Processing-In-Memory (PIM)¶
约 1351 个字 1 张图片 预计阅读时间 5 分钟
Abstract
存内计算架构介绍,本文基于 UPMEM PIM,第一个公开可用的真实世界 PIM 架构。
许多现代工作负载,如神经网络从根本上说都是 memory-bound 的。对于此类工作负载,主存和 CPU 内核之间的数据移动在延迟和能耗方面都会带来巨大的开销。一个主要原因是,这种通信是通过具有高延迟和有限带宽的窄总线进行的,并且内存受限工作负载中的 data reuse 不足以摊销主内存访问的成本。从根本上解决这种数据移动瓶颈需要一种范式,即内存系统通过集成处理能力在计算中发挥积极作用。这种范式称为 Processing-In-Memory(PIM)。
System Organization¶
UPMEM PIM 系统:
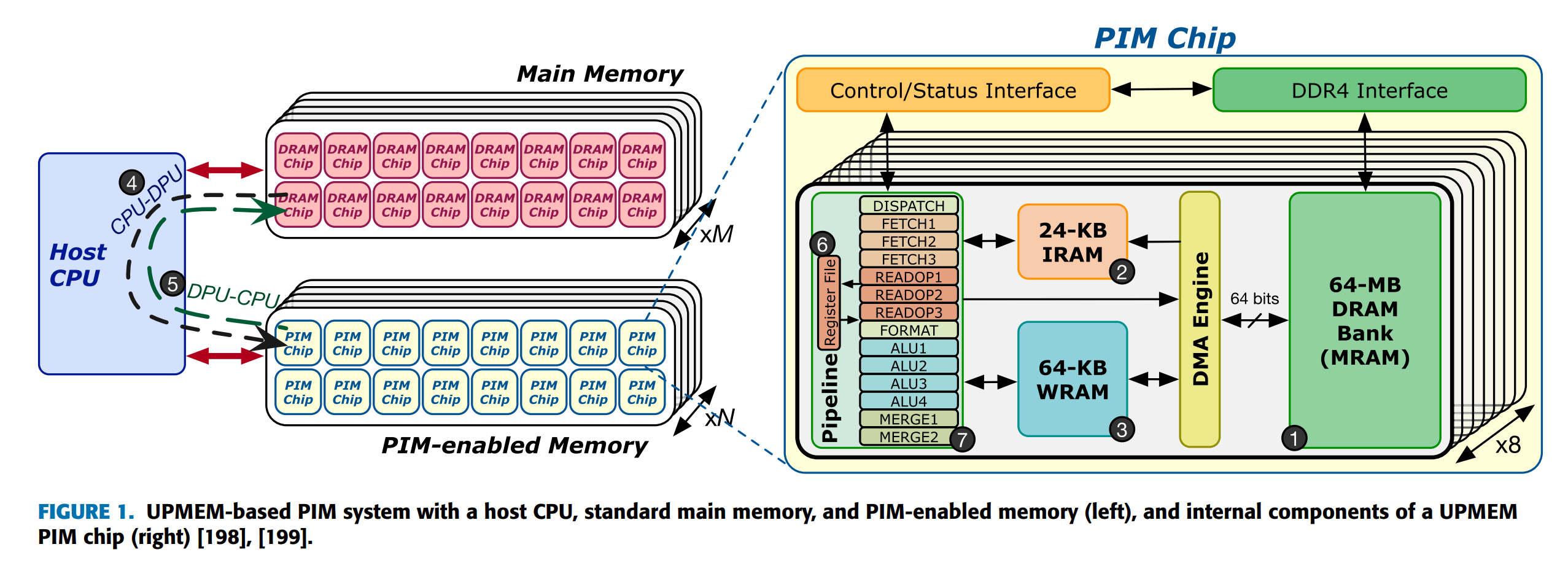
- host CPU
- standard main memory (DRAM memory modules)
- PIM-enabled memory (UPMEM modules)
- UPMEM 模块中的所有 DPU 都作为主机 CPU 的并行协处理器一起运行。
- 一个 PIM-enabled memory 可以放一个或者多个内存通道,有多个 PIM chips(e.g. 16
) 。 - 每个 UPMEM PIM chip 内有 8 个 DPU(DRAM Processing Unit),每个 DPU 有 24KB 的 IRAM,64-KB 的 WRAM,以及 64-MB DRAM Bank(MRAM)。
- MRAM 可被 CPU 访问,方式是 copying input data(传送到 MRAM)or retrieving results(从 MRAM 中获得
) 。从 / 传入所有 MRAM 库的缓冲区大小相同,则这些 CPU-DPU 和 DPU-CPU 数据传输可以并行执行(即跨多个 MRAM 库并发执行) 。否则,数据传输将串行进行。 - DPU 之间不能直接通信,只能通过主机 CPU 间接实现。即先把检索结果从当前 DPU 传回 CPU,再从 CPU 传到另一个 DPU 上。
- CPU 和 DPU 不能同时访问同一个 MRAM bank。
- 数据排列不同:主存将连续的 8-bit words 映射到连续的 DRAM 芯片上,而支持 PIM-enabled memory 需要将整个 64-bit words 映射到同一个 MRAM 组。原因在于每个 DPU 只能访问自己的 MRAM,但是我们可以对 64 位的数据类型进行处理,因此需要保证同一个 64 位数据类型的所有 8 个字节都在同一个 MRAM 组中。
- MRAM 可被 CPU 访问,方式是 copying input data(传送到 MRAM)or retrieving results(从 MRAM 中获得
- 主机 CPU 可以分配所需数量的 DPU,即 a DPU set,以执行 DPU 功能或内核。然后,主机 CPU 以同步或异步方式启动 DPU 内核。
- 同步执行会挂起主机 CPU 线程,直到 DPU 集完成内核执行。
- 异步执行会立即返回主机 CPU 线程,允许主机 CPU 线程继续执行其他任务。
- 在当前基于 UPMEM 的 PIM 系统配置中,UPMEM DIMM 的最大数量为 20(即最多有 20 个 UPEM DIMM
) 。具有 20 个 UPMEM 模块的基于 UPMEM 的 PIM 系统最多可包含 2560 个 DPU,相当于 160 GB PIM-enabled memory。
DPU Architecture¶
DPU 是多线程的顺序执行 32 位 RISC 核,支持特定的 ISA。
- 有 24 个硬件线程,每个线程有 24 个 32-bit 通用寄存器。硬件线程共享 IRAM 和 WRAM。
- 14 级流水线,但是只有最后三级(ALU4、MERGE1、MERGE2)可以和下一条指令的 DISPATCH、FFTCH 阶段并行执行。因此同一线程的指令必须间隔 11 个周期发射。为了充分利用流水线,需要至少 11 个线程同时执行。
- 24 KB IRAM 可以放 4096 条 46-bit 指令。
- DPU 访问 WRAM 时可以读写 8/16/32/64 bits。
- ISA 提供指令,将数据从 MRAM 通过 DMA 搬到 IRAM;或者在 MRAM 和 WRAM 之间互相传输。
在论文中,DPU 的时钟频率为 350MHz(2556-DPU
DPU Programming¶
基于 UPMEM 的 PIM 系统使用单程序多数据(SPMD
- 最多有 24 tasklets 可以同时运行在一个 DPU 上,因为硬件线程为 24。
- 同一 DPU 内的 Tasklet 可以在 MRAM 和 WRAM 中相互共享数据,并且可以通过互斥 mutexes、屏障 barriers、握手 handshakes 和信号量 semaphores 来同步。
- 不同 DPU 的 Tasklet 之间不能直接通信,也不共享内存。
- 编程语言和运行库
- C with librabry calls, UPMEM SDK
- 访存:
mram_read()for MRAM => WRAM,mram_write()for WRAM = >MRAM - 同步:
mutex_lock()andmutex_unlock()barrier_wait()handshake_wait_for(), handshake_notify()sem_give(), sem_take()
- 挑战:
- 对运行多达 24 个任务的数千个 DPU 进行编程需要仔细的工作负载分区和编排。每个线程有自己的 tasklet ID,可以用来确定线程的任务。
- 程序员需要自己显式控制主存和 MRAM 的数据传输,并保证 CPU 和 DPU 的数据一致性 coherence。
- DPU 不使用缓存,MRAM 与 WRAM 之间的传输也要由程序员显式管理。
- 编程建议
- 在 DPU 上执行并行代码的长度尽可能长,避免与主机 CPU 频繁交互。
- 拆分工作负载时要转为互相独立的数据块,减少 inter-DPU 通信和同步。
- 使用尽可能多的 DPU,提高并行度,keep DPUs busy。
- 每个 DPU 中至少有 11 个线程,以充分利用流水线。