Efficient Fine-tuning and Prompt Engineering¶
约 1004 个字 16 张图片 预计阅读时间 3 分钟
Abstract
- Efficient LLM Fine-Tuning
- BitFit / Adapter
- Prompt-Tuning / Prefix-Tuning
- LoRA / QLoRA / LongLoRA
- Prompt-engineering
- Zero-shot / Few-shot / Chain-of-Thoughts
Efficient LLM Fine-Tuning¶
- 为什么要进行微调:
- Security: Data need to stay on-device. 不必担心数据泄露,例如 copilot.
- Customization: Models continually adapt to new data for customization.
-
Motivation
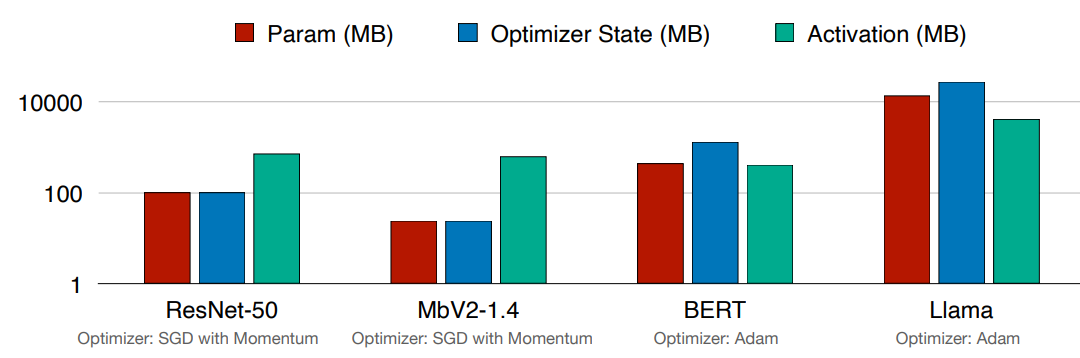
- 从视觉模型移动到 LLMs 时,参数和优化器状态主导了 GPU 内存使用。因此我们需要 parameter-efficient fine-tuning 参数高效的微调。
Model Tuning¶
-
BitFit
-
只微调 bias 项。只有模型的 bias(或者 bias 的子集)会被更新,其他部分保持不变。e.g. BERT-base 110M 参数,只有 0.1M(>1000x less) bias.
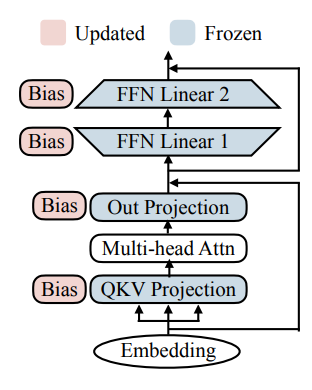
-
对于小到中的数据集,BitFit 和 full-fine-tuning 完全微调的性能相当(有的时候更好
) 。但是对于更大的数据 ,模型的性能弱于完全微调。
-
-
Adapter
-
对于每个任务,在模型中插入少量 learnable layers 可学习层。新的任务会在移去之前的层后加上新的可学习层。微调时只更新对应的可学习层。
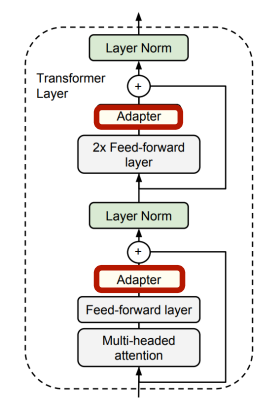
-
通常,假设有 N 个下游任务,我们需要 N 份模型权重的拷贝。
- FT-Full: 1000 sub-tasks x 7B llama => 14 PB storage
- Adapter: 1000 sub-tasks x 14 MB => 14 GB storage
- 只需要加少部分参数即可逼近 SOTA 性能。
- 但是 adapter 在部署时会带来额外的推理开销(因为添加了其他层
) 。
-
Prompt Tuning¶
-
Prompt-Tuning
- 如果对于不同的任务我们有不同的模型,可能会导致处理效率低(因为 GPU 擅长 batch processing
) 。 -
我们可以对于每个任务,end-to-end 地学习一个 prompt(learnable per task specific prompt
) ,插入在输入之前。这样我们可以将不同的任务放在同一个 batch 里,用不同的 prompt 区分任务。Example
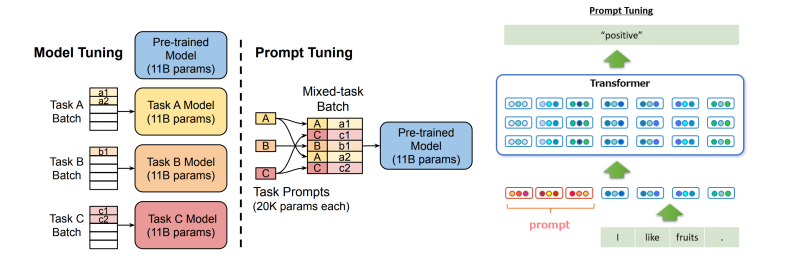
例如在这里,我们在 "I like fruit" 前加上 prompt "Please tell me the sentiment of the following text:" (这个是手工设计的,也可以通过 e2e 学习得到
) ,最后得到输出 "positive". -
当模型变大时,精度与微调的方法接近。
- 如果对于不同的任务我们有不同的模型,可能会导致处理效率低(因为 GPU 擅长 batch processing
-
Prefix-Tuning
-
Prompt-Tuning 只在第一层插入 learnable prompts,而 Prefix-Tuning 在每一层插入 tunable prompts。
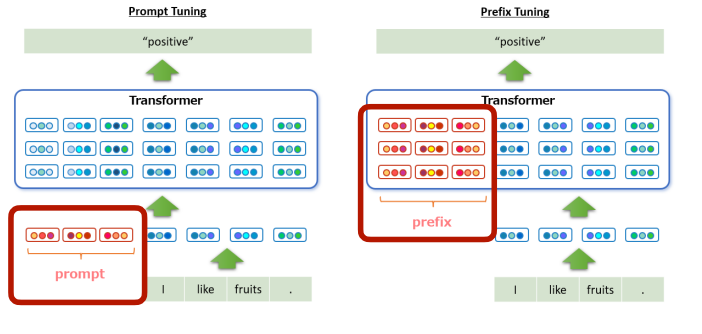
-
Prefix-tuning shows consistent improvement of embedding-only-tuning.
- 这两种方法的缺点:
- 带来了更长时间的推理开销。
- 会占据可用的 token length 进而限制真正可用的序列长度。
-
LoRA Family¶
-
LoRA (Low-Rank Adaptation)
-
在预训练的权重上加上 parallel fusable learnable layers (parallel branch)
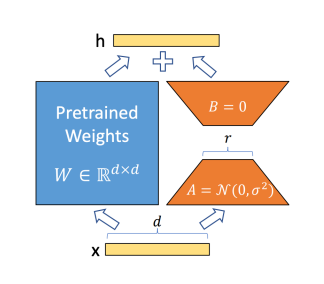
- LoRA 模块包括两个部分:
- \(A_{r\times d}\): 将 \(d\) 维输入映射到低秩 \(r\) 维上。用 Gaussian distribution 初始化 \(A\).
- \(B_{d\times r}\): 将 \(r\) 维映射回 \(d\) 维。用全 0 初始化 \(B\)。
- 输出并不会被影响,因为初始化时 \(B=0\), \(h=x@W + x@A@B =x@W\).
- 在做推理时,A B 可以被融合回原来的权重,\(h=x@W+x@A@B=x@(W+A@B)=x@W''\). 因此不会带来额外的推理开销!
- LoRA 模块包括两个部分:
LoRA Practical Cases

-
-
QLoRA
-
LoRA, with quantized backbones and paged optimizer states
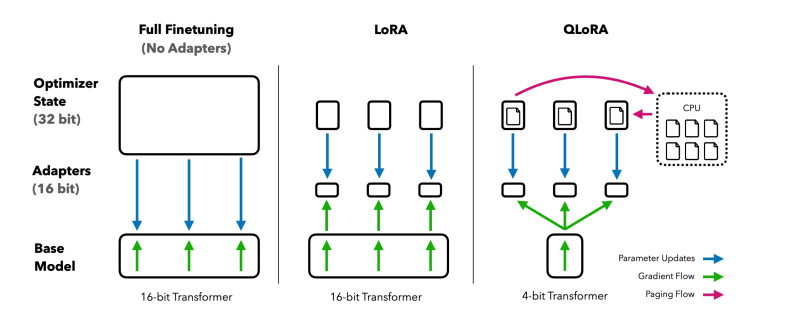
- 使用 NormalFloat (NF4) 量化模型权重,还使用了 double quantization(即 scale factor 也是量化的
) 。 - 使用 paged optimzers,可以将其 offload 到 CPU 上。
- 使用 NormalFloat (NF4) 量化模型权重,还使用了 double quantization(即 scale factor 也是量化的
-
-
LongLoRA
- 微调模型使其能处理长序列。
-
Shifted Sparse Attention: 将 attention 分头;将 tokens 移动半个组;最后将结果拼接。
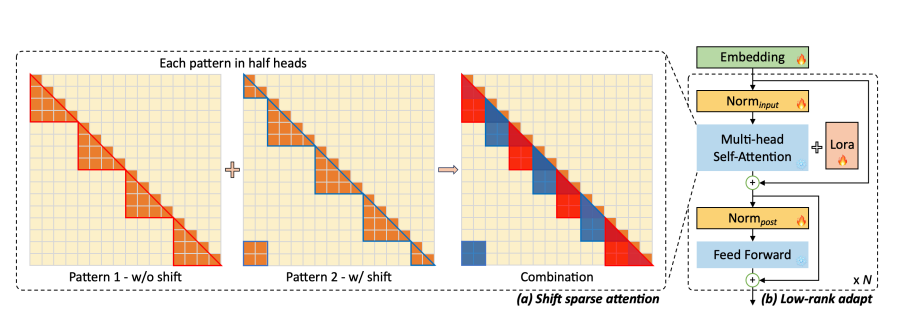
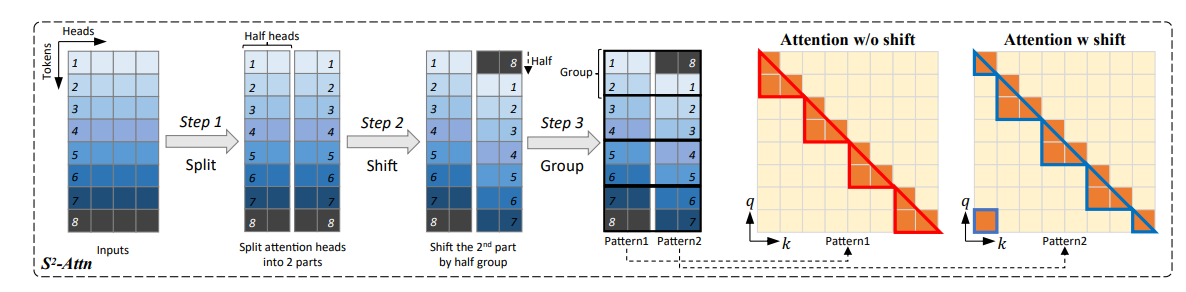
- 分组后,我们只在组内做 attention,不考虑组间的关系。为了保持全局信息,我们对平移后的组也进行组内 attention,并拼接结果。
- Shifted Sparse Attention 只在微调训练时使用,推理时仍然为完整的 attention。
- Enhanced LoRA: 同时微调 input embedding, normalization layers(上图中标出的部分即为要进行微调的部分
) 。
- Enhanced LoRA: 同时微调 input embedding, normalization layers(上图中标出的部分即为要进行微调的部分
Prompt Engineering¶
-
Zero-Shot Prompting: One Foundation Model -> Prompting -> Different tasks.
Example

-
Few-Shot Prompting: By providing few examples, the LLMs can perform a new task even it is not trained on it (in-context learning).
Example

Tricks and tips for few-shot prompting
-
Input Example Distribution: 提供输入各个分类的样例时,每一个类别应该有类似数量的样例。
Example

-
Format Consistency: 保持输入格式的一致性,例如输入的长度,格式等。
Example

-
-
Chain-of-Thought Prompting: enable complex reasoning capabilities through intermediate reasoning steps.
Example
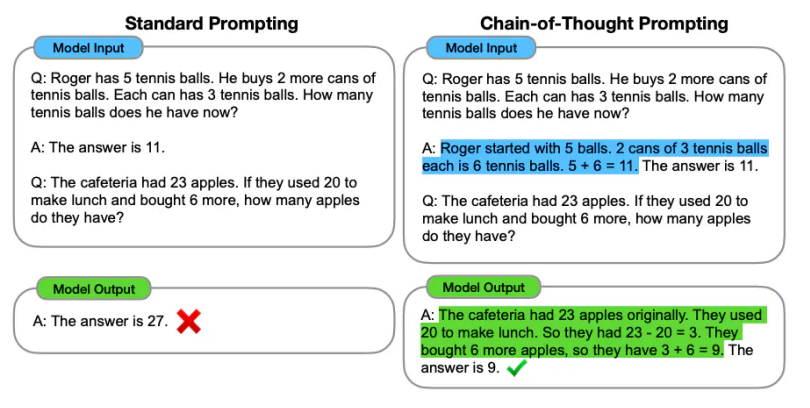
-
有时,我们可以通过 "Let's think step by step" 这个神奇的 prompt 来引导模型进行推理。
Example

-