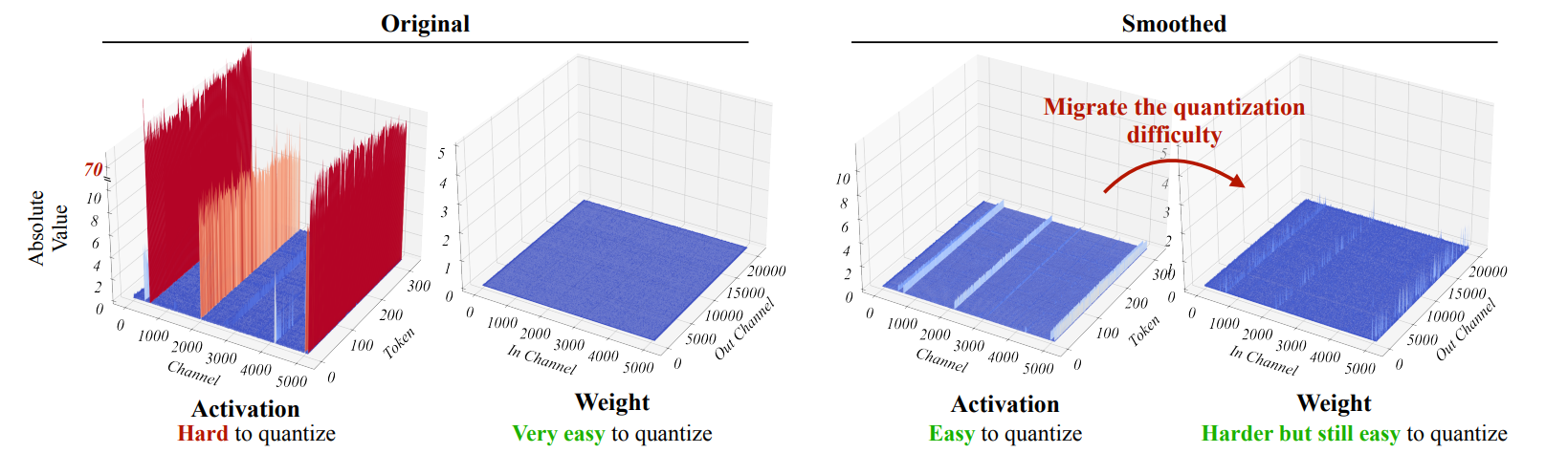
-
平滑的方法就是对于 \(\mathbf{Y=XW}\), 将激活值缩小一个比例系数,同时将权重放大一个比例系数。
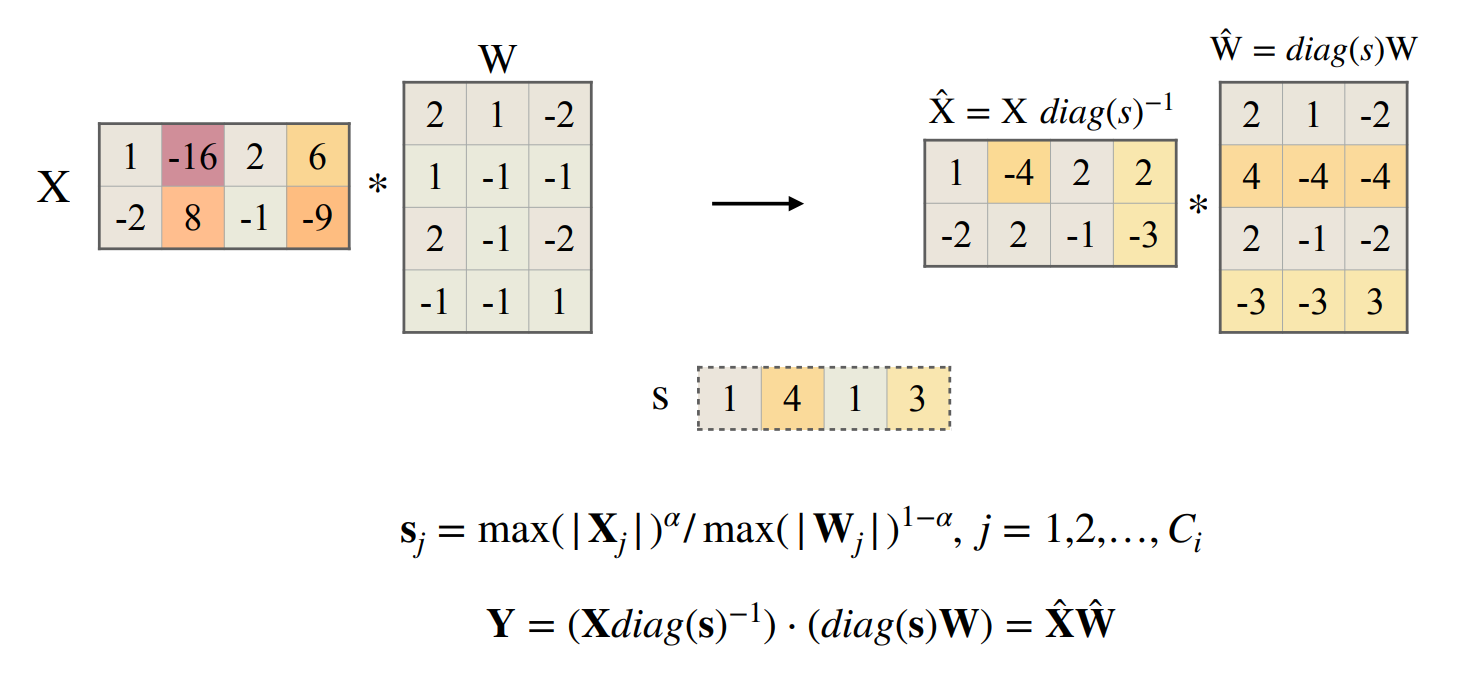
- 对于 \(\mathbf{Y}=(\mathbf{X} diag(\mathbf{s})^{-1})\cdot (diag(\mathbf{s})\mathbf{W})=\hat{\mathbf{X}}\hat{\mathbf{W}}\), 对于权重的缩放可以离线完成,对于激活值的缩放可以折叠到 LayerNorm 的放射变换的因子中。因此实际上这个操作没有 runtime overhead。
- 缩放因子 \(s_j\) 实际上是 \(\mathbf{X}\) 的每一列的最大值除上 \(\mathbf{W}\) 每一行的最大值(即对应输入通道
) 。
-
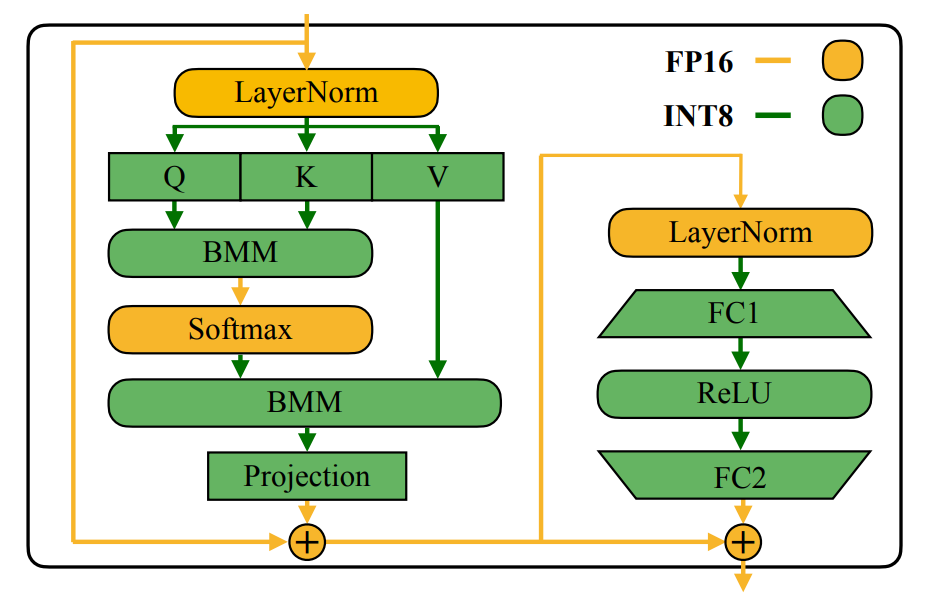
实现上,通过这个技巧我们可以把所有 compute-intensive 的算子(Linears, BMMs)都量化。
-
SmoothQuant 不需要微调也可以保持精度,而且可以加速推理,也可以减少内存占用。且在 LLaMA 上测试发现,即使引入了 SwishGLU, RoPE,SmoothQuant 也不会影响性能。
-
-
AWQ for low-bit weight-only quantization
- W8A8 对于 batch serving 来说已经很好了,但是单查询的 LLM 推理依然是 memory-bounded,即我们需要 low-bit weight-only quantization 低位的只关注权重的量化(e.g., W4A16
) 。但如果我们直接使用 W3/W4 量化,性能会有很大的下降。 -
我们观察到,权重并不是同等重要,只有 1% 的突出权重以 FP16 的格式存储,可以显著改善性能。问题在于如何选择这 1% 的权重。
- 这里我们不能基于权重的大小来选择,而是应该基于激活值的分布(Activation-awareness
) 。 -
我们可以将激活值最大的 channel 对应的突出权重 \(\times s\)(而不是用 fp16 存储
) ,其他权重保持不变。所有权重均是 int4。即 \(\mathbf{WX} \rightarrow Q\mathbf{(W\cdot s)(s^{-1}\cdot X)}\)Protecting salient weights by scaling (no mixed prec.)
下面的分析可以看到,通过对部分 channel 缩放,我们得以降低误差。
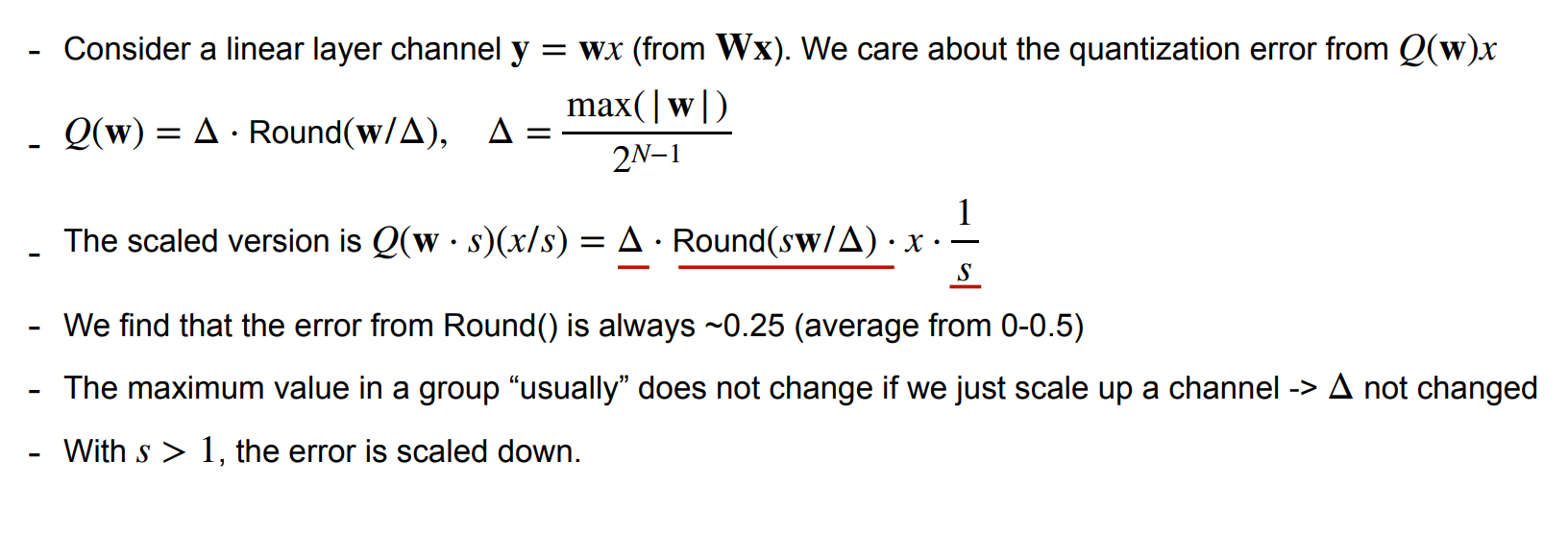
-
可以采用 data-driven 的方法进行快速的 grid search,得到 \(s\) 的取值。
- 这里我们不能基于权重的大小来选择,而是应该基于激活值的分布(Activation-awareness
Better PPL under low-bit weight-only quantization
PPL 用来衡量模型质量,越低越好。
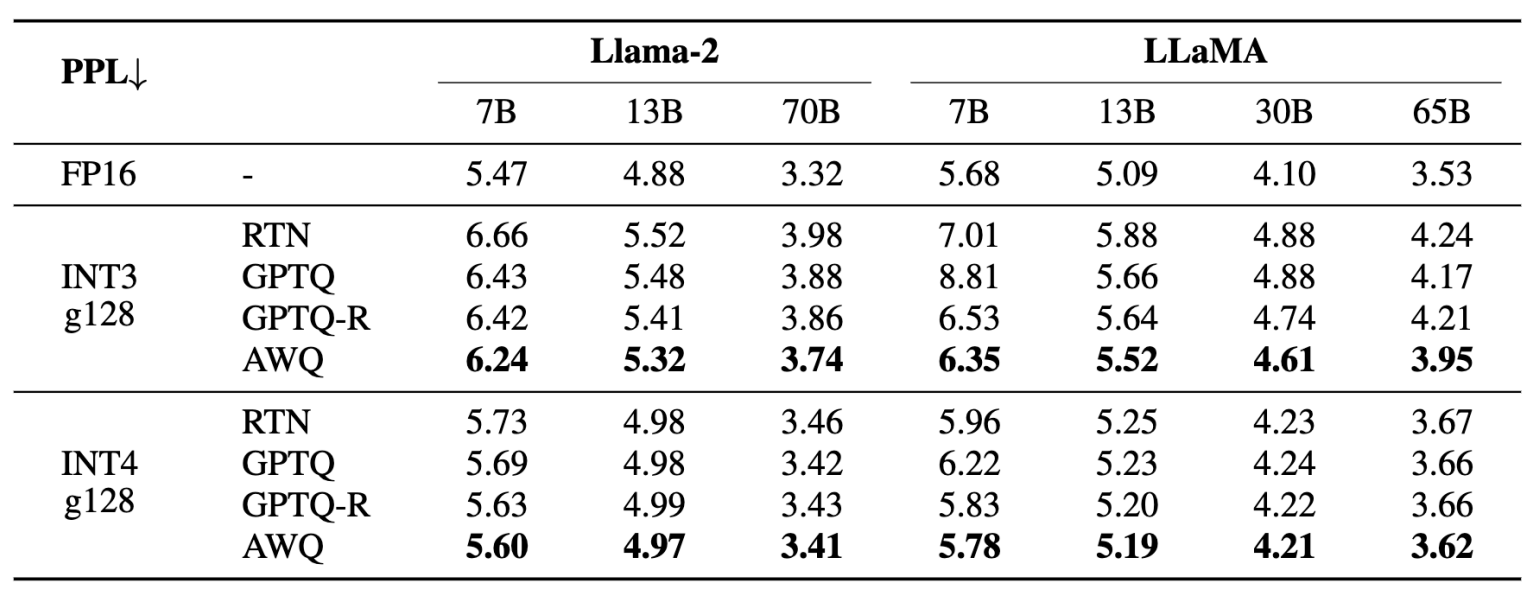
- W8A8 对于 batch serving 来说已经很好了,但是单查询的 LLM 推理依然是 memory-bounded,即我们需要 low-bit weight-only quantization 低位的只关注权重的量化(e.g., W4A16
Pruning/Sparsity¶
-
Pruning
- Wanda 对权重剪枝。思想类似于 AWQ,即我们剪枝权重时应该考虑激活值的分布。
-
这里我们使用 \(|weight|\times \|activation\|\) 作为剪枝的准则。
Magnitude vs Wanda
Wanda 始终优于基于 maginitude 的剪枝。
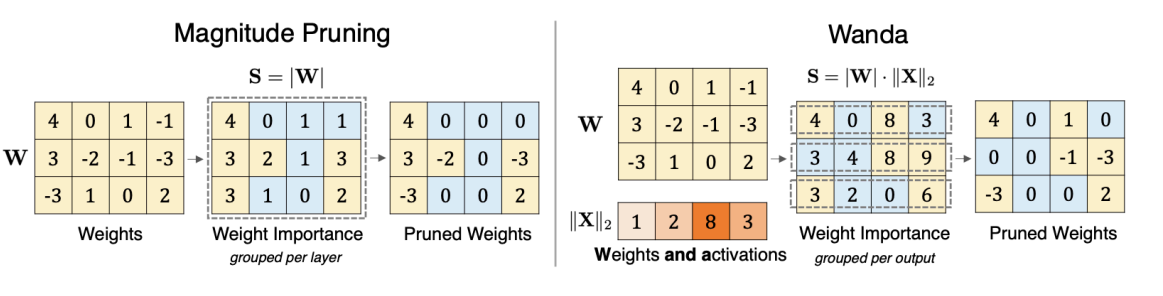
-
Attention Sparsity
-
SpAtten:对 token & head 剪枝。特点在于 cascade pruning,即我们会在运行中逐渐去掉不重要的 tokens & heads。
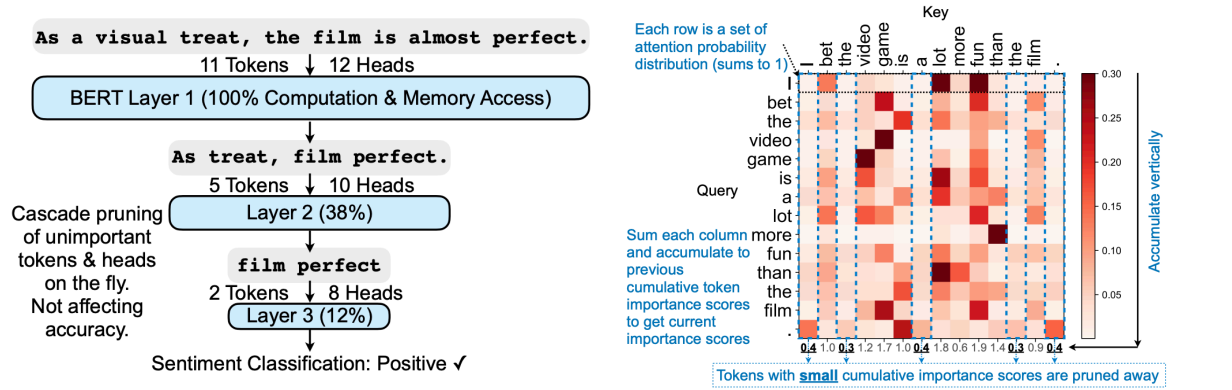
-
H2O:对 KV cache 里的 token 进行剪枝。
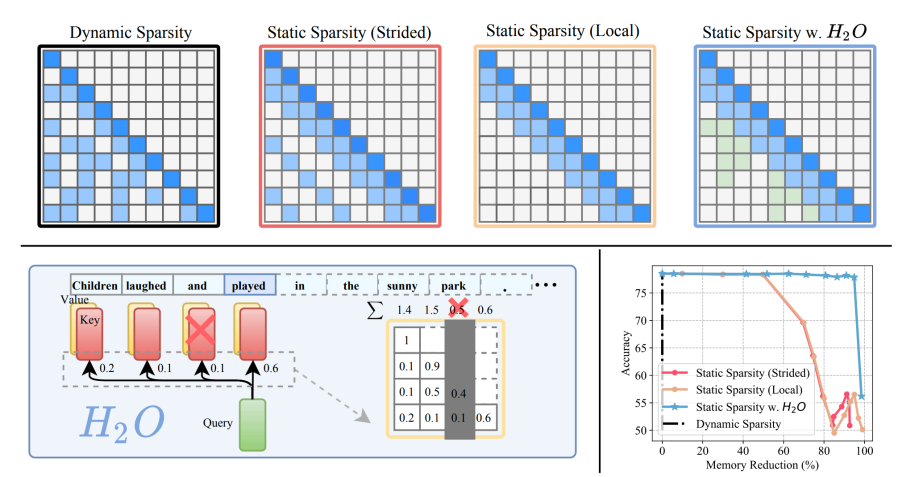
-
DejaVu:用 feature map 预测下一层哪些 heads 可以被修剪。
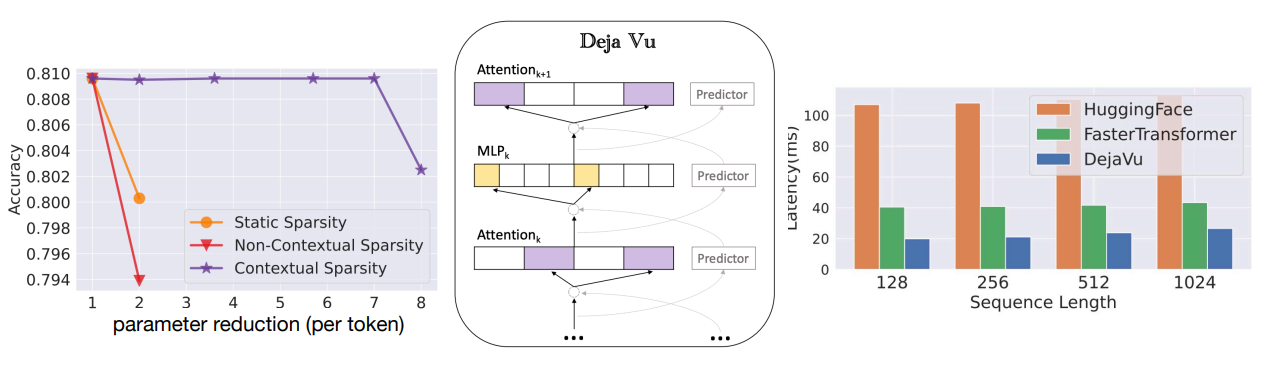
-
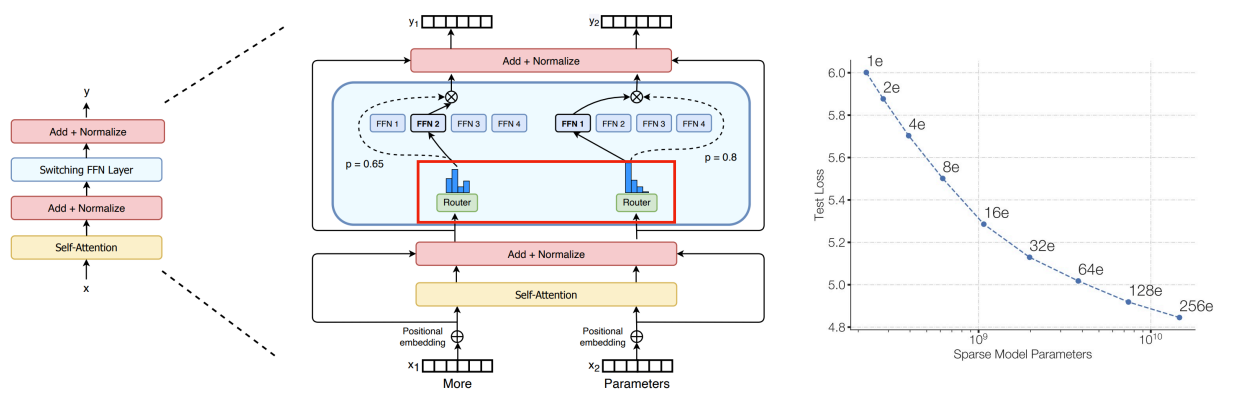
Mixture-of-Experts (MoE)
-
对于每个输入,不激活所有的网络,而是由 router 决定哪部分网络应该被激活(expert
) 。
-
router 也可以采用不同的路由算法。
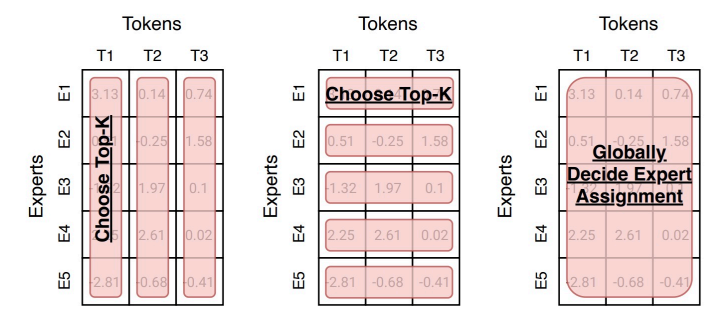
-
-
Efficient inference systems for LLMs¶
vLLM and Paged Attention¶
-
分析 KV cache 的使用:当多用户同时访问时,我们需要预先分配一部分空间用作 KV cache,但是这样会导致内存的浪费。
- 内部碎片:我们不知道输出序列的长度因而 over-allocated。
- 保留区:现在这一步不会用到,但未来可能被使用。
- 外部碎片:因为不同的序列长度,导致不同内存分配之间会有空隙。

-
我们从 OS 中借鉴了 virtual memory 虚拟内存和 paging 分页的思想,允许 KV cache 不连续存储,而逻辑地址保持连续,通过页表来映射。
Example
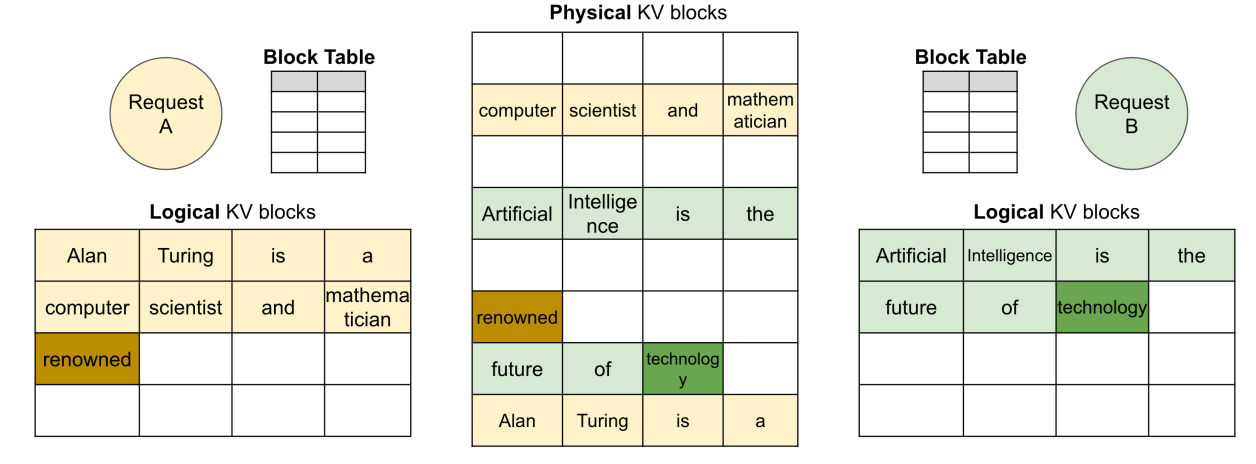
-
Dynamic block mapping enables prompt sharing in parallel sampling. 即我们可以喂一个 prompt,随后由多个进程共享,生成多个不同的输出。
StreamingLLM¶
- 在 streaming application 流应用上部署 LLM 是有挑战的,因为需要消耗大量内存(Out of Memory
) ,而且流行的 LLM 很难泛化到更长的文本序列(Model Performance Breaks) 。 - 一个自然的方法:使用 window attention,即我们只计算最近邻(窗口范围内)的 Key-Value 的 attention。
- 问题是当序列长度超过 cache 大小时,intial token 起初的信息会被踢出 window,从而导致性能的显著下降。
- Observation: 最初的 token 有很大的 attention scores,尽管这个 token 在语义上并不重要。
- 原因在于,Softmax 函数中,我们需要让 attention scores 和为 1。因此第 1 个 token 的优势在于他对于后面 token 的可见性,这源于自回归语言模型
。 (Attention Sinks) - 经过实验可以发现,intial tokens 重要是源于他的 postion 而非 semantics。
- 原因在于,Softmax 函数中,我们需要让 attention scores 和为 1。因此第 1 个 token 的优势在于他对于后面 token 的可见性,这源于自回归语言模型
- StreamingLLM
- Objective:让 LLM 能通过有限的 attention windows 训练,从而能在不额外训练的情况下解决无限文本长度的问题。
- Idea:保存 attention sink tokens 的 KV,和 sliding windows'KV 一起计算来让模型的行为稳定。
- 在使用位置编码时,我们使用在 cache 里的位置而不是使用在原始文本中的位置。
- 同时实现 StreamingLLM 和 Paged Attention 时,我们只需要 pin 住 intial tokens,保证他们不会被踢出即可。
- 实验里表明 4 attention sinks 足够解决问题,同时我们可以训练一个只需要 1 个 sink 的 LLM。方法是引进一个额外的可学习的 token 在最开始。
FlashAttention¶
-
FlashAttention 使用 tiling 来阻止 \(N\times N\) attention 矩阵的 materialization,因此避免了使用缓慢的 HBM,还使用了 kernel fusion 的技巧。
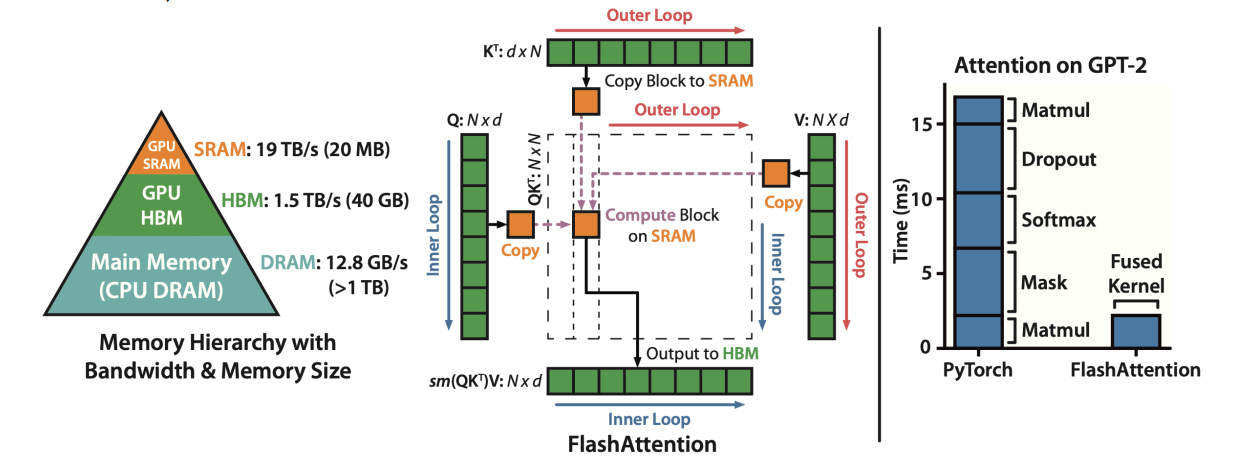
Speculative Decoding¶
- 投机译码,用来加速 memory-bounded 的生成。LLM 的 decoding 阶段都是 token by token,即一个一个地输出,这会导致内存受限(因为 batch size 很小)
- 投机译码中,我们有两个模型:
- Draft model 是一个比较小的 LLM(如 7B)
- Target model 是一个比较大的 LLM(如 175B
) ,即我们希望加速的模型。
-
具体流程:draft model 自回归地生成 \(K\) 个 tokens(batch size \(K\)
) ,将这 \(K\) 个 tokens 并行地送入目标模型,并得到预测的概率。最后决定接受还是拒绝这 \(K\) 个 tokens。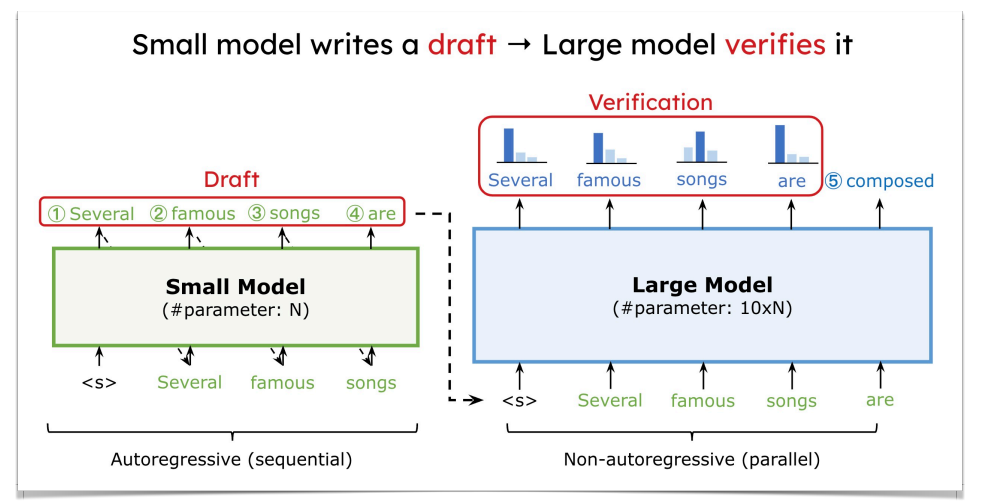
-
因为多个 tokens 是并行送入 target model 的,所以提高了内存的瓶颈。
Efficient fine-tuning for LLMs¶
-
LoRA: Low-rank adaptation
-
不更新整个模型权重,而是只更新 low-rank 的小部分。
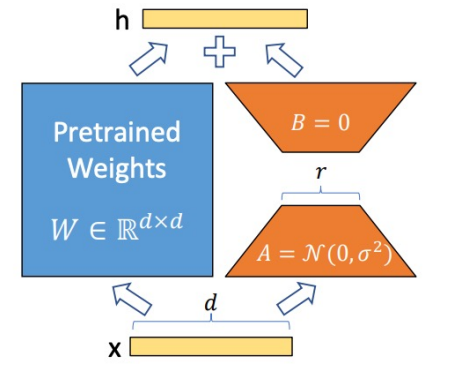
-
好处是可以加速微调(因为跳过了梯度计算
) ,节约了微调内存(减少了优化器状态) ,阻止了灾难性的遗忘,低秩权重是可以融合的。
-
-
QLoRA: LoRA with quantized base model weights
-
使用了 NormalFloat (NF4),进行了两次量化(对 scaling factor 也进行了量化)来进一步降低基础模型的大小,支持带有 CPU Offload 的分页优化器。
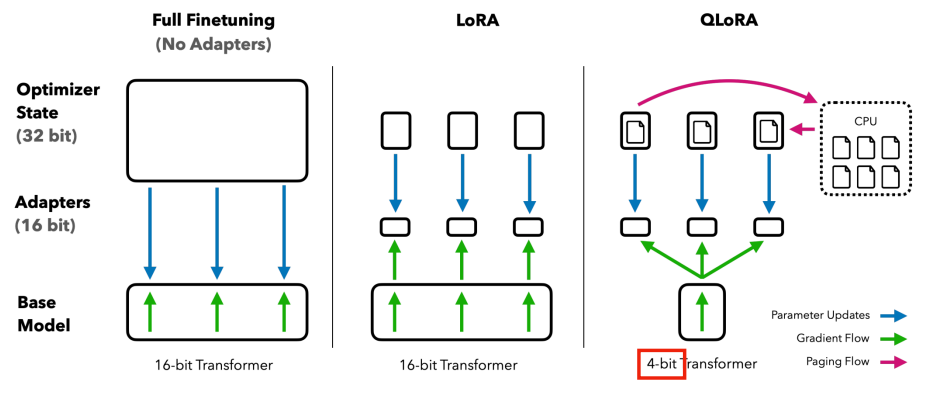
-
-
Adapter
-
smaller adapter for transfer learning, cannot be fused.
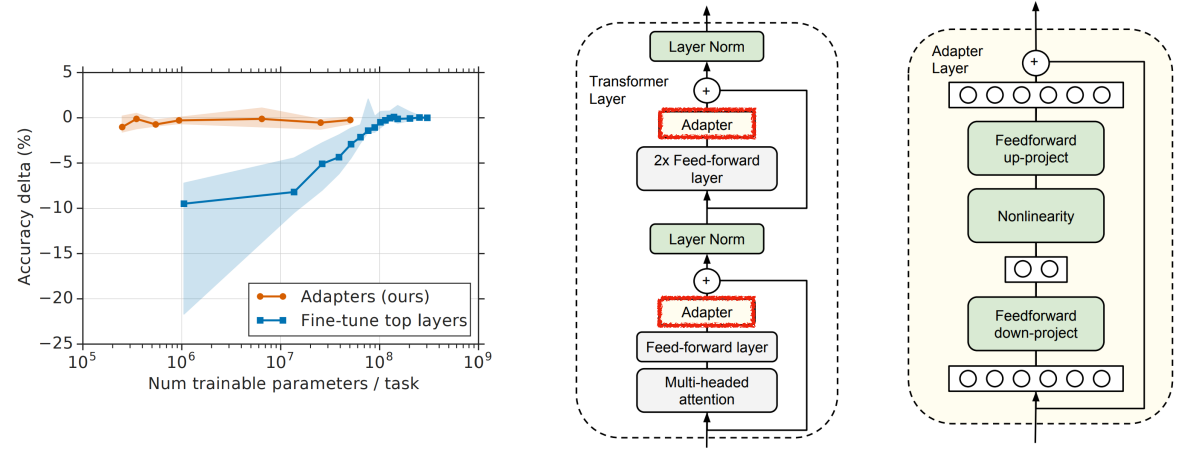
-
-
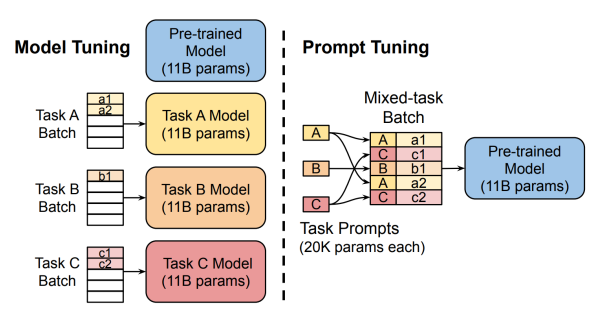
Prompt Tuning: From discrete prompt to continuous prompt
- 我们可以训练 continuous prompt,附加到每个任务的输入中。
-
我们还可以把不同的可学习的 prompt 混合在一个 batch 中。