CGRA¶
约 2529 个字 10 张图片 预计阅读时间 8 分钟
Abstract
介绍 CGRA,包括其架构、编译、挑战等。如有错误还请见谅。
参考:
Introduction¶
Coarse-Grained Reconfigurable Array(CGRA)
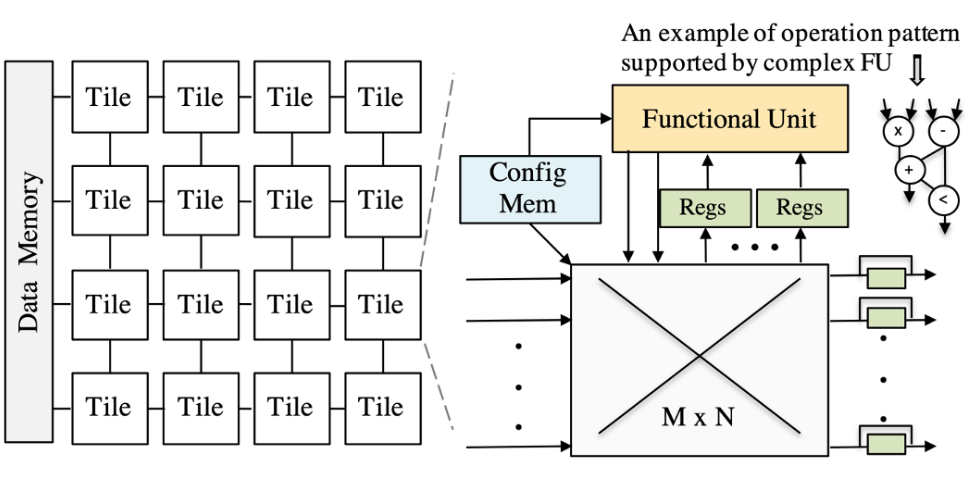
- What
- 由若干个 Tile 组成,其中 Tile 主要包括 Functional Unit(FU,也叫 IS 即 Issue Slots,还可以用 ALU、PE、RC 等词代替,本质是进行数据运算的计算单元
) 、片上互联网络 on-chip interconnect、RF(Register Files) 、配置内存 Configuration Memory。 - CGRA 本质上是通过 interconnect 连接的 word-level 处理元件阵列。FU 和 interconnect 都可以根据片上配置存储器内容在每个周期内重新配置。每个周期 FU 可以执行不同的操作,route 可以按特定路线发送,这些都需要由配置内存进行配置。
- 因此,编译器需要通过设置配置内存,以时空方式将应用程序的计算密集型循环内核映射到 CGRA 上。
- 由若干个 Tile 组成,其中 Tile 主要包括 Functional Unit(FU,也叫 IS 即 Issue Slots,还可以用 ALU、PE、RC 等词代替,本质是进行数据运算的计算单元
-
Why
-
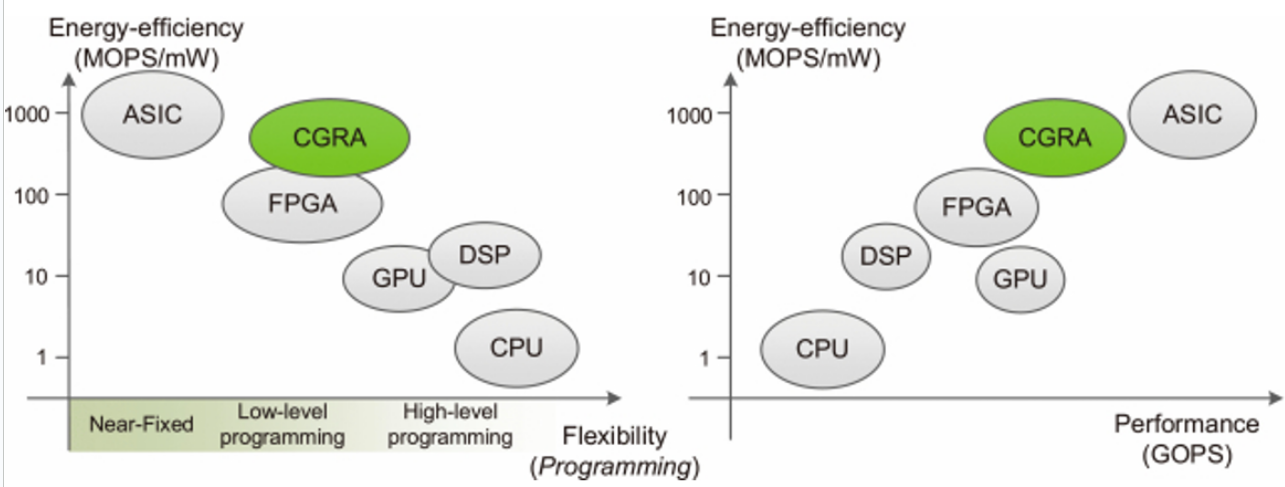
Compared with FPGA: FPGA 是 bit-level(fine-grained),CGRA 是 word-level(coarse-grained)。FPGA 只能空间上复用,而 CGRA 可以在时间和空间上复用。因此 CGRA 的复杂度从架构转移到了编译器。
- 因为我们的配置内存是有限的,当遍历完所有配置后,就会回到第一个配置,这样就可以实现时空复用。CGRA 的时空复用的特性,决定了它非常适合循环的加速。
-
Compared with ASIC: ASIC 是固定功能,CGRA 是可重构的。
- Compared with CPU: CGRA 的架构简单,运行时只需要按照计划的配置进行处理(计算、通信
) ,不需要复杂的控制逻辑,提高了 energy efficiency。
-
Example
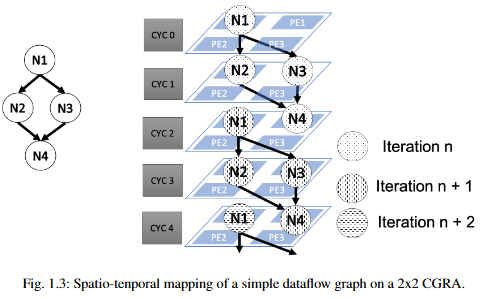
这里展示了通用矩阵乘法的数据流图,每个节点都有对应的时空坐标。
Architecture¶
-
FU
- 不同的 CGRA 根据其不同的应用场景可以存在不同的 FU 的结构。FU 可以进行简单的运算(如加法、乘法、移位
) ,也可以进行复杂的计算(由基本运算组合,如 MulAdderShifter) 。需要注意的是 FU 上的操作要在一个周期内完成,因此复杂的运算可能导致导致更长的 critical path。 - FU 的输入可以来自 RF、其他 Tile 的输出(通过互联网络得到
) ,内存。
- 不同的 CGRA 根据其不同的应用场景可以存在不同的 FU 的结构。FU 可以进行简单的运算(如加法、乘法、移位
-
配置内存
- 每个周期每个 PE 会从配置内存中读取控制信号,以决定本周期的操作。配置内存的大小决定了 CGRA 的复杂度,也决定了 CGRA 的时空复用能力。
- 一个特殊情况是,只有一个配置字的 CGRA,称为 spatial CGRA,这种 CGRA 基本简化为 FPGA,除了有粗粒度的可重构单元。
-
内存
- 片上内存通常用 Scratchpad Memory(SPM) 表示,可以提供给整个 Tile 阵列数据。CGRA Tile 执行加载和存储操作,以加载输入数据,并将计算数据存储回片上存储器中。
-
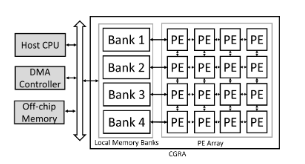
但实际上,受限于内存的带宽限制,并不是所有的 Tile 都可以直接访问内存。有时会使用 multi-back memory SPM,即多组存储器 SPM,用于增加数据吞吐量,即 SPM 数据存储器与 Tile 阵列之间的并行访问次数。
4-bank SPM CGRA
-
SPM 完全由软件控制,因此 SPM 与外部(片外内存)的交互需要由编译器生成的指令控制。一般是通过 DMA 控制。
-
片上网络
- 在每个 Tile 中,都有从输入端口到输出端口的路由路径。此外,数据可以存储在 RF 中,同时等待处理或进一步路由。
Homogeneous vs Heterogeneous
- 同构 CGRA 中,每个 Tile 具有相同的功能。异构 CGRA 中,每个 Tile 可以有不同的功能,例如在 DNN 中可以让部分 Tile 专门用于 MAC(乘法累加)计算,这些特殊的 Tile 可能成本高昂。
- 同时大部分 CGRA 在内存访问上都是异构的,没有必要让所有 Tile 访问片上数据存储器,并且 SPM 的端口数量也有限,限制了并行访问的数量。
tight vs loose coupling
需要注意的是,CGRA 需要与 CPU 耦合才能执行完整的应用程序。主机处理器负责运行非循环代码、配置 CGRA 以及启动从主存储器到 CGRA 本地存储器的 DMA 数据传输;CGRA 负责执行循环内核。因此实际上 CGRA 分为 tight coupling, loose coupling,我们这里只关注松耦合的情况。
- 松耦合:CGRA 是单独的模块,CPU 通过 DMA 来写入 SPM 和控制内存,随后 CGRA 自行处理数据。
- 紧耦合:CGRA 是主 CPU 的一部分,处理器与可编程阵列融为一体,可以用来作为 VLIW 处理器。具体可见知乎文章“CGRA 小调研”的介绍。
Work Flow
在每个周期中,
- Tile 从配置存储器中读取配置。
- 配置相应的模块,例如 ALU、开关和 RF 端口。
- 然后 Tile 执行操作。
- 并通过片上网络将数据传递给其他 Tile。
Compilation for CGRAs¶
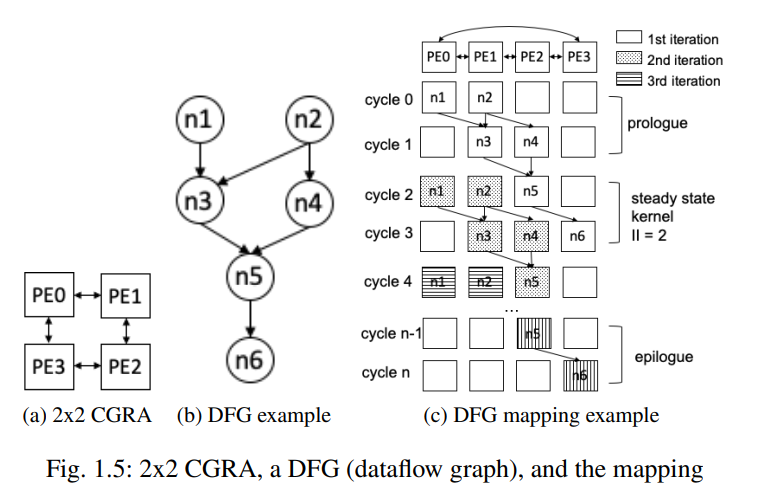
给定来自应用程序和 CGRA 架构的循环,编译的目标是将循环映射到 CGRA(即,生成固定周期数的配置)以最大限度地提高吞吐量。通常,这种编译在 CGRA 世界中被称为 Mapping 映射。循环表示为数据流图 (DFG),其中节点表示操作,边表示节点之间的依赖关系。
Modulo Scheduling¶
-
映射分为三部分:序幕 prologue、稳态内核 steady state kernel 和尾声 epilogue。
- 序幕和尾声仅在循环执行的开始和结束时执行一次。
- 稳态内核是重复的,包括来自一个或多个迭代的所有操作。
- 内核的计划长度称为初始间隔(Intial Interval, II
) ,表示连续循环迭代启动之间的周期数。对于具有大量迭代的循环,执行时间由(II)值主导。
-
给定 DFG 和 CGRA,mapper 首先计算 MII(Minimum Initial Interval),这个值会被设为 resource-minimal II 和 recurrence-minimal II 的最大值。
- resource-minimal II:在给定的资源约束下,最小的 II。由 Tile 的个数、以及 DFG 的节点个数决定。我们假定一个 Tile 节点可以处理一个 DFG 节点的操作,因此 \(II = \frac{\# FUs}{\# nodes}\)。
- recurrence-minimal II:在给定的数据依赖约束下,最小的 II。由 DFG 的数据依赖关系决定,我们可以通过遍历一遍 DFG 得到。
- DRESC 编译器首次讨论了使用模调度将应用程序的计算密集型循环内核映射到 CGRA 的问题。该算法从上面的 II 开始尝试调度循环。如果失败,则尝试使用连续较大的 II 值。
Example
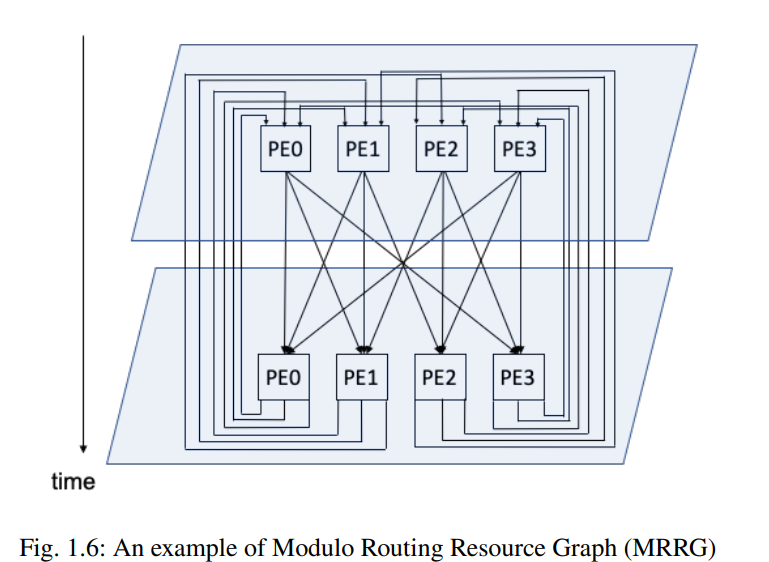
MRRG¶
常用的工具是 MRRG(Modulo Scheduling and Modulo Routing Resource Graph)。MRRG 是一个有向图,节点表示资源(如 FU、RF、interconnect
- \(G_{II}\), 其中 \(II\) 表示 initiation interval。
- 对于图里的节点,都是一个元组 \((n,t)\),其中 \(n\) 表示 CGRA 里的资源,\(0\leq t\leq II-1\) 表示表示当前周期。
- 对于图里的边 \(e=(u,v)\) 则 \(u=(m,t), v=(n,t+1)\),那么 \(e\) 表示在周期 \(t\) 时资源 \(m\) 到周期 \(t+1\) 时资源 \(n\) 的连接。
Example
II 为 2 时的 MRRG:
TODO
CGRA Mapping Approaches¶
-
Heuristic-based
- 通过启发式算法,如模拟退火、SPR、进化算法等。
-
Mathematical Optimization Techniques
- 通过 ILP、SAT、图论等方法求解。
TODO
Challenges¶
Control Flow¶
CGRA 一直都面临一个挑战,就是执行具有 if-then-else(ITE) 构造的循环。现在常用的方法有:
-
full prediction 完整预测
- 完整预测中,我们会将对同一变量的不同分支上的更新操作映射到同一 Tile。由于在运行时只会执行其中一个操作,因此在最大时间之后,PE 中会存在正确的输出值。如果仅在 ITE 的一个路径中计算输出,则必须在先前更新相同变量的 Tile 上计算输出。这样做是为了在 ITE 之后,对于每个变量,都有一个唯一的 Tile,该 Tile 具有其值,因此不需要 select 操作。
- 完整谓词 DFG 的操作节点数为 2n,但 2n 个节点中的每一个都有放置约束。对操作放置的严格约束非常严格,并且严重降低了性能。
Example
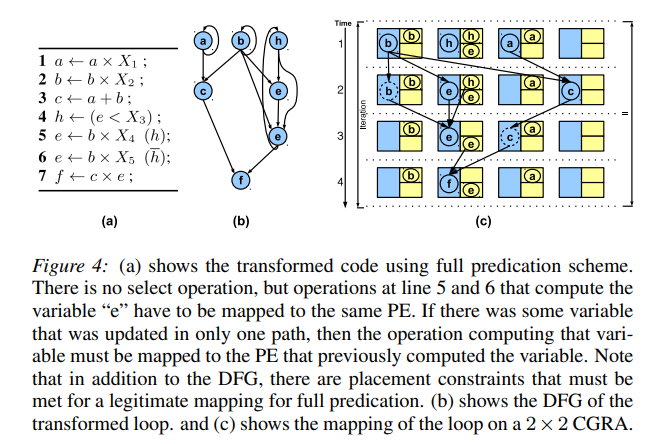
-
partial prediction 部分预测
- if-part 和 else-part 被映射到不同的 Tile 上。如果在 if 部分和 else-part 中都更新了相同的变量,则通过根据分支条件的评估从必须执行的路径中选择输出来计算最终结果。
- 为此,需要有一个特殊的操作,select(or conditional move),该操作接收分支条件的结果(通过谓词网络)和两个输出以选择正确的条件。如果变量仅在一个路径中更新,则仍需要选择操作来在旧值(ITE 之前,甚至是上一次迭代中的值)和新值之间进行选择。
- 如果 ITE 每条路径上有 n 个操作,那么最坏情况部分预测需要 3n 个节点
。 (if 和 else 分支各 n 个,以及 n 个 select 操作)
Example
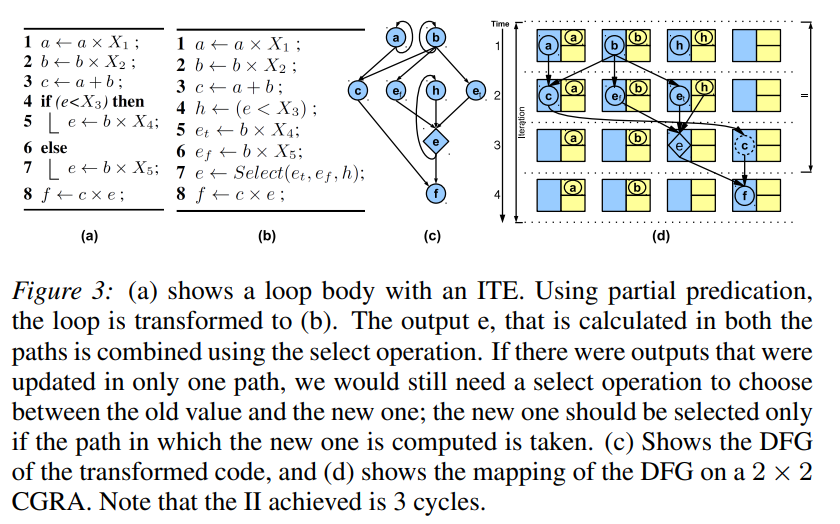
-
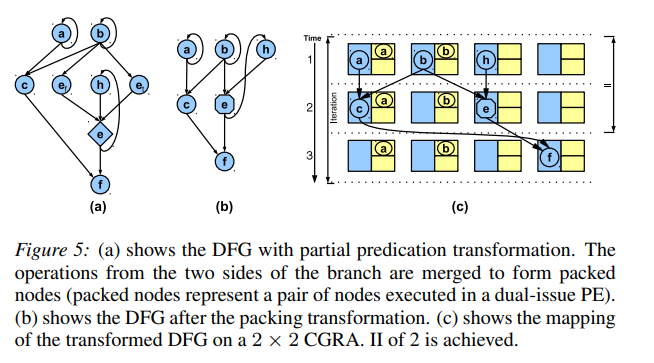
dual-issue scheme 双发射
- 该方案通过同时向 Tile 发出两条指令来缓解加速条件的问题,一条来自 if 路径,另一条来自 else 路径。根据条件操作的结果,在运行时只执行其中一个操作。此方法也不需要选择操作。
- 具体算法和编译器的细节可见论文 Branch-Aware Loop Mapping on CGRAs。
Example
Design Flow¶
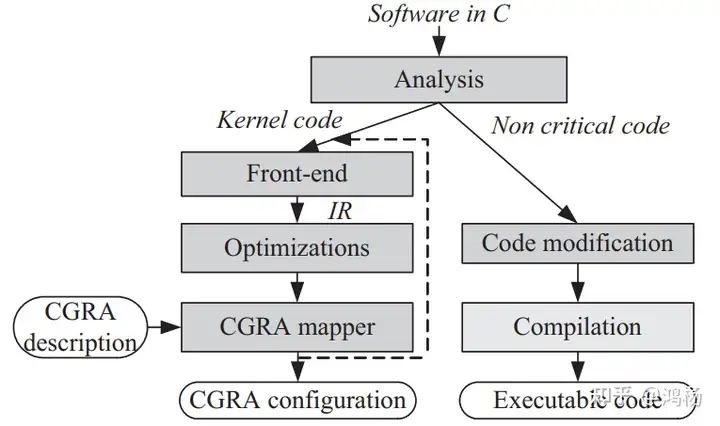
- 首先对程序分析找出最复杂、最需要优化的 kernel 部分(一般是循环
) 。 - 将要优化的代码送入前端编译器,转为 IR。
- 根据 IR,结合我们对 CGRA 的描述(即结构信息、资源
) ,送入 mapper 并得到具体的配置信号、数据流图。 - 将配置信号送入 CGRA 的配置内存,并设计对应的 CGRA 电路。与非 kernel 部分协同处理。
TODO: OpenCGRA
TODO¶
- Compile,MRRG
- Control flow
- OpenCGRA work flow、CGRA-Mapper、MLIR