Instruction-Level Parallelism (ILP)¶
约 3250 个字 19 行代码 29 张图片 预计阅读时间 11 分钟
Dynamic Scheduling¶
Example
前两条指令存在数据依赖,DIV 语句的执行时间一般较长。那么前两条指令就会等待除法完成,顺序执行里面后面的指令也会跟着等(但其实和除法没有关系

- Idea: Dynamic Scheduling
- Method: out-of-order execution
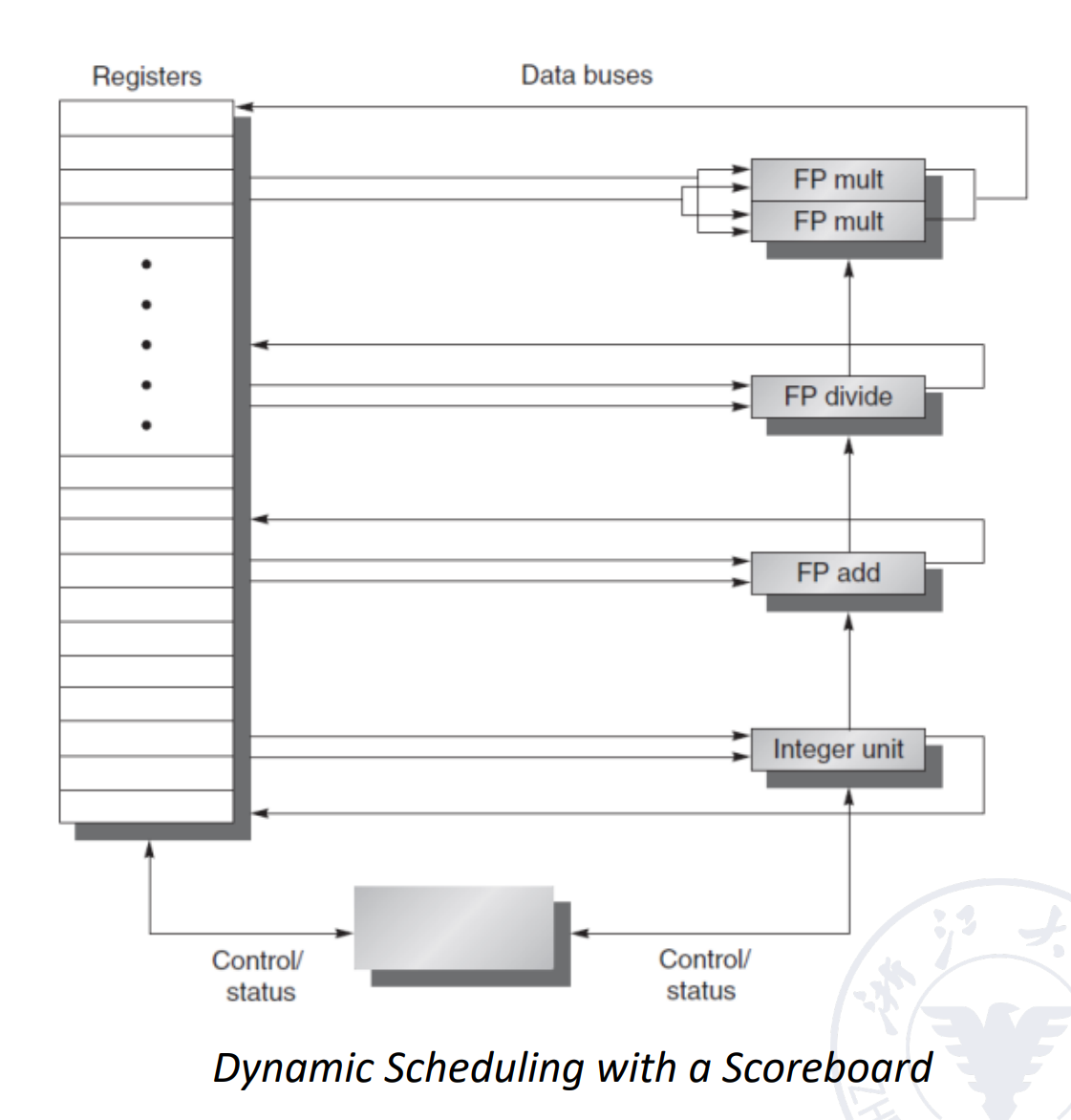
- load/store 也属于整数运算部件
- scoreboard 记录当前系统所有的状态(指令进行到什么状态,功能部件当前被哪条指令使用,寄存器组,指令用了哪些寄存器 ...)
在之前的顺序流水线实现中, ID 阶段,我们会检测结构冒险和数据冒险。如果都不会发生,那么就会将这条指令放到下一阶段 EX。
我们现在希望减弱检测条件,只要没有结构冒险(结构冒险是无法解决的
we essentially split the ID pipe stage of our simple five-stage pipeline into two stages:
- Issue(IS): Decode instructions, check for structural hazards. (in-order issue)
- Read Operands(RO): Wait until no data hazards, then read operands. (out of order execution)
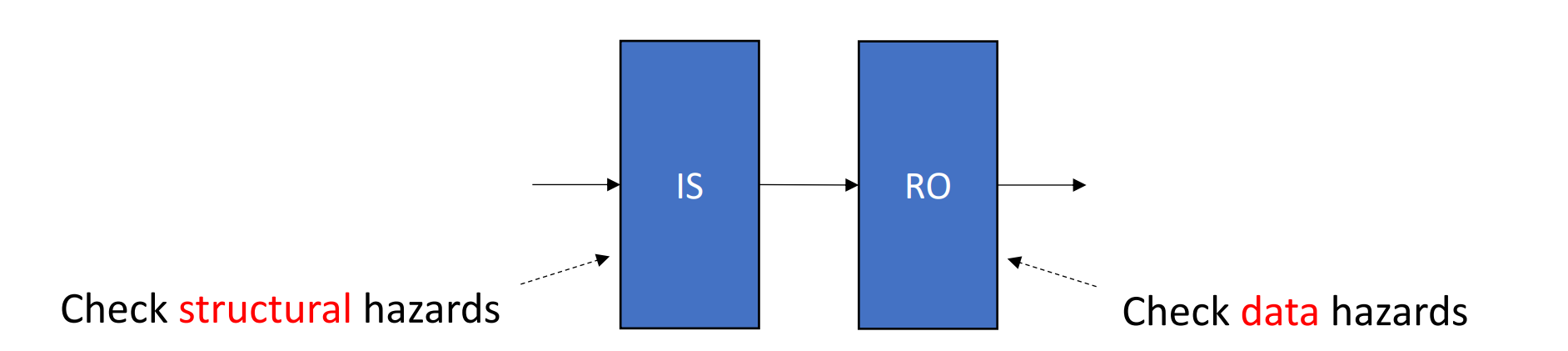
IS 一定是顺序取,RO 不一定顺序(只要没有数据冒险就可以执行,有冒险的等待、没有冒险的执行,这里就出现了乱序
乱序只能加速,不能修改我们本来的程序。因此我们执行可以乱序执行,但是提交的时候必须按顺序提交。
- Scoreboard algorithm is an approach to schedule the instructions.
- Robert Tomasulo introduces register renaming in hardware to minimize WAW and WAR hazards, named Tomasulo’s Approach.
Scoreboard algorithm¶
The basic structure of a processor with scoreboard:
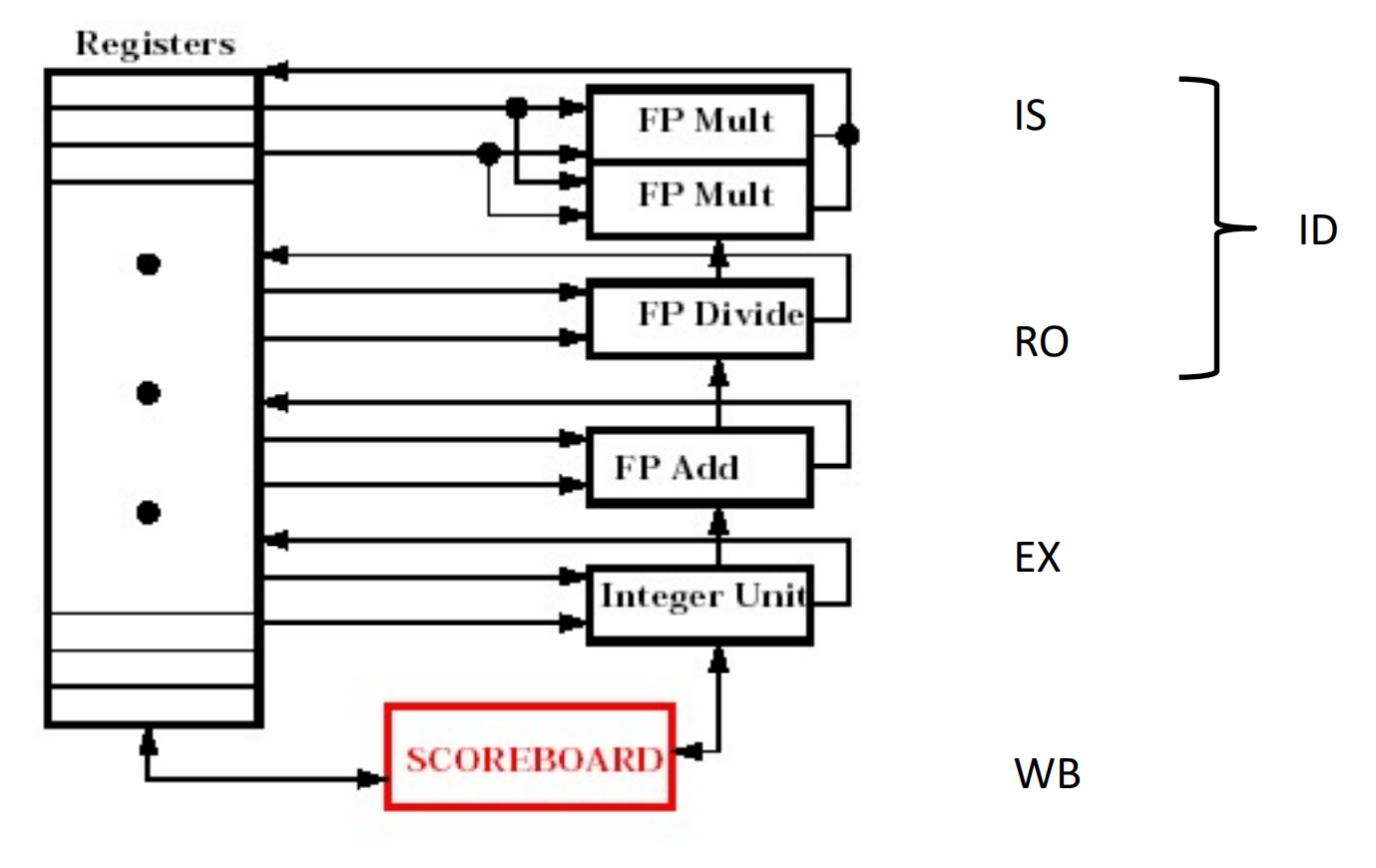
为什么有两个乘法部件,一个除法部件,一个加法?
因为加减法快,除法出现的概率小。乘法较多同时时间慢,所以有两个部件。
表是实时更新的。当指令流出
- Instruction Status 记录每条指令执行到哪一步。
- Function Component Status
- Register Status
Example
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F2, F6
FDIV.D F10, F0, F6
FADD.D F6, F8, F2
-
Instrucion Status:

此时指令 1 结束,scoreboard 上没有其相关的信息。指令 2 还没有 WB,后面的 3、4 需要用到 2 的结果 F2,因此指令 3、4 只是完成了 IS 阶段,还没有执行 RO 阶段(存在数据冒险
) 。指令 5 用到 3 的结果,也不能进入 RO。指令是 6 ADD 加法操作,此时指令 4 是 SUB,也会用到加法运算单元,因此产生结构冒险,无法进入 IS。 -
Function Component Status:
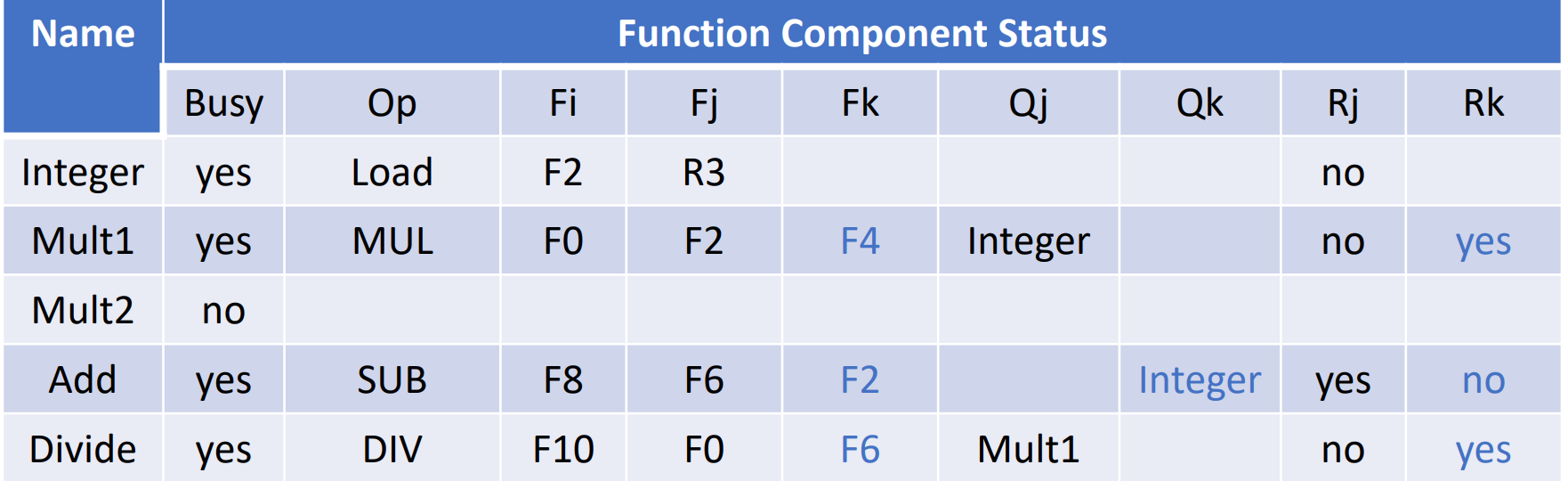
- busy 代表当前这个单元是否有指令正在使用。op 表示这个单元正在被哪类指令使用。
- Fi、Fj、Fk 代表源操作数和目的操作数(Fi 为源,Fj、Fk 为目的
) 。 -
Qj、Qk 代表源操作数来自哪个部件
- 如 Mult1 的 Qj=Integer 说明来自整数部件(此时正在执行 Load 指令)
-
Rj、Rk 代表源操作数的状态
-
yes - operands is ready but no ready.
没读是因为其他的操作数还没有 read。
-
no & Qj=null: operand is read.
-
no & Qj!=null: operand is not ready.
其他指令会修改这个操作数,而且还没有执行完毕。
-
-
Register Status
Fi 这一列加上 Op 这一列组合成了这张表,表示这个寄存器将被什么指令修改。

Question
承接之前的表,因为乘法执行较慢,因此指令 4 比指令 3 先执行完开始 WB。
写出这个时候的另外两张表。

Answer
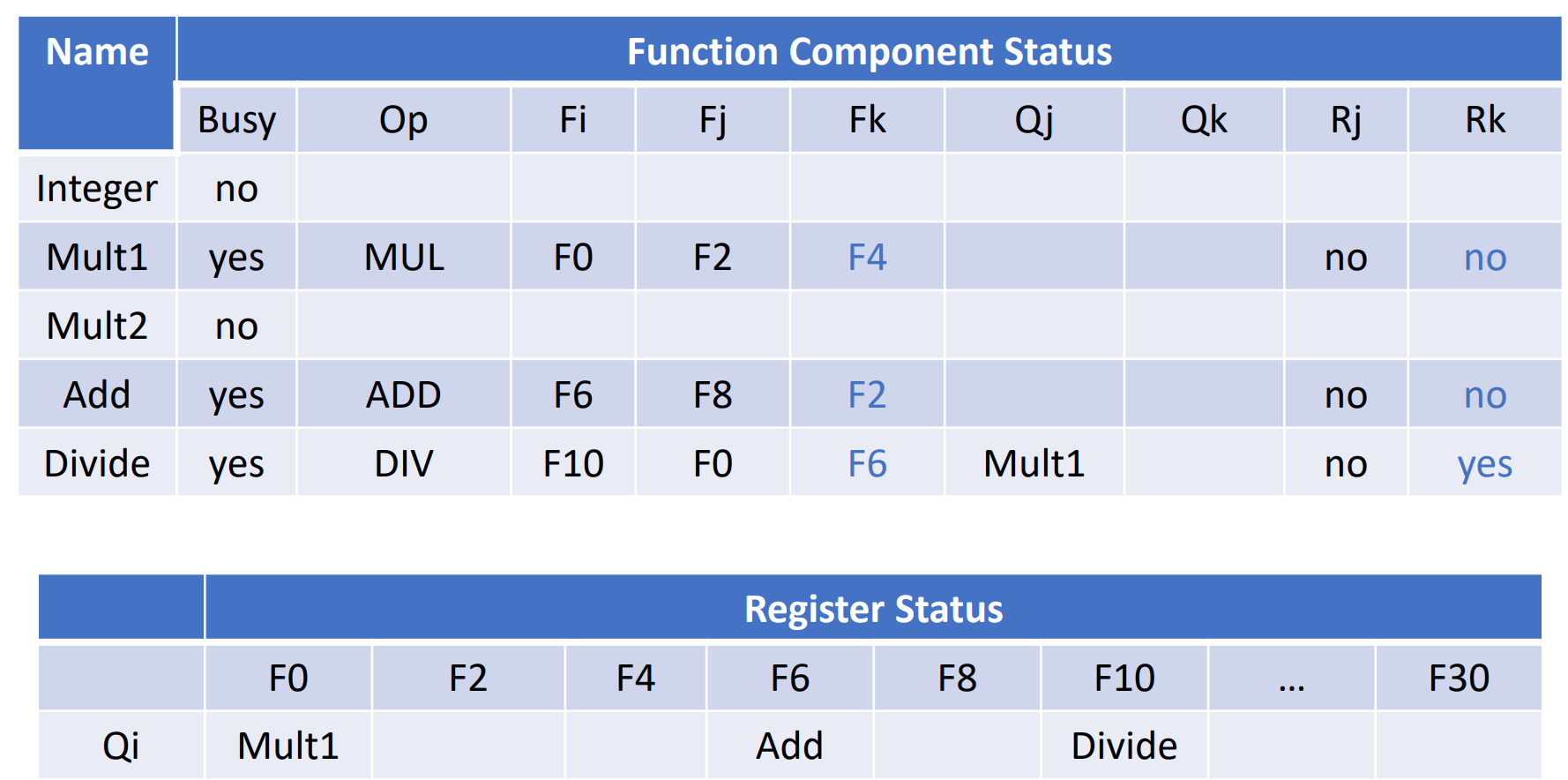
注意到在这之后,最后一条 ADD 指令必须等到 DIV 指令 RO 之后才能 WB(否则会修改 F6
Scoreboard 算法可以检测出来冲突,但没有解决冲突,还是通过阻塞的方式来解决,scoreboard 上面的信息也比较繁杂,效率不高。
Tomasulo’s Approach¶
These name dependences can all be eliminated by register renaming.
Example

The basic structure of a floating-point unit using Tomasulo’s algorithm:

指令从队列出来(顺序
这里 Reservation Station 的目的是为了一次性放进来多条指令,然后在 Buffer 内完成乱序,即 Buffer 内哪条指令操作数 ready 了就先执行。
此外,在保留站里还要进行 rename,有可能依赖的是另一个保留站里的指令。
- It tracks when operands for instructions are available to minimize RAW hazards;
- It introduces register renaming in hardware to minimize WAW and WAR hazards.
Let’s look at the three steps an instruction goes through:
-
Issue: Get the next instruction from the head of the instruction queue (FIFO)
从队列中顺序取出指令,并放入对应的保留站。进入保留站后,就会进行重命名,消除了 WAR 和 WAW 冒险。
-
If there is a matching reservation station that is empty, issue the instruction to the station with the operand values, if they are currently in the registers.
如果保留站有空位,就将指令放到保留站中。
-
If there is not an empty reservation station, then there is a structural hazard and the instruction stalls until a station or buffer is freed.
如果保留站没有空位,就阻塞等待
。 (即保留站的空闲情况,决定了指令是否流出,而不是由功能部件的空闲情况决定) -
If the operands are not in the registers, keep track of the functional units that will produce the operands.
-
-
Execute
-
When all the operands are available, the operation can be executed at the corresponding functional unit.
保留站里的指令操作数都就绪了,就可以执行。这一步完成了乱序。
-
Load and store require a two-step execution process:
-
It computes the effective address when the base register is available.
Load/Store 指令多一步有效地址的计算,计算好后也会把目标地址放到 buffer 里。
-
The effective address is then placed in the load or store buffer.
-
-
-
Write results
-
When the result is available, write it on the CDB and from there into the registers and into any reservation stations (including store buffers).
通过 CDB 总线将结果写回到寄存器的同时,将结果发到其他所有标记了的保留站里
。 (因此 CDB 也会影响 CPU 的效率,因此现在用多条总线保证效率) -
Stores are buffered in the store buffer until both the value to be stored and the store address are available, then the result is written as soon as the memory unit is free.
-
Example
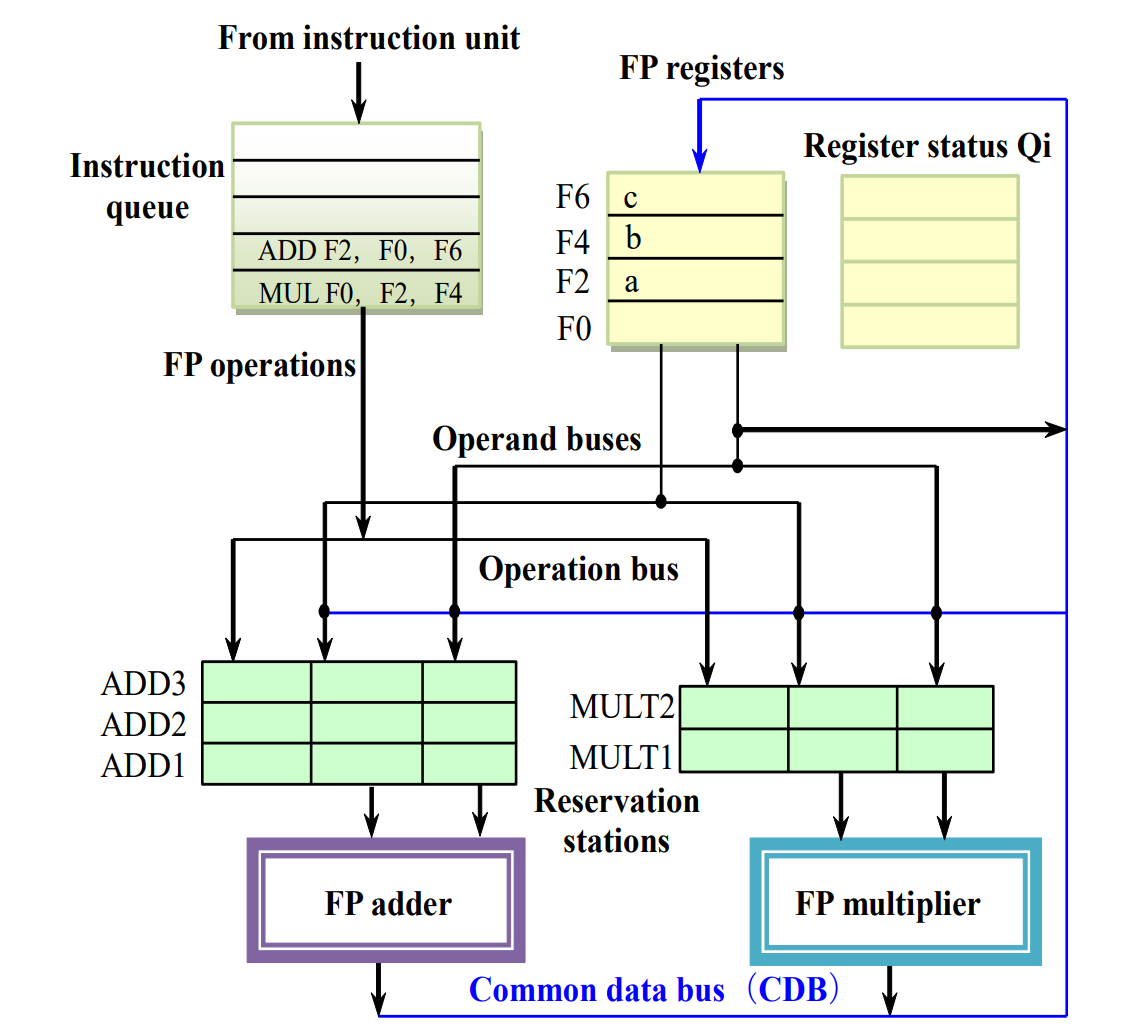
指令进入保留站的时候,如果能读出来数值就直接读,不再用寄存器。此时 MUL F0, F2, F4 的保留站名称就是 MULT1。同时更新 Register Status 表,在目标寄存器 Qi 中填入保留站名称。

同理,进入保留站,重命名,更新表。这里 ADD1 不能计算,因为 MULT1 还没有就绪(这时如果有 ADD2 ADD3 进入那可能先于 ADD1 执行
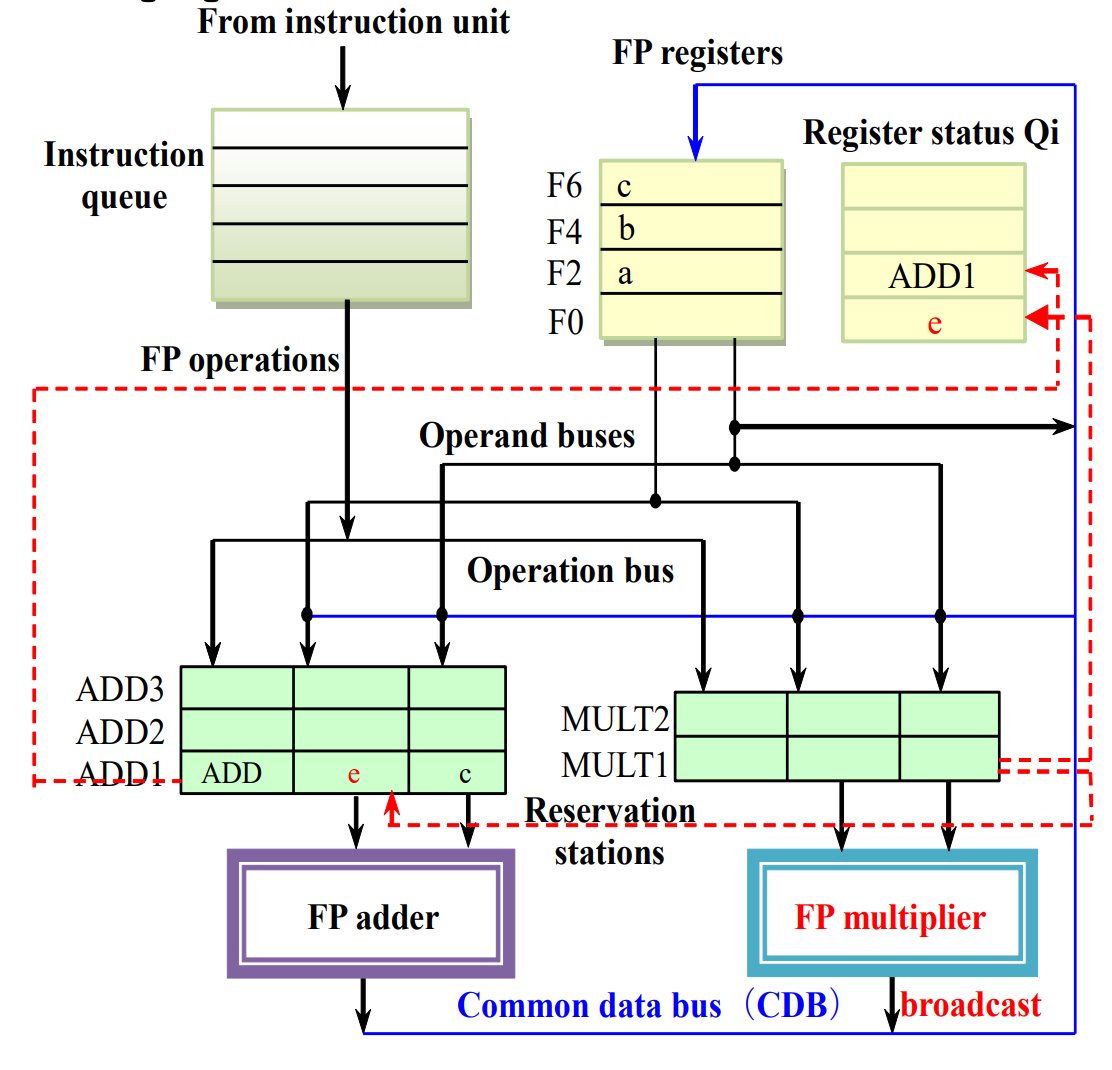
最后我们先执行完 MULT1,然后修改 Qi,并将结果广播到 ADD1。
There are three tables for Tomasulo’s Approach.
- Instruction status table: This table is included only to help you understand the algorithm; it is not actually a part of the hardware.
-
Reservation stations table: The reservation station keeps the state of each operation that has issued.
保留站(功能部件)状态表,记录有多少指令在用。这里相比之前的 scoreboard 做了简化,对于源操作数只有两组数据。
Each reservation station has seven fields:
- Op: The operation to perform on source operands.
- Qj, Qk: The reservation stations that will produce the corresponding source operand.
- Vj, Vk: The value of the source operands.
- Busy: Indicates that this reservation station and its accompanying functional unit are occupied.
-
A: Used to hold information for the memory address calculation for a load or store.
Load/Store 指令的目标地址。
-
Register status table (Field Qi): The number of the reservation station that contains the operation whose result should be stored into this register.
记录保留站的结果往哪里写。
Example
假设这里第一条 Load 指令执行完毕,第二条还没有写结果。指令 3、4、5、6 都可以发射(保留站有空位
FLD F6, 34(R2)
FLD F2, 45(R3)
FMUL.D F0, F2, F4
FSUB.D F8, F2, F6
FDIV.D F10, F0, F6
FADD.D F6, F8, F2

最左侧为保留站名,Qj、Qk 表示数据依赖于哪一条指令。

过了一段时间,下一个状态:
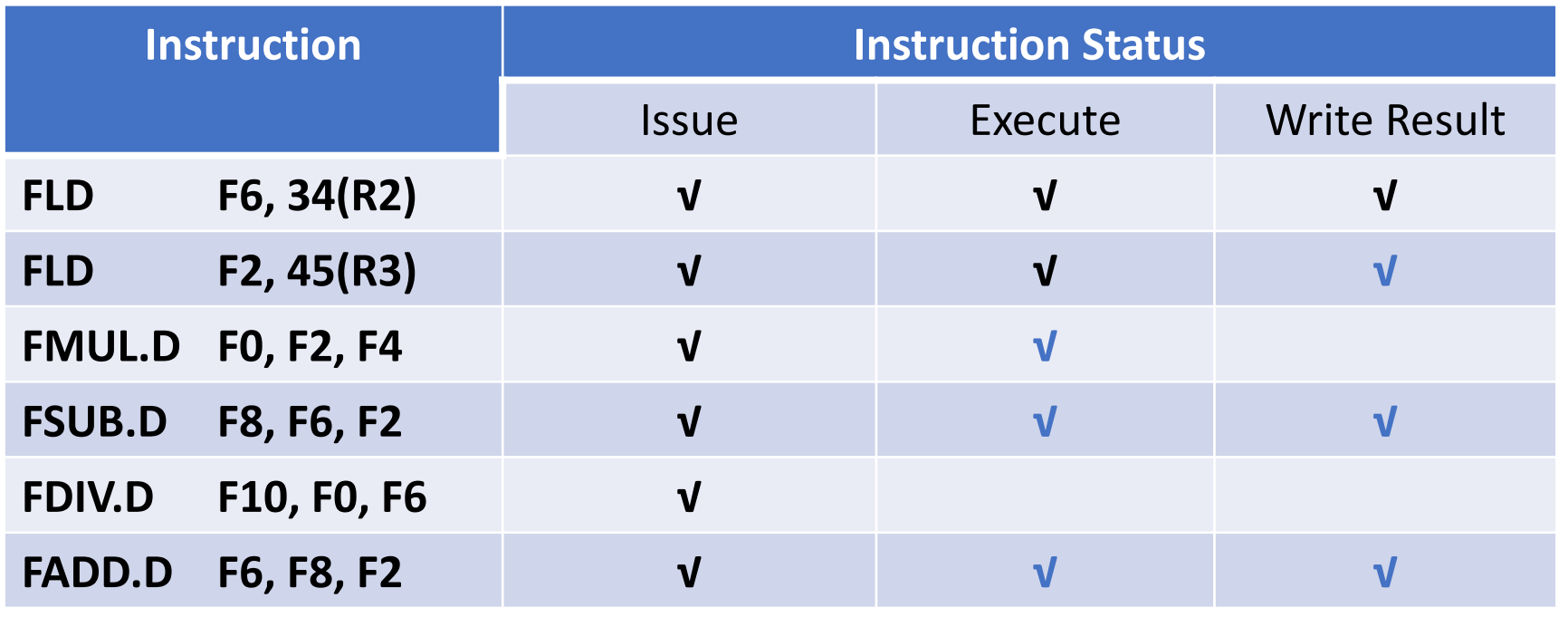
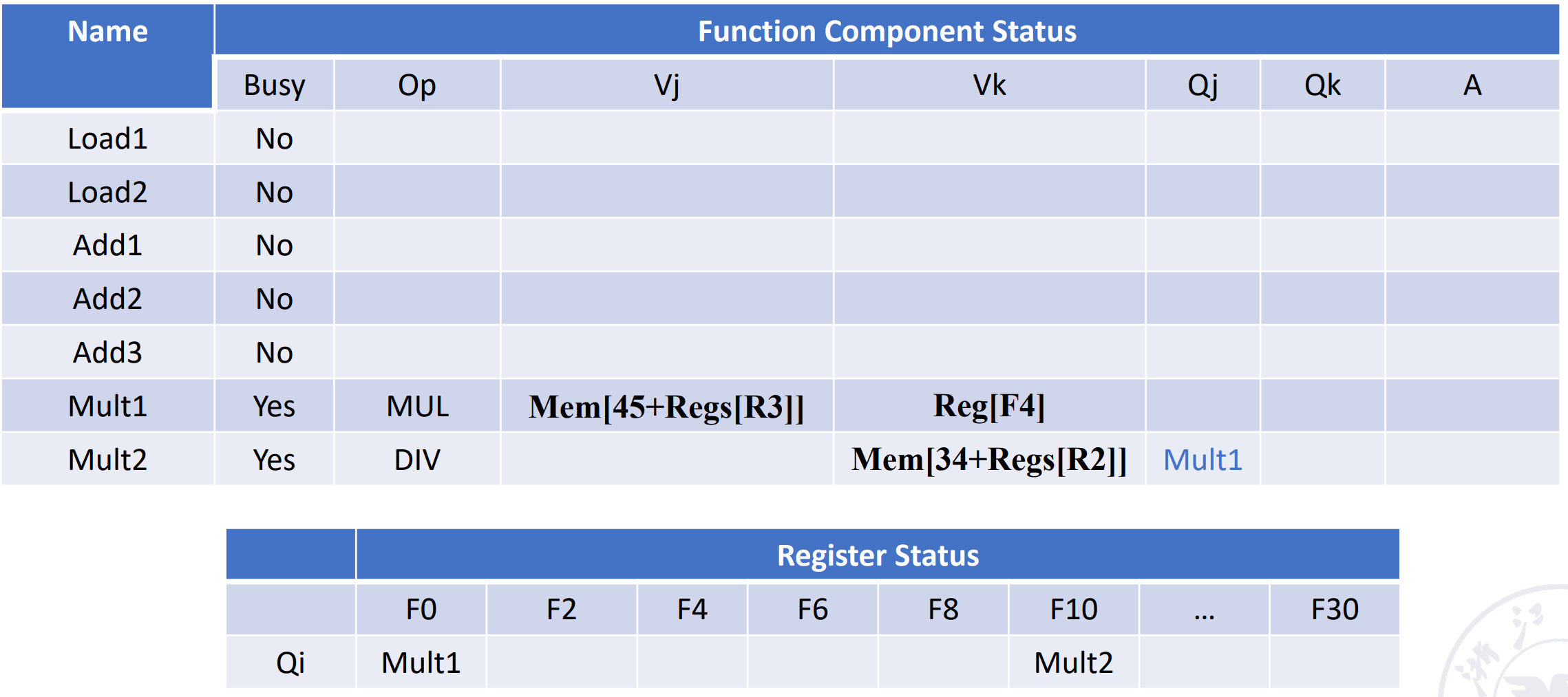
可以看到此时名相关已经不存在了:在指令 5 进入保留站的时候,F6 的值已经读出来并且放到了保留站中,此时无论指令 6 什么时候执行完,写回 F6 的值,都不会影响指令 5 的操作数,因此不再有依赖。也不会出现指令 6 写回了指令 5 才取操作数的情况,因为我们是顺序发射的,指令 5 一定在指令 6 之前发射。
执行结束后指令不能立刻出去,需要按进来的顺序出去,如果后进来的指令先结束,那么就需要等待它前面的指令都结束了才能出去。
Summary
- Tomasula’s Algorithm main contributions
- Dynamic scheduling
- Register renaming---eliminatining WAW and WAR hazards
- Load/store disambiguation
- Better than Scoreboard Algorithm
- Tomasulo’s Algorithm major defects
- Structural complexity.
- Its performance is limited by Common Data Bus.
- A load and a store can safely be done out of order, provided they access different addresses. If a load and a store access the same address, then either:
- The load is before the store in program order and interchanging them results in a WAR hazard, or
- The store is before the load in program order and interchanging them results in a RAW hazard.
- Interchanging two stores to the same address results in a WAW hazard.
- The limitations on ILP approaches directly led to the movement to multicore.
Question
Does out-of-order execution mean out-of-order completion?
Hardware-Based Speculation¶
为了让指令执行完成的顺序也是顺序的,我们添加了一个 reorder buffer。
结果先写到 reorder buffer,在 buffer 里按照指令流出的顺序以此写回寄存器。因此我们在每个指令后面加上一个 commit 状态,当前面的指令都 commit 之后才能 commit。
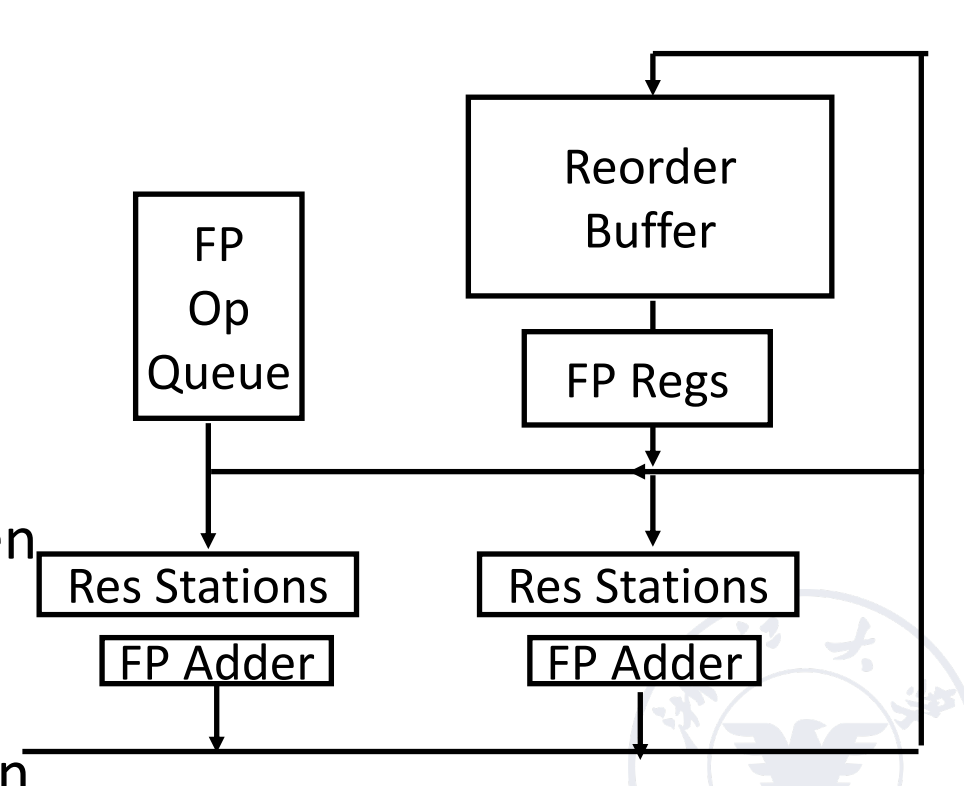
The basic structure of a FP unit using Tomasulo’s algorithm and extended to handle speculation:

- Issue: get instruction from FP Op Queue
- Execution: operate on operands (EX)
- Write result: finish execution (WB)
- Commit: update register with reorder result
Hardware-based speculation combines three key ideas:
- dynamic branch prediction to choose which instructions to execute
- speculation to allow the execution of instructions before the control dependences are resolved (with the ability to undo the effects of an incorrectly speculated sequence)
- dynamic scheduling to deal with the scheduling of different combinations of basic blocks
前面的 IS 和 EX 阶段与 Tomasulo’s Approach 一致,只是在 WB 阶段加了一个 commit 状态,只有当指令 commit 之后才能写回寄存器。
- WB
- The ROB holds the result of an instruction between the time the operation associated with the instruction completes and the time the instruction commits.
- The ROB is a source of operands for instructions, just as the reservation stations provide operands in Tomasulo’s algorithm.
-
instruction commit
-
The key idea behind implementing speculation is to allow instructions to execute out of order but to force them to commit in order and to prevent any irrevocable action (such as updating state or taking an exception) until an instruction commits.
把 ROB 结果写到对应的寄存器里。
-
The reorder buffer (ROB) provides additional registers in the same way as the reservation stations in Tomasulo’s algorithm extend the register set.
-
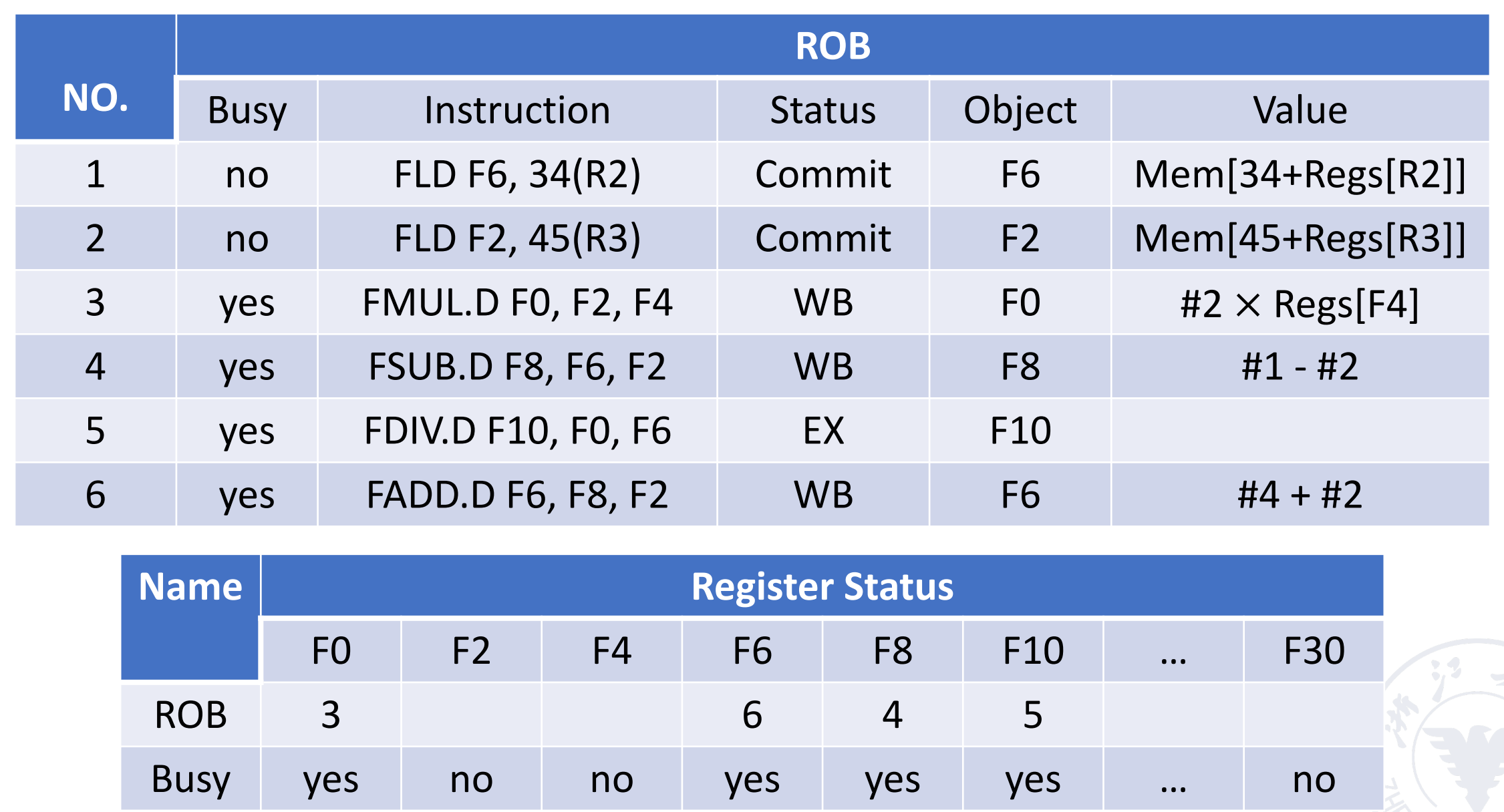
Example
Show what the status tables look like when the FMUL.D is ready to commit.
Dest 这里填的是保留站的名称,而不是寄存器的名称。
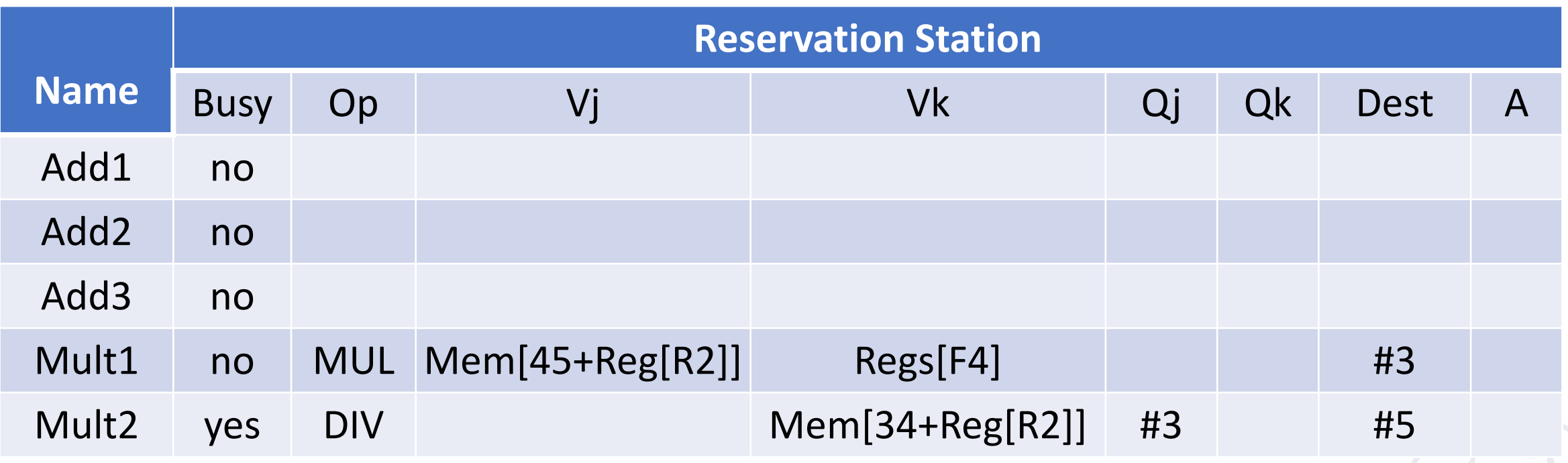
ROB 需要知道我们是从哪条指令来的,标 busy 的是当前正在执行的指令(即还没有 commit)
Practice in Class

实际上加上 ROB 之后,前面的执行和 Tomasulo’s Approach 是一样的,只是多了一个 commit 状态,在后面加一列,需要按照流出顺序提交即可。

- Instructions are finished in order according to ROB.d
- It can be precise exception.
- It is easily extended to integer register and integer function unit.
- But the hardware is too complex.
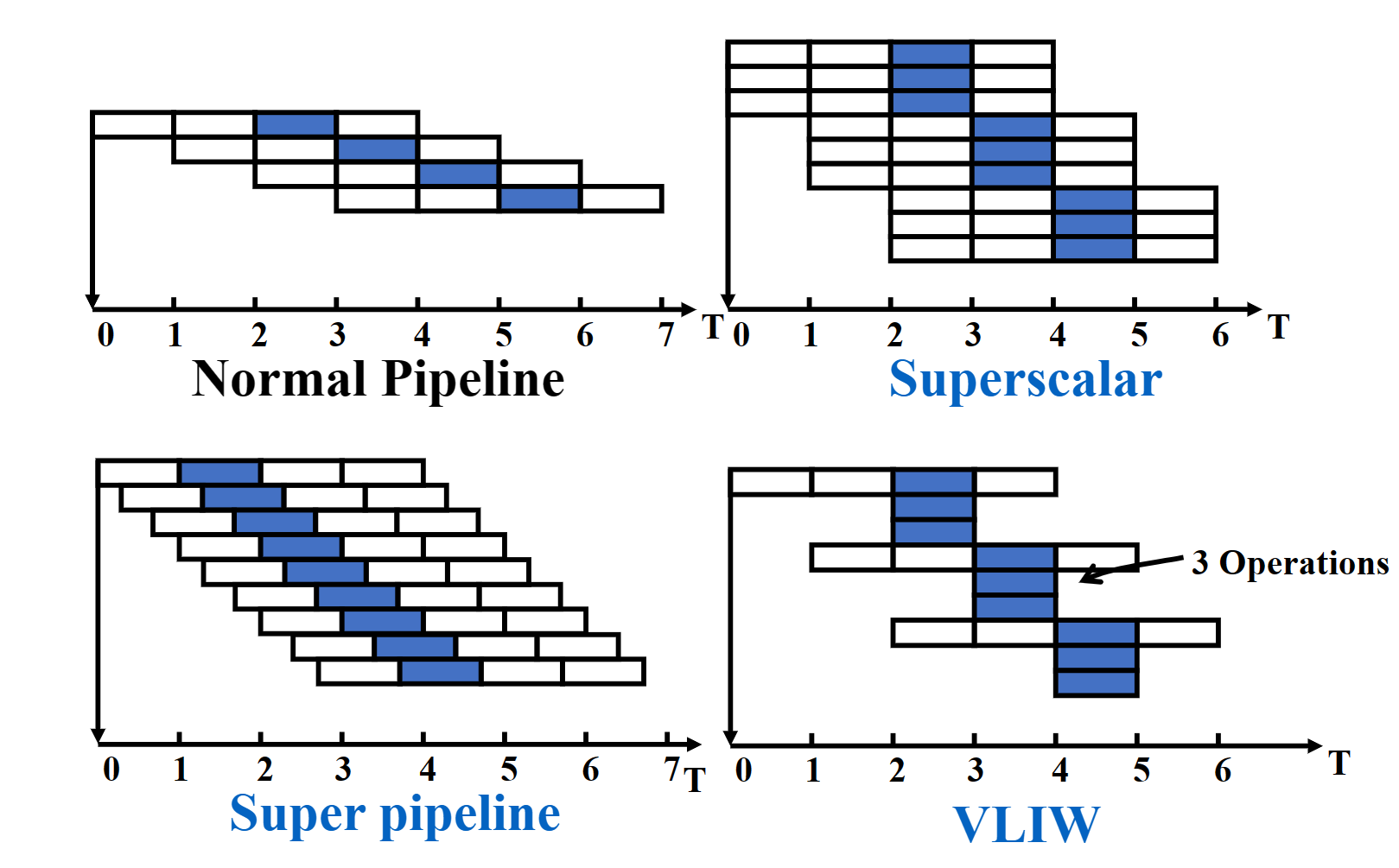
Exploiting ILP Using Multiple Issue and Static Scheduling¶
多流出,即一拍可以流出多条指令。
-
Superscalar
可以分为静态调度超标量和动态调度超标量。静态调度是通过编译器来完成的,动态调度是通过硬件来完成的。
每个时钟周期发射的指令条数可以不一样。
-
VLIW (Very Long Instruction Word)
超长指令字也是通过编译器完成。
每个时钟周期发射的指令条数是固定的。他们组成一条长指令或者一个指令包。
based on static scheduling¶
In a typical superscalar processor, 1 to 8 instructions can be issued per clock cycle.
我们要进行结构冒险和数据冒险的检测。需要注意的是,如果遇到了分支跳转指令,那么只流出这一条,不能和其他指令一起流出。如果处理器有分支预测,那么下一个周期就可以根据预测结果进行发射;如果不带预测,我们就需要等待分支结果,然后再发射。
Example
- Assumption: Two instructions flow out every clock cycle:
- 1 integer instruction + 1 floating-point operation instruction
- Among them, load, store and branch instructions are classified as integer instructions.

based on dynamic scheduling¶
Extended Tomasuloalgorithm: supports two-way superscalar
指令顺序进入保留站。分开处理
Example
Loop:
FLD F0, 0 (R1) // Take an array element and put it into F0
FADD.D F4, F0, F2 // add the scalar in F2
FSD F4, 0 (R1) // storeresult
ADDI R1, R1, 8 // increment pointer by 8 //(each data occupies 8 bytes)
BNE R1, R2, Loop // If R1 is not equal to R2, it means it is
//not over yet, move to Loop to continue
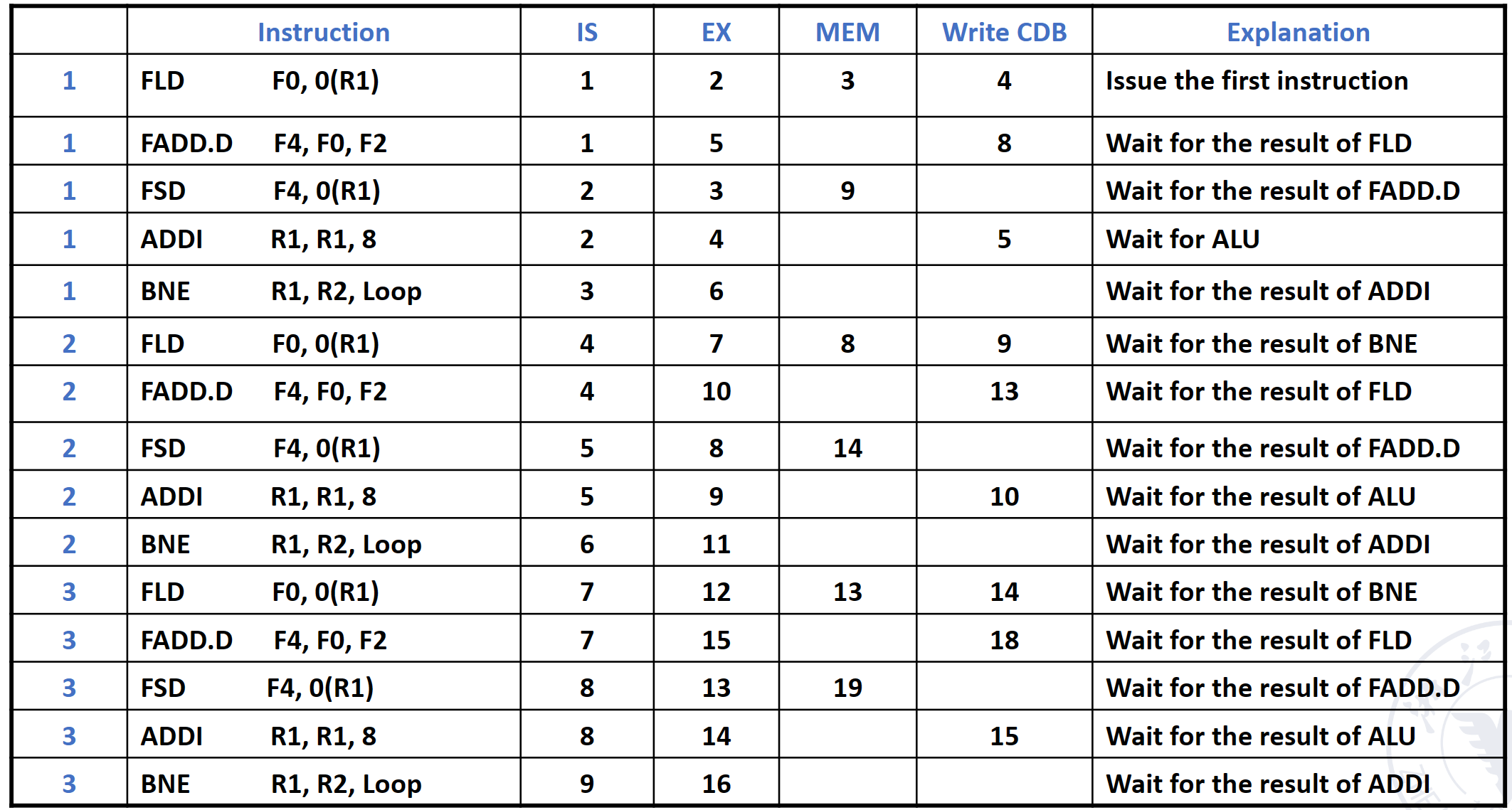
- The program can basically reach 3 beats and 5 instructions
- IPC=5/3=1.67 items/beat.
- the execution efficiency is not very high.
- A total of 15 instructions were executed in 16 beats.
- The average command execution speed is 15/16=0.94 per beat.
Very long instruction word technology(VLIW)¶
Assemble multiple instructions that can be executed in parallel into a very long instruction.
At compile time, multiple unrelated or unrelated operations that can be executed in parallel are combined to form a very long instruction word with multiple operation segments.
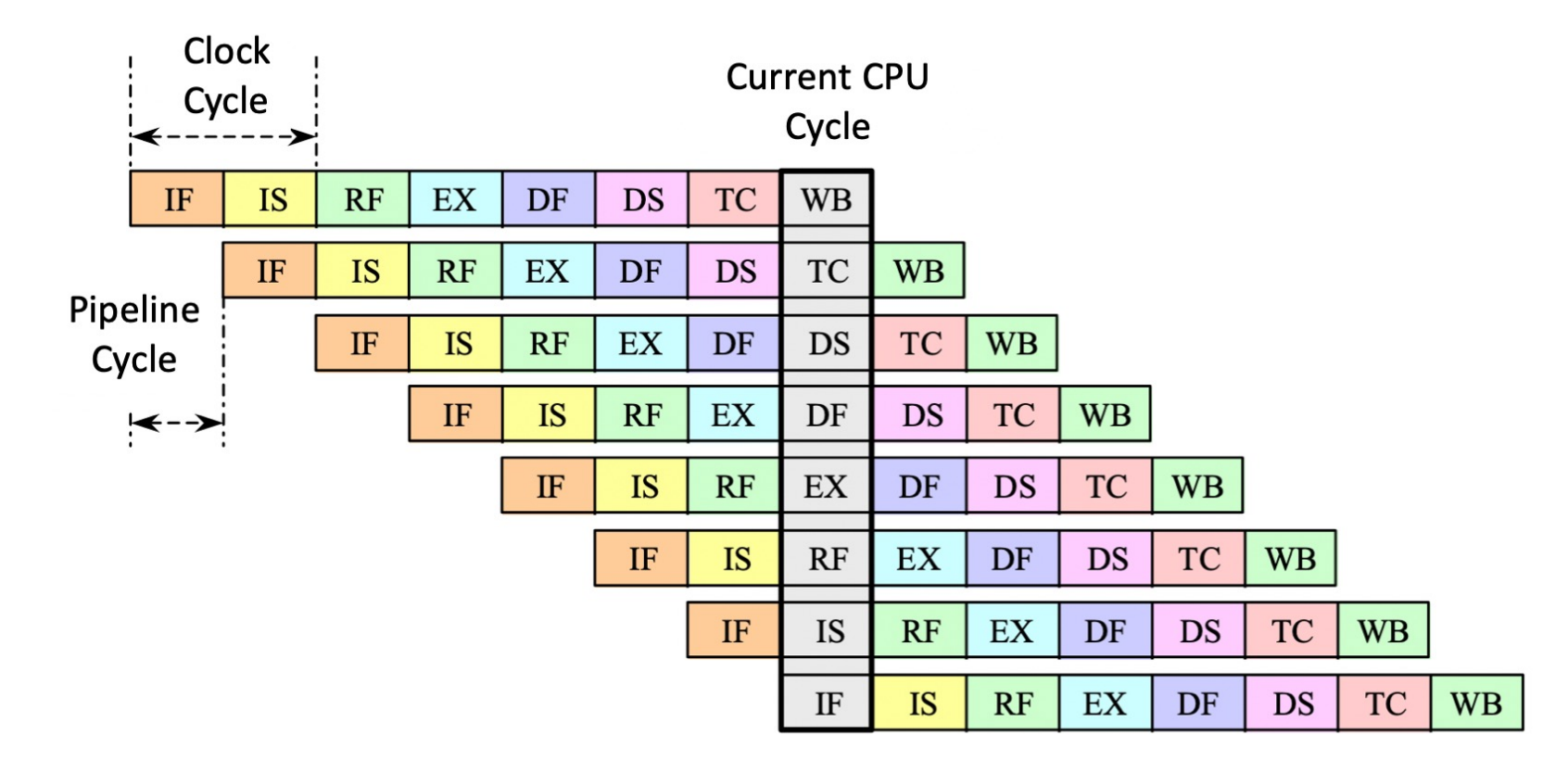
Superpipelining processor¶
A pipeline processor with 8 or more instruction pipeline stages is called a superpipelining processor.
在一个很小的 \(\delta t\) 时间(小于一个阶段的用时)后就发射下一条指令。

本质是流水线的细分。