LLVM IR¶
约 1432 个字 55 行代码 11 张图片 预计阅读时间 5 分钟
Abstract
LLVM IR 的基本知识,包括 Phi、GEP 等基本指令,内容来自 2019 EuroLLVM Developers’ Meeting: V. Bridgers & F. Piovezan: LLVM IR Tutorial - Phis, GEPs and other things, oh my! - Vince Bridgers (Intel Corporation).
Introduction¶
LLVM IR: The LLVM Intermediate Representation.
-
IR Representation
- Bitcode file
*.bc -
Human-readable file
*.ll本文主要讨论这部分。
*.bc可以通过llvm-dis工具转换为*.ll,*.ll可以通过llvm-as工具转换为*.bc。 -
In-memory representation
- Bitcode file
Simplified IR layout¶
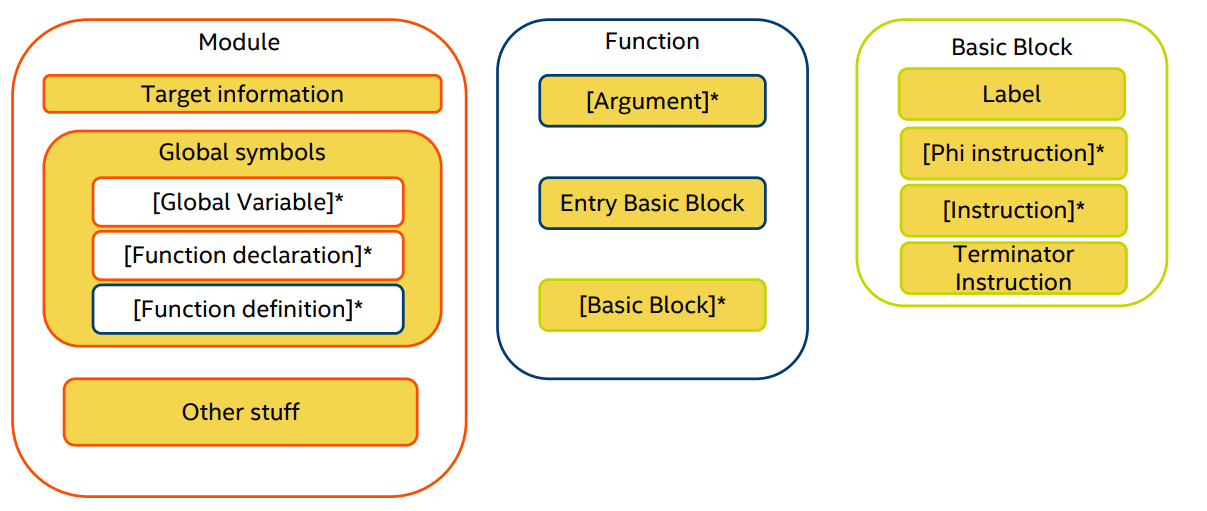
这里的 []* 表示可以有 0 或者多个。
这里用三个示例程序来说明 LLVM IR 的基本结构。
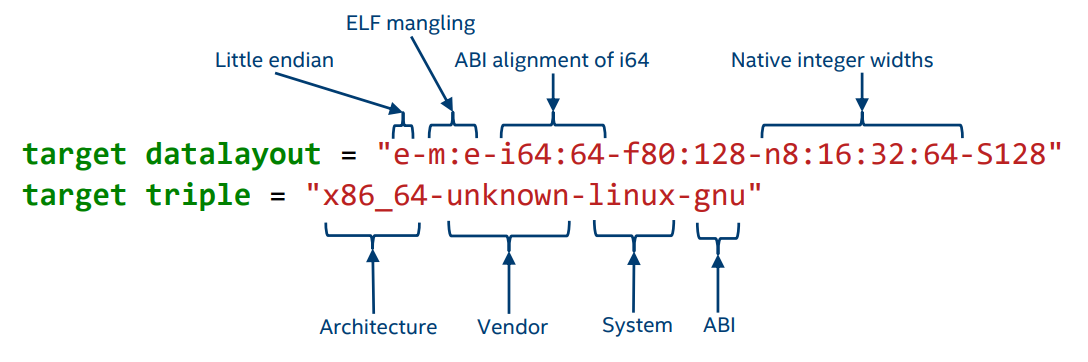
Target Information¶
An IR module usually starts with a pair of strings describing the target:
A basic main program¶
declare表示函数的声明,@factorial是函数名。
% Virtual Registers %- 这里有局部变量,分别用
Unnamed: %<number>和Named: %<name>表示。e.g.%1unnamed,%resultnamed. - LLVM IR 里我们假设有无限多的寄存器。如何进行实际寄存器分配是由后面的阶段处理。
- 这里有局部变量,分别用
- 强类型语言
- 需要明确规定参数类型。
- 指令需要明确规定期望得到的类型。e.g.
call指令期望得到i32类型的返回值。 - 没有隐式类型转换。e.g. 将上面
%result = zext i1 %3 to i32中的zext去掉,并将返回改为ret i32 %3会报错,因为%i3的类型是i1但是函数的返回值类型要求是i32.
- 指令会有很多变体 variants,可以参考 LangRef.
Recursive factorial¶
- Basic Block: List of non-terminator instructions ending with a terminator instruction.
- 其中终结符是一条指令,用来转移 control flow.
- Branch - “br”
- Return - “ret”
- Switch – “switch”
- Unreachable – “unreachable”
- Exception handling instructions
- 我们用 Control Flow Graph(CFG) 来表示后继关系。
- 每个基本块在入口的地方都有一个 label,即使没有显式标出。e.g. 在上面的例子中如果去掉
entry:会报错。因为去掉之后编译器会自动为我们填充一个 label%0,而这个 label 名与后面的寄存器%0名字冲突了。
- 其中终结符是一条指令,用来转移 control flow.
Iterative factorial¶
-
LLVM IR 要求满足 Static Single Assigment(SSA),即每个变量只能被赋值一次,而且在使用前要先定义。
- 在上面代码的第 10、11 行会报错,因为不符合 SSA 的要求。我们需要改为另外的变量
%new_temp和%i_plus_one。但这样会导致另一个问题:最后我们返回时无法选择返回的是%temp还是%new_temp。 -
为此我们需要使用 Phi 指令,作用是在基本块里基于之前的执行结果(控制流)选择值,格式如下:
即我们从哪个 label 过来,就选择对应的 val。Example
修改后的代码如下:

可以看到对于
%temp,如果我们是从entry顺序执行到这里,那么%temp应该进行初始化,选择值 1;否则从for_body过来,说明我们要更新,选择值`%new_temp。 -
另一种解决 SSA 的办法:前端有时会生成另外的代码,通过读写内存来绕过对变量(寄存器)的多次读写。
Note
使用编译器时,可能观察到这样的现象:如果你不加任何优化 (
-O0),那么编译器会生成很多的读写内存的指令,这是为了绕过 SSA 的限制。如果开启-O1优化,那么会生成使用 Phi 指令的代码。
- 在上面代码的第 10、11 行会报错,因为不符合 SSA 的要求。我们需要改为另外的变量
-
全局变量
-
They are always pointers, like the values returned by Allocas.
指针表示,因此全局变量也可以用来解决 SSA 的问题(相当于读写内存地址
) 。 -
命名前必须加上
@,显式标明类型,必须被初始化,要有global属性。如@gv = global i8 42- 也可以使用
const属性代替global属性。如@gv = const i8 42。但需要注意的是const属性的全局变量不能被修改。
- 也可以使用
-
全局变量是静态分配的,因此总是指针形式,而且是 const pointer(即指向的位置不能被修改
) ,因此编译器可以推断出全局变量的地址。
-
-
To check if this is valid IR:
opt –verify input.ll可以用来检查自己写的 IR 是否正确。
-
The optimizer can generate the CFG in dot format:
opt –analyze –dot-cfg-only input.ll-dot-cfg-only= Generate .dot files. Don’t include instructions.opt –analyze –dot-cfg input.ll, 去掉-only选项可以得到更详细的图。
Type System and GEPs¶
根据 LLVM 语言参考手册,LLVM IR 有以下类型:

其中 First Class Types 表示可以由一条指令返回的类型。
Aggregate types: arrays¶
- arrays 由一个固定的大小,元素类型,初始化方法来定义。如
@array = global [17 * i8] zeroinitializer表示一个名为@array的数组,里面由 17 个元素,每个元素类型为i8,初始值均为 0。 -
GEP(Get Element Pointer) 指令用来访问数组的元素。
-
GEP 用于计算指针地址,格式如下:
这里第一个
<ty>是第一个索引的基类型,<ptrcal>是基地址,<idx>是偏移(以基类型为单位) 。Example
这里基类型是
i32,因此 GEP 得到的是从 0 开始的第 3 个i32。
-
需要注意以下几点:
-
GEP 的偏移是以基类型为单位,而且不会改变结果指针的类型。
Example
这里的基类型是
[6 * i8],因此当我们的偏移是 1 时,他会跳过当前数组的所有元素,返回一个未知元素的指针。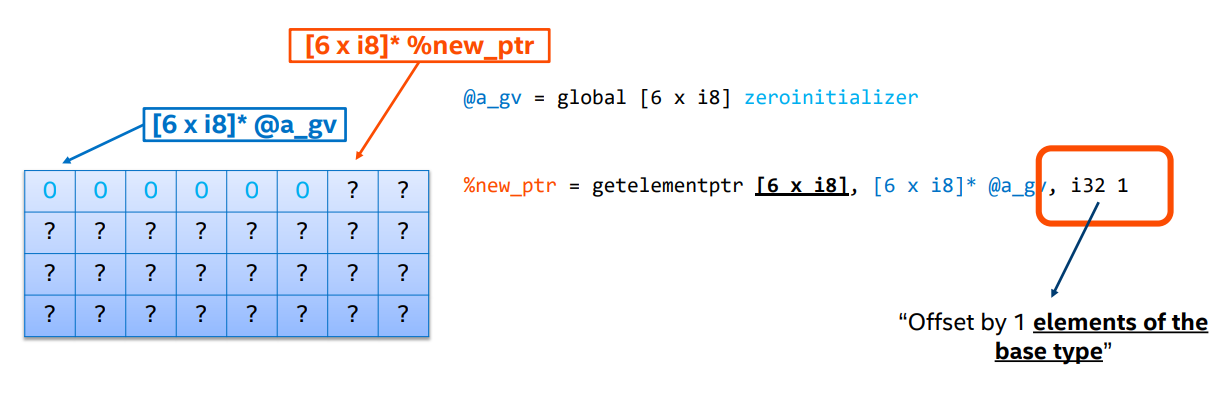
-
可以使用 further indices 来获得 aggregate types(and vectors) 内的偏移。但是如果要改变指针的类型,需要去掉一层 aggregation。
Example
-
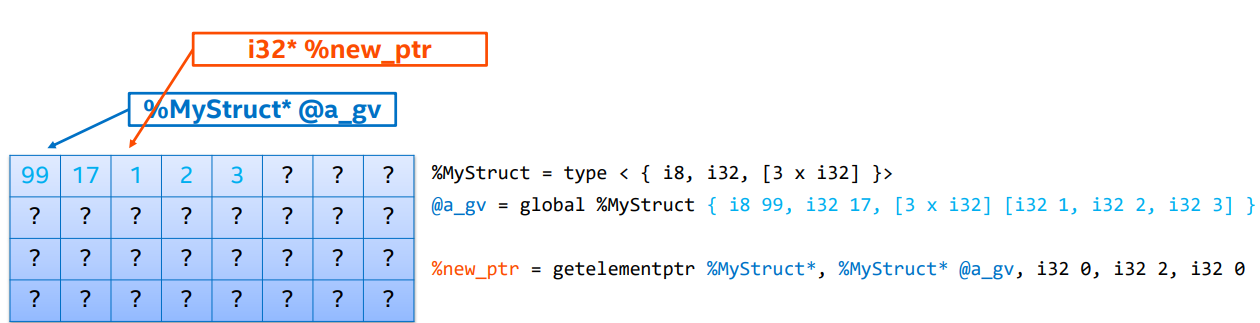
Manipulating pointers


-
GEP with structs
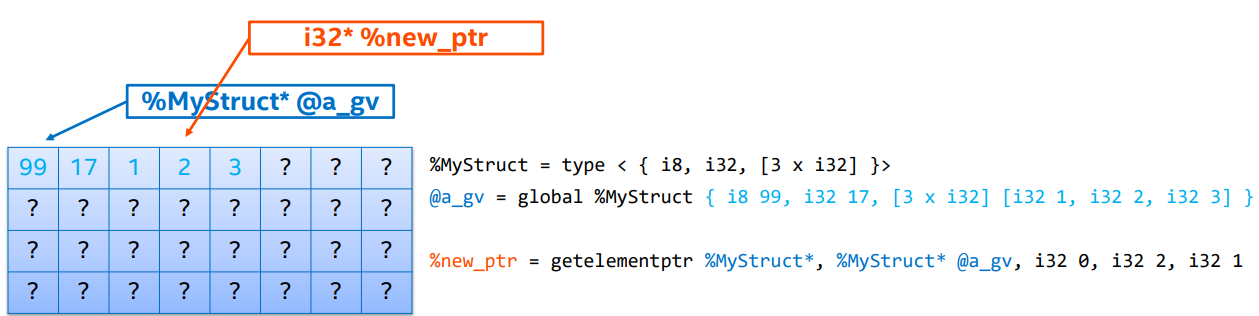
-
-
GEPs 不会从内存里加载,即只能用于查找地址,不能剥离聚合。
Example
注意这里的
%new_ptr是一个指向[4 * i8]**的指针,即指针的指针,因此我们需要使用load指令来获取真正的指针。
-
-
参考资料 ¶
- Youtube Video: LLVM IR Tutorial - Phis, GEPs and other things, oh my! - Vince Bridgers (Intel Corporation), Felipe de Azevedo Piovezan (Intel Corporation), Slide
- LLVM Pass 入门导引