Virtual Memory¶
约 3429 个字 26 张图片 预计阅读时间 11 分钟
Introduction¶
代码需要在内存里执行,但是整个程序几乎不会同时被使用。
比如我们的代码在 3 页里,最开始执行时只有第一页在内存里,后面的页需要在需要的时候才会被加载到内存里。即我们可以把还没用到的 code 和 data 延迟加载到内存里,用到时再加载。
Consider ability to execute partially-loaded program
- program no longer constrained by limits of physical memory
- programs could be larger than physical memory
为了实现部分加载,我们有一个虚拟内存(在这门课里和逻辑地址是等价的)的概念,主要靠 Paging 来实现。
Virtual memory is larger than physical memory.
需要注意的是虚拟地址只是范围,并不能真正的存储数据,数据只能存在物理空间里。
Virtual-address Space

Demand Paging¶
Demand paging brings a page into memory only when it is demanded.
-
demand means access (read/write)
当我们要读写这个页的时候,说明需要这个页,这时再把这一页调入内存。
-
if page is invalid (error) -> abort the operation.
- if page is valid but not in memory (physical) -> bring it to memory.
- This is called page fault.
- no unnecessary I/O, less memory needed, slower response, more apps.
Some questions about demand paging:
- Demand paging vs page fault
- What is the relationship?
- What causes page fault?
- User space program accesses an address
- Which hardware issues page fault?
- MMU
- Who handles page fault?
- Operating system
What causes page fault?¶
Example
malloc 最后也会调用 brk(),增长堆的大小。
VMA 是 Virtual Memory Area,brk() 只是增大了 VMA 的大小(修改 vm_end),但是并没有真正的分配内存,只有当我们真正访问这个地址的时候,会触发 page fault,然后找一个空闲帧真正分配内存,并做了映射。
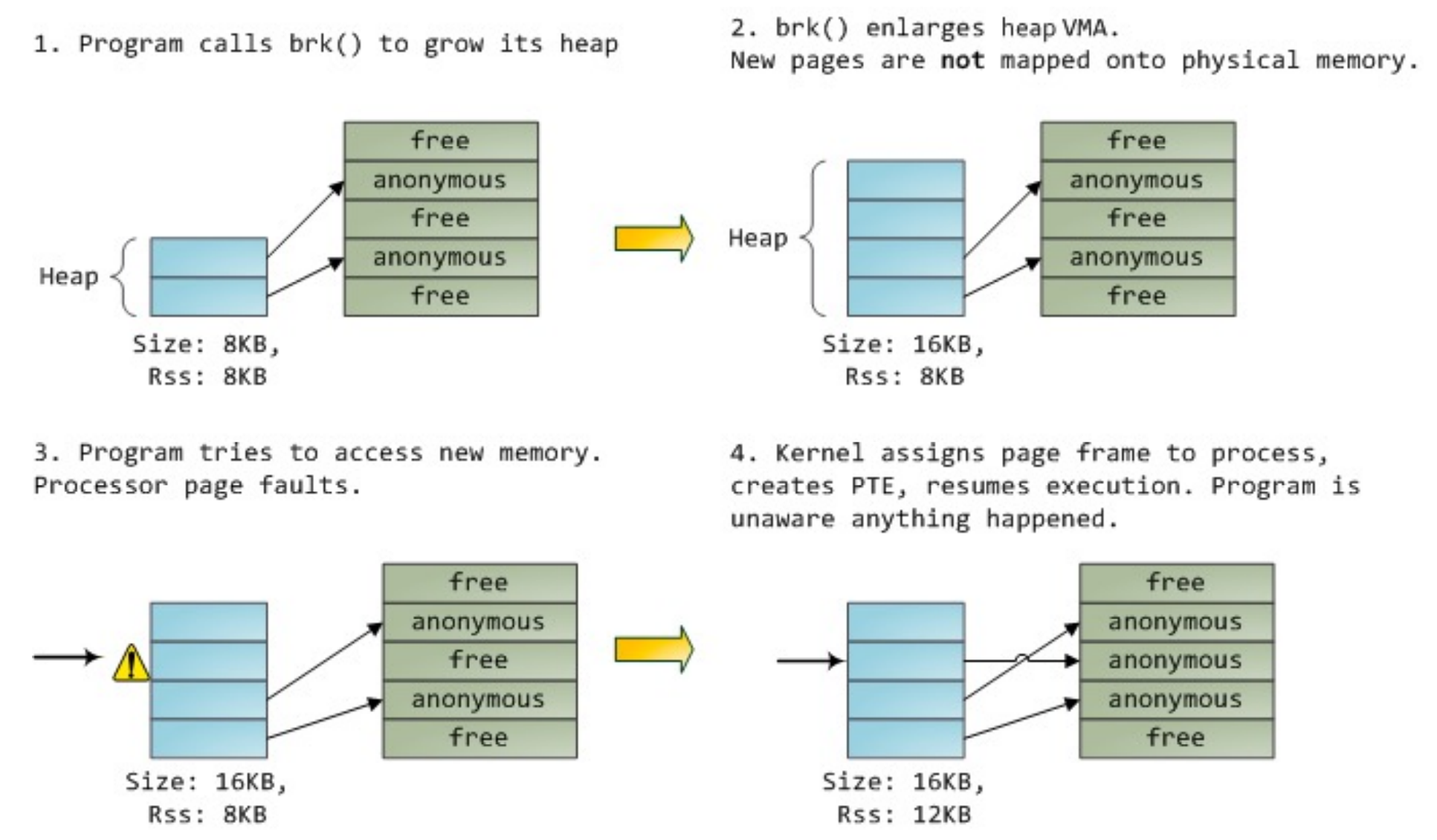
MMU issues page fault.
Each page table entry has a valid–invalid (present) bit
- v -> frame mapped, i -> frame not mapped
- initially, valid–invalid bit is set to i on all entries
-
during address translation, if the entry is invalid, it will trigger a page fault.
即走到页表最低层的时候发现对应的条目的 valid bit 不为 1,说明并没有映射,就触发了 page fault。
Who handles page fault?¶
Linux implementation
Page Fault 出现有两种情况,一种是地址本身超过了 vma 的范围,或者落在 Heap 内但权限不对,这种情况操作系统会杀死进程;一种是落在 Heap 里,而且权限也正确,那么这个时候 OS 就会分配一个空闲帧,然后把这个页映射到这个帧上。
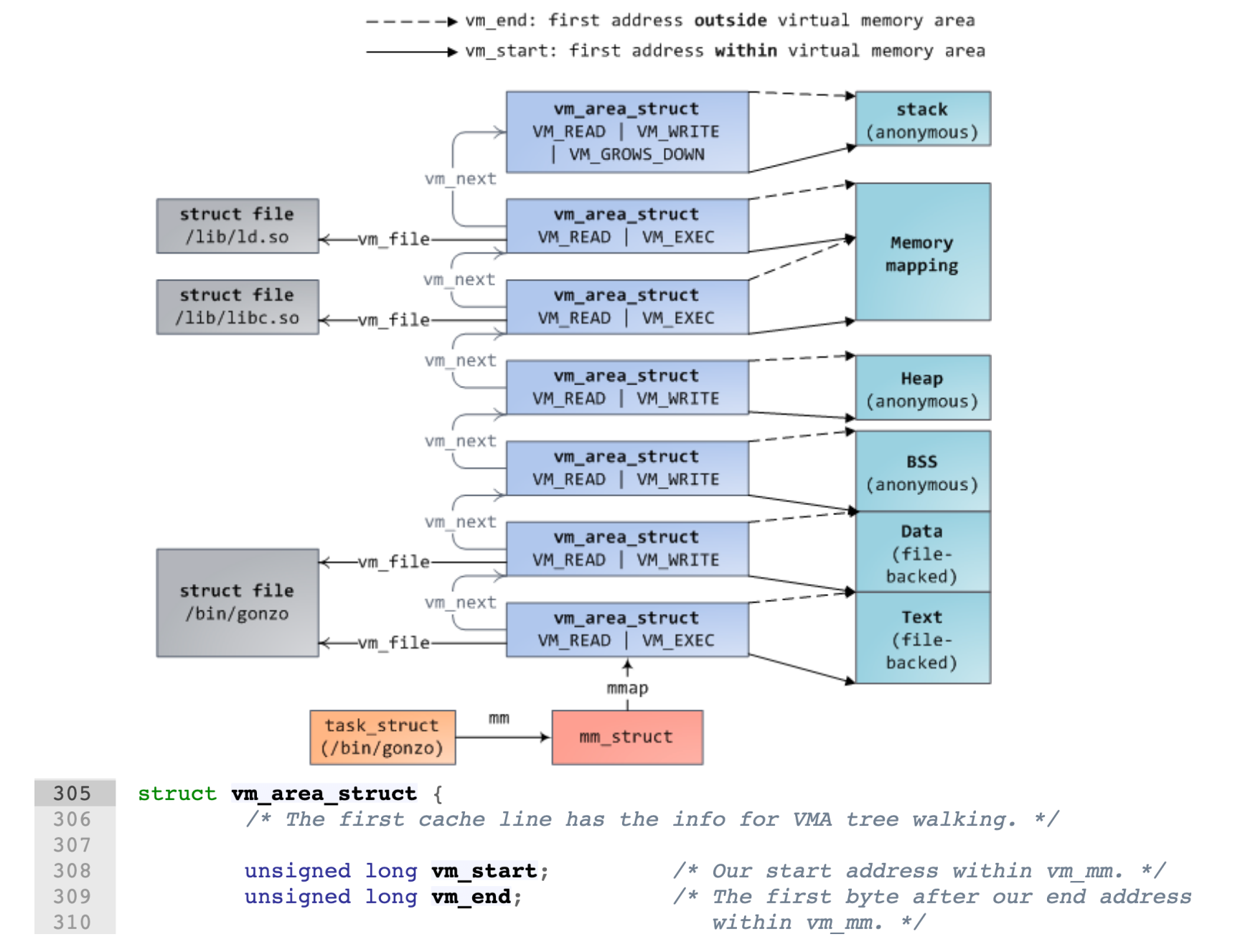
为了判断地址是否落在 vma 里,Linux 使用了红黑树来加速查找。
Page Fault Handling

Page Fault¶
- First reference to a non-present page will trap to kernel: page fault.
-
Operating system looks at memory mapping to decide:
-
invalid reference -> deliver an exception to the process
-
Via check vma in Linux
注意这里的 valid 不是指 page table 的有效,而是访问的地址在 vma 里,而且权限正确。
-
-
valid but not in physical memory -> bring in
- get an empty physical frame
- bring page into frame via disk operation
- set page table entry to indicate the page is now in memory
- restart the instruction that caused the page fault
-
swapper¶
- Lazy swapper: never swaps a page in memory unless it will be needed.
- the swapper that deals with pages is also caller a pager.
- Pre-Paging: pre-page all or some of pages a process will need, before they are referenced.
- it can reduce the number of page faults during execution.
- if pre-paged pages are unused, I/O and memory was wasted.
Get Free Frame¶
Most operating systems maintain a free-frame list -- a pool of free frames for satisfying such requests.
Page fault 发生时,OS 就从 free list 里拿一个空闲帧进行分配。

Operating system typically allocate free frames using a technique known as zero-fill-on-demand -- the content of the frames zeroed out before being allocated.
为了防止信息泄露,在分配时把帧的所有位都置 0。
Stages in Demand Paging – Worse Case
- Trap to the operating system.
- Save the user registers and process state. (
pt_regs) - Determine that the interrupt was a page fault.
- Check that the page reference was legal and determine the location of the page on the disk.
- Issue a read from the disk to a free frame:
5.1 Wait in a queue for this device until the read request is serviced.
5.2 Wait for the device seek and/or latency time.
5.3 Begin the transfer of the page to a free frame. - While waiting, allocate the CPU to other process.
- Receive an interrupt from the disk I/O subsystem. (I/O completed)
7.1 Determine that the interrupt was from the disk.
7.2 Mark page fault process ready. - Handle page fault: wait for the CPU to be allocated to this process again.
8.1 Save registers and process state for other process.
8.2 Context switch to page fault process.
8.3 Correct the page table and other tables to show page is now in memory. - Return to user: restore the user registers, process state, and new page table, and then resume the interrupted instruction.

Demand Paging Optimizations¶
Page fault rate: \(0\leq p\leq 1\).
Effective Access Time(EAT):
\((1-p)\)\(\times\) memory access \(+\) p\(\times\)\((\)page fault overhead \(+\) swap page out \(+\) swap page in \(+\) instruction restart overhead\()\)
Demand Paging Example

- Swap space I/O faster than file system I/O even if on the same device.
- Swap allocated in larger chunks, less management needed than file system.
- Demand page in from program binary on disk, but discard rather than paging out when freeing frame (and reload from disk next time)
- Following cases still need to write to swap space
- Pages not associated with a file (like stack and heap) – anonymous memory
- Pages modified in memory but not yet written back to the file system
- Following cases still need to write to swap space
Copy-on-Write¶
Copy-on-write (COW) allows parent and child processes to initially share the same pages in memory.
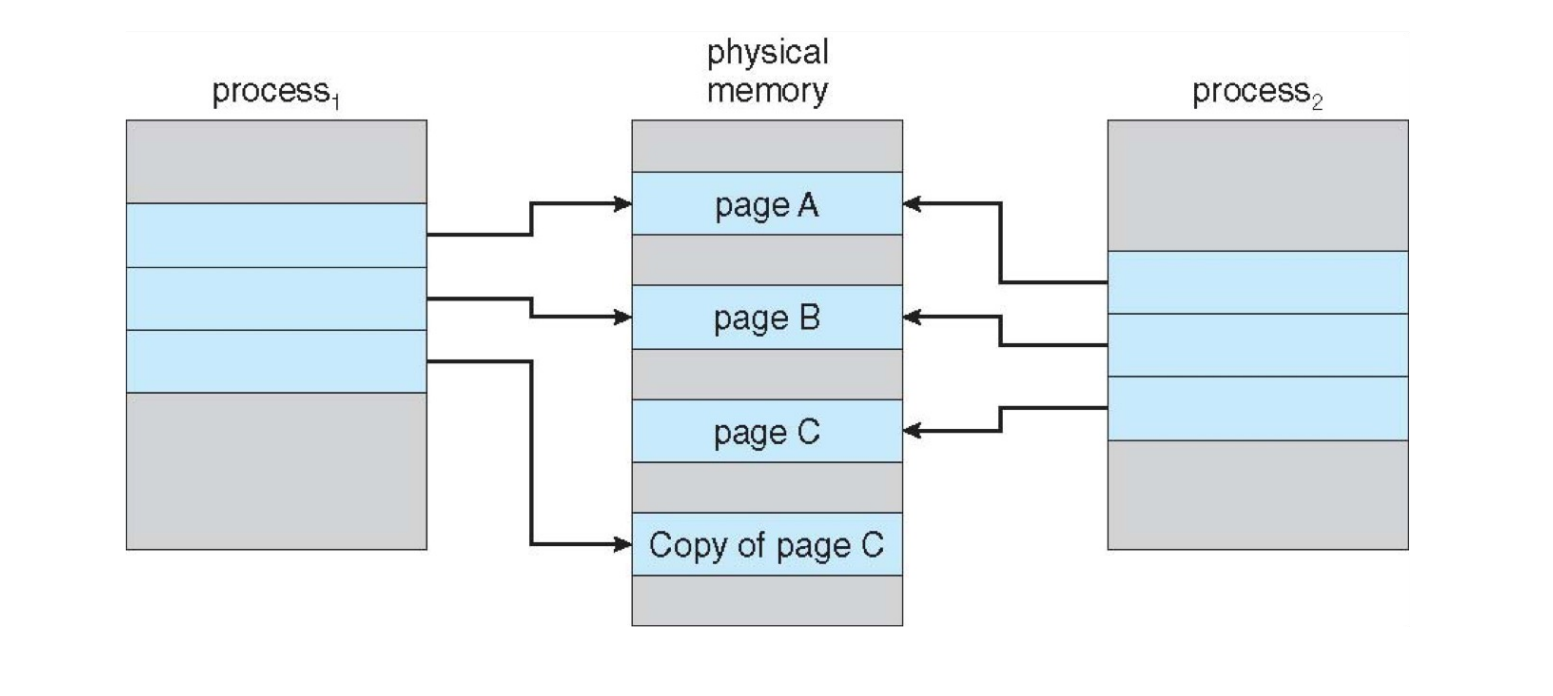
提升 fork 效率,最开始页都是共享的,只有当父进程或子进程修改了页的内容时,才会真正为修改的页分配内存。
vfork syscall optimizes the case that child calls exec immediately after fork.
- parent is suspend until child exits or calls exec.
-
child shares the parent resource, including the heap and the stack.
-
child cannot return from the function or call
exit, should call_exit.共享堆和栈,所以如果调用
exit就会弄乱父进程的堆和栈,因此只能调用_exit。
-
-
vfork could be fragile, it is invented when COW has not been implemented.
Page Replacement¶
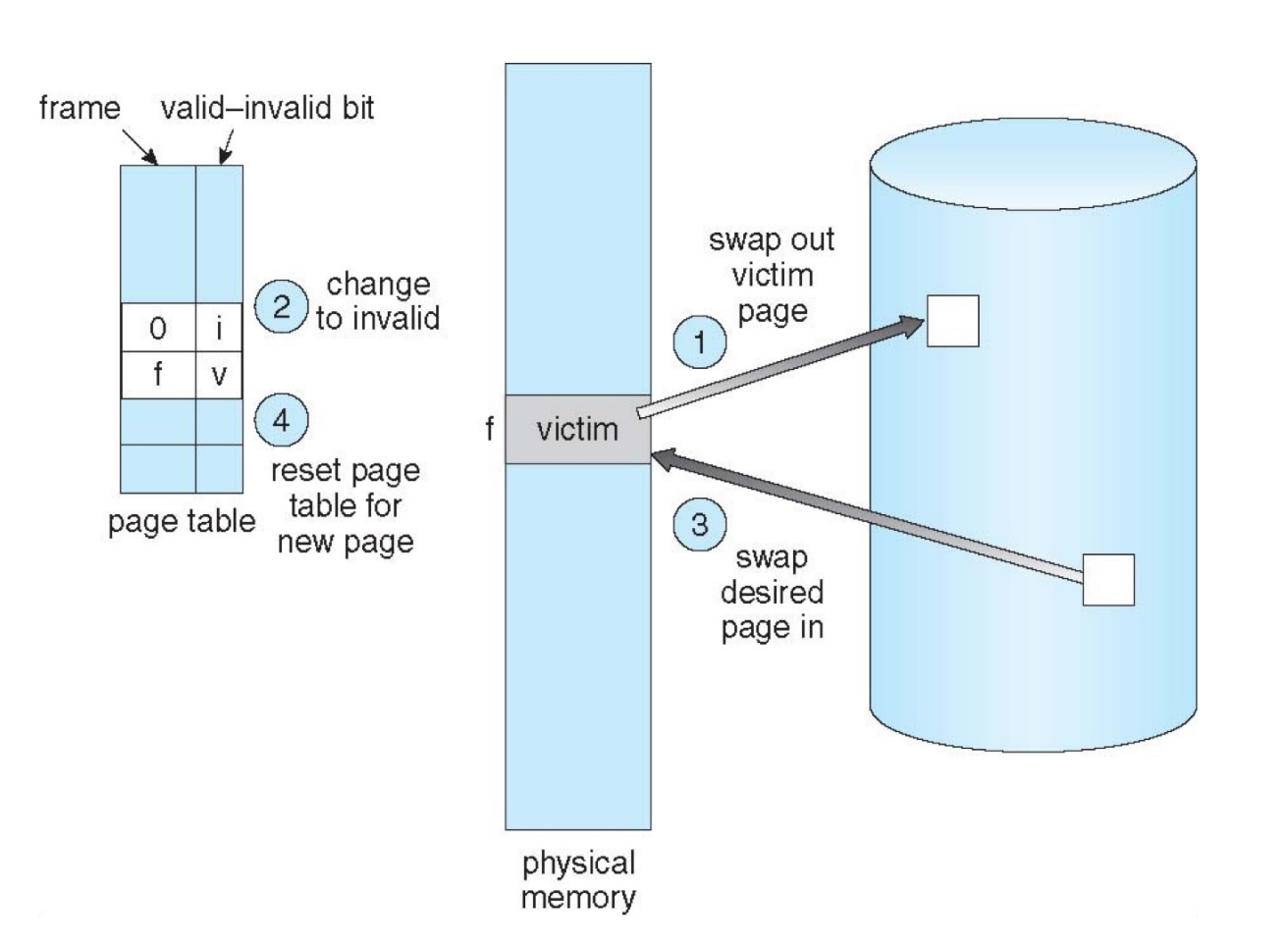
没有空闲的物理帧时应该怎么办呢?我们可以交换出去一整个进程从而释放它的所有帧;更常见地,我们找到一个当前不在使用的帧,并释放它。
Page replacement – find some page in memory, but not really in use, page it out.
与物理地址无关
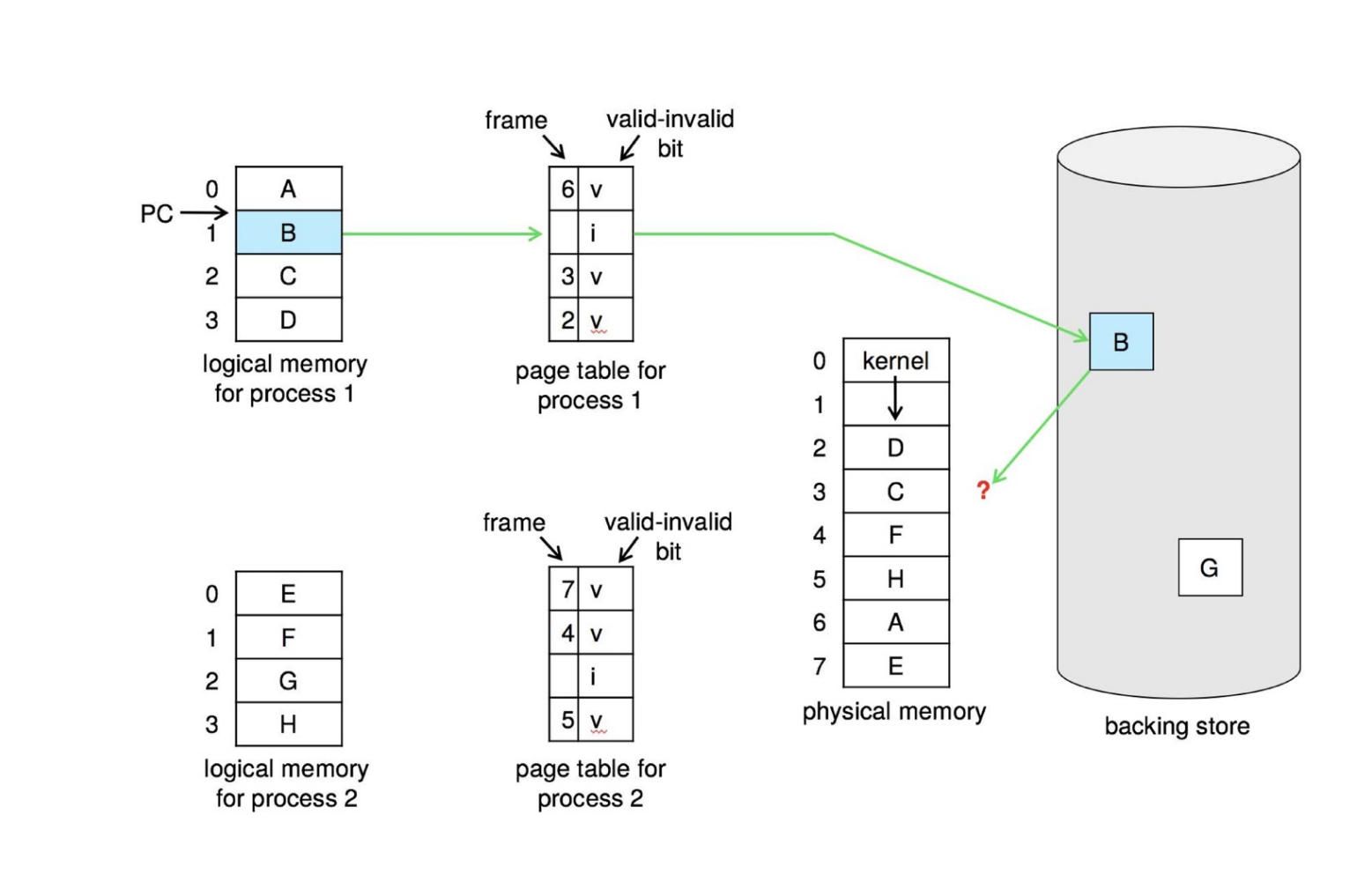
Page Replacement Mechanism¶
Page Fault Handler (with Page Replacement)
To page in a page:
- find the location of the desired page on disk
- find a free frame:
- if there is a free frame, use it
- if there is none, use a page replacement policy to pick a victim frame, write victim frame to disk if dirty
- bring the desired page into the free frame; update the page tables
- restart the instruction that caused the trap.
一次 page fault 可能发生 2 次 page I/O,一次 out( 可能要把脏页写回 ) 一次 in。
Page Replacement Algorithms¶
FIFO, optimal, LRU, LFU, MFU...
如何评价一个算法好坏:用一串 memory reference string,每个数字都是一个页号,给出物理页的数量,看有多少个 page faults。
First-In-First-Out (FIFO)¶
FIFO: replace the first page loaded.
For FIFO, adding more frames can cause more page faults! It's called Belady's Anomaly.
Example

Optimal Algorithm¶
Optimal: replace page that will not be used for the longest time.
How do you know which page will not be used for the longest time?
- can’t read the future.
-
used for measuring how well your algorithm performs.
无法预测未来什么时候会访问这些页,因此只能用来评价算法的好坏。
Example
相同的例子,只有 9 次 page fault.

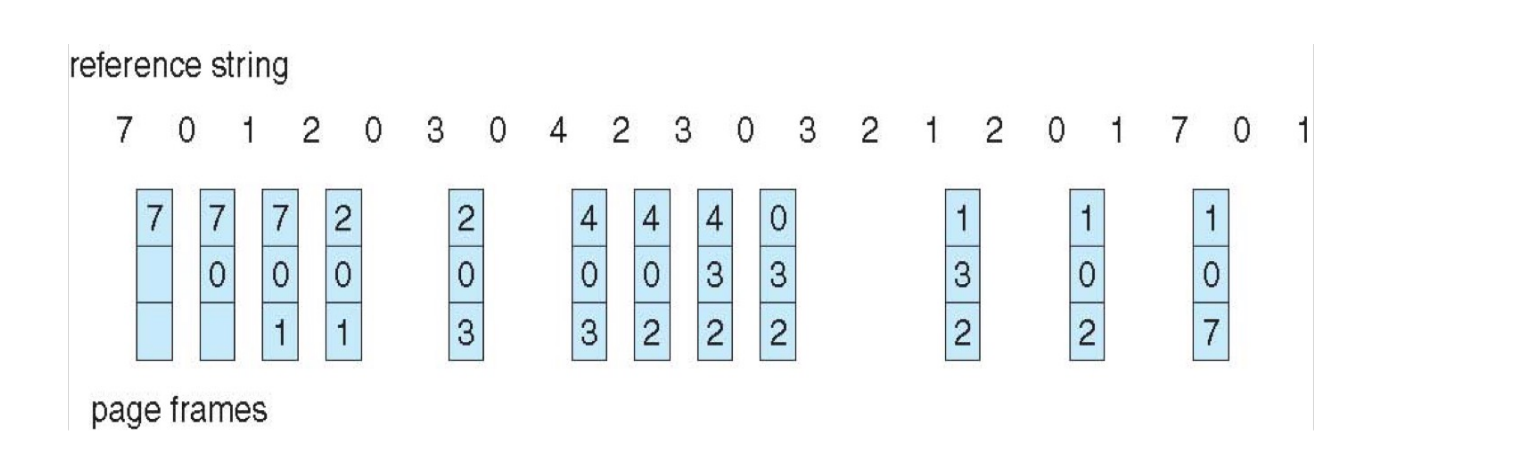
Least Recently Used (LRU)¶
LRU replaces pages that have not been used for the longest time.
LRU and OPT do NOT have Belady’s Anomaly.
Example
12 page faults.
How to implement LRU?
-
counter-based
-
every page table entry has a counter.
存了一个时间戳,每次访问这个页的时候更新时间戳。需要驱逐的时候找时间戳最小的页。
-
every time page is referenced, copy the clock into the counter.
- when a page needs to be replaced, search for page with smallest counter.
-
-
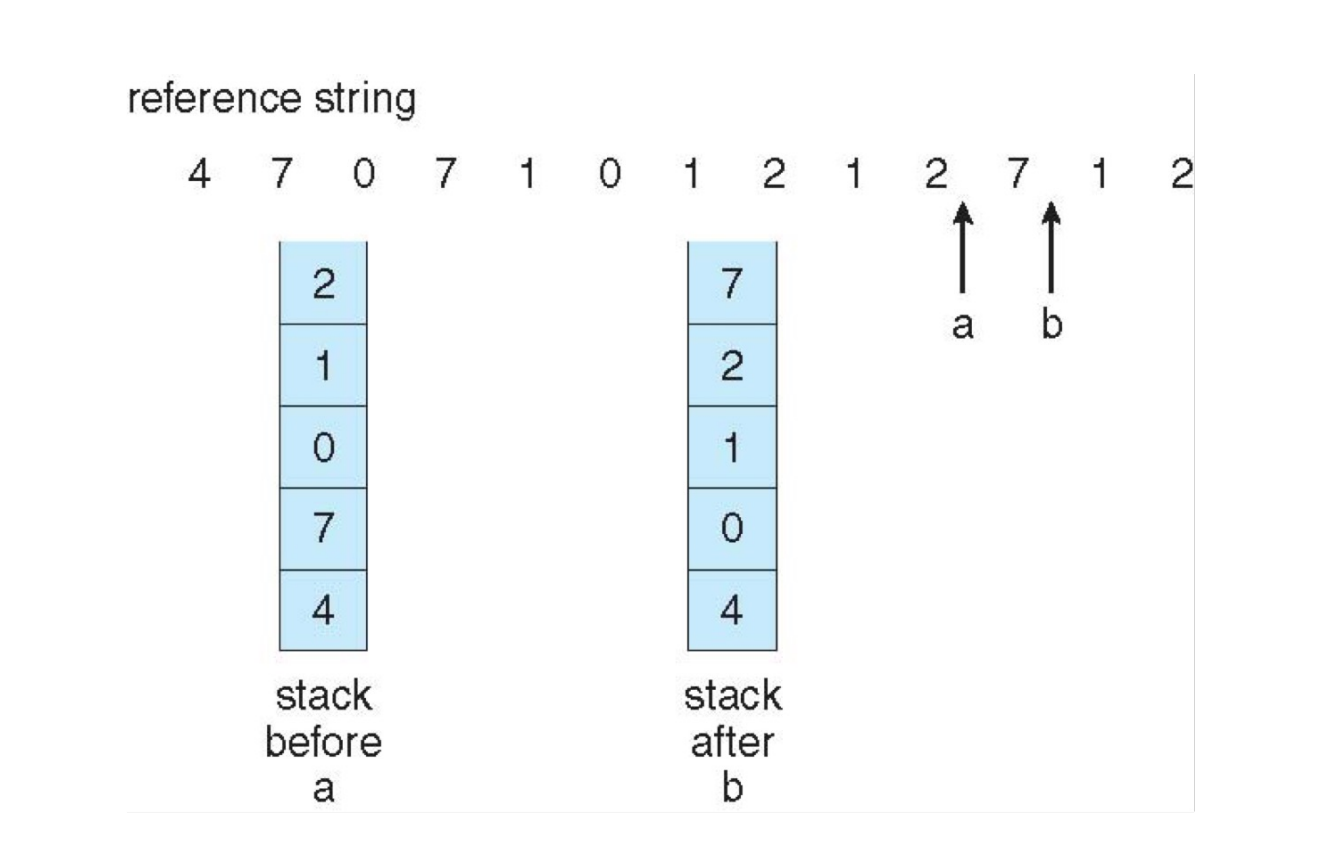
stack-based
- keep a stack of page numbers (in double linked list).
-
when a page is referenced, move it to the top of the stack.
当一个页被访问的时候,把它移到栈顶。
-
each update is more expensive, but no need to search for replacement.
LRU Implementation
LRU Approximation Implementation: Counter-based and stack-based LRU have high performance overhead.
时间戳可能很大,我们有近似的办法。
-
LRU approximation with a reference bit.
- associate with each page a reference bit, initially set to 0.
- when page is referenced, set the bit to 1 (done by the hardware).
- replace any page with reference bit = 0 (if one exists).
-
We do not know the order, however.
当所有位都设为 1 的时候就只能随机选一个,而且我们无法知道他们的访问顺序。
-
Additional-Reference-Bits Algorithm
- 8-bits byte for each page
- During a time interval (100ms), shifts bit rights by 1 bit, sets the high bit if used, and then discards the low-order bits.
-
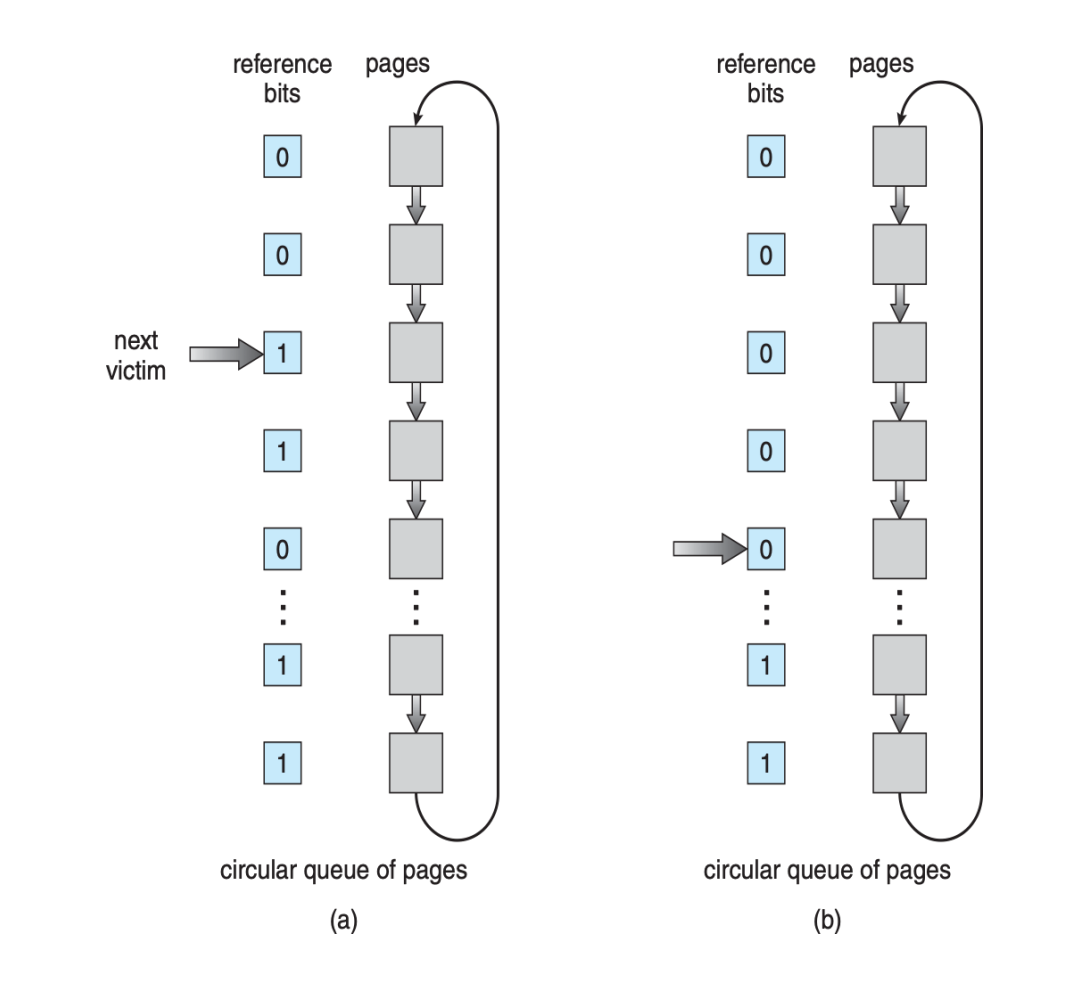
Second-chance algorithm
- Clock replacement
- If page to be replaced has
- Reference bit = 0 -> replace it
-
reference bit = 1 then:
- set reference bit 0, leave page in memory
- replace next page, subject to same rules
-
Enhanced Second-Chance Algorithm
- Improve algorithm by using reference bit and modify bit (if available) in concert.
- Take ordered pair (reference, modify):
- (0, 0) neither recently used not modified – best page to replace.
- (0, 1) not recently used but modified – not quite as good, must write out before replacement.
- (1, 0) recently used but clean – probably will be used again soon.
- (1, 1) recently used and modified – probably will be used again soon and need to write out before replacement.
Counting-based Page Replacement¶
Keep the number of references made to each page.
- Least Frequently Used (LFU) replaces page with the smallest counter.
- Most Frequently Used (MFU) replaces page with the largest counter.
- LFU and MFU are not common.
Page-Buffering Algorithms¶
-
Keep a pool of free frames, always
-
frame available when needed, no need to find at fault time.
维持一个空闲帧的池子,当需要的时候直接从池子里取一个即可。
-
When convenient, evict victim.
系统不繁忙的时候,就把一些 victime frame 释放掉
。 (写回到磁盘,这样帧可以加到 free list 里)
-
-
Possibly, keep list of modified pages.
- Possibly, keep free frame contents intact and note what is in them - a kind of cache.
Memory intensive applications can cause double buffering - a waste of memory.
User 和 OS 都缓存了同一份内容,导致一个文件占用了两个帧。
Operating system can given direct access to the disk, getting out of the way of the applications - Raw disk mode.
赋予操作系统直接访问磁盘的权限。
Allocation of Frames¶
Each process needs minimum number of frames - according to instructions semantics. e.g. IBM 370 – 6 pages to handle SS MOVE instruction.
给不同的进程分配 frame,我们该如何分配?
- Equal allocation
- Proportional allocation - Allocate according to the size of process.
当帧不够用的时候,我们需要有替换。
-
Global replacement – process selects a replacement frame from the set of all frames; one process can take a frame from another.
可以抢其他进程的帧。
-
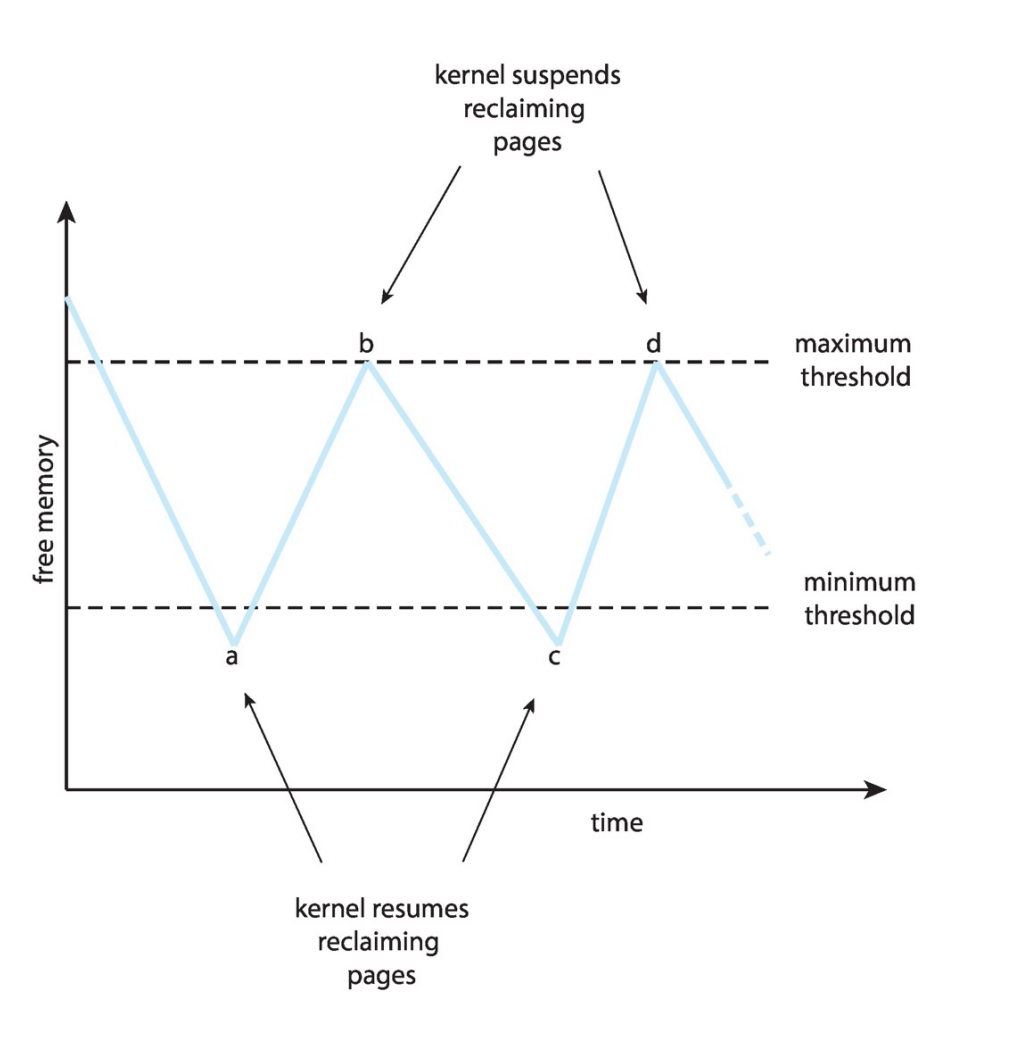
Reclaiming Pages: page replacement is triggered when the list falls below a certain threshold.
如果 free list 里的帧数低于阈值,就触发 page replacement。这个策略希望保证这里有充足的自由内存来满足新的需求。
Reclaiming Pages
当低于 minimum 阈值的时候就唤醒,回收到 maximum 阈值就停止回收。
-
-
Local replacement – each process selects from only its own set of allocated frames.
只能从自己的帧里选。
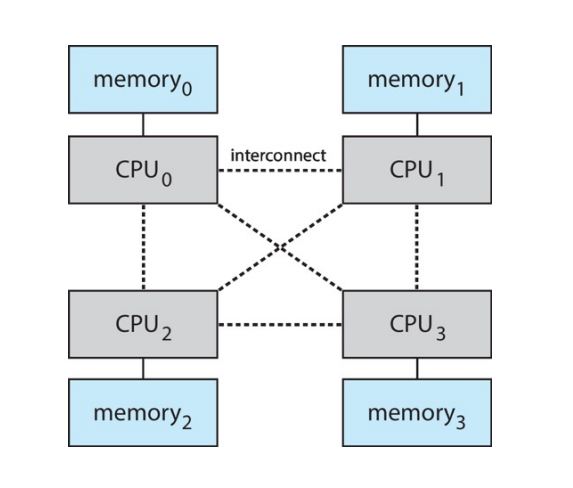
Non-Uniform Memory Access¶
不同 CPU 距离不同的内存的距离不同,因此访问时间也不同。
Major and minor page faults¶
-
Major: page is referenced but not in memory。
-
Can only be satisfied by disk
这个访问的数据只在磁盘里,因此需要读磁盘添加映射。
-
do_anonymous_page is not major
- Minor: mapping does not exist, but the page is in memory.
-
Shared library
现在主要都是 minor page fault,比如共享库。

-
Reclaimed and not freed yet
数据还在内存里,我们只需要再次映射就可以了。
-
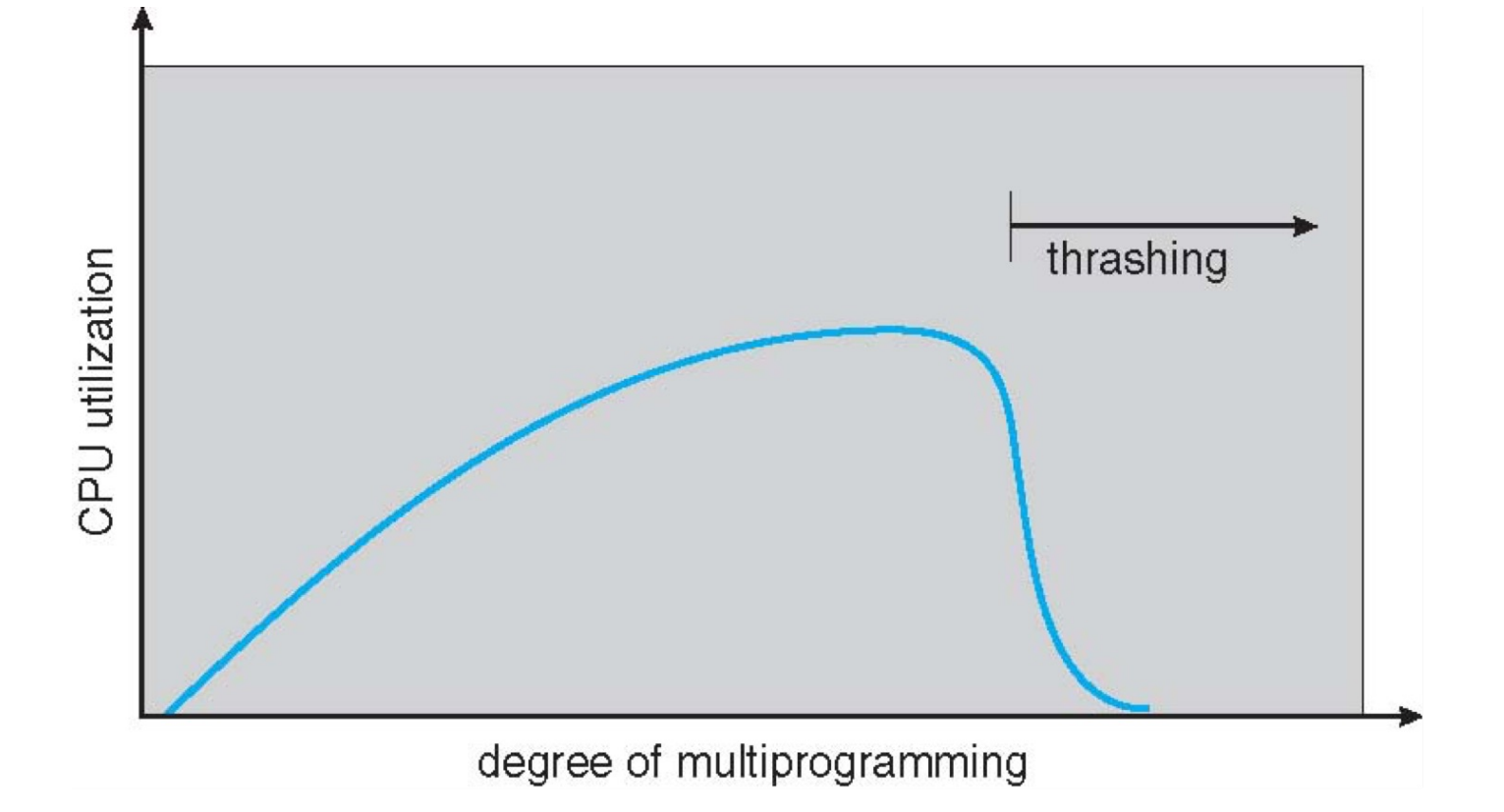
Thrashing¶
Thrashing: a process is busy swapping pages in and out.
如果我们的进程一直在换进换出页,那么 CPU 使用率反而会降低。进程越多,可能发生一个进程的页刚加载进来又被另一个进程换出去,最后大部分进程都在 sleep。
- Why does demand paging work?
- process memory access has high locality.
- process migrates from one locality to another, localities may overlap.
- Why does thrashing occur?
-
total memory size < total size of locality
一个 locality 大小比内存大,因此我们不得不一直换进换出页。
-
Resolve thrashing¶
Note
进程不断从一个 locality 移到另一个 locality,而且这两个 locality 可能有重叠。

我们使用工作集模型 (working set model) 来解决 thrashing。
-
Working-set window(\(\delta\)): a fixed number of page references
把所有的 locality 称为一个工作集,windows 是一个关于时间的窗口,代表最近 \(\delta\) 次对页面的访问。
-
Working set of process \(p_i\) (WSSi): total number of pages referenced in the most recent \(\delta\) (varies in time)
- Total working sets: \(D = \sum\) WSSi
确定一个进程频繁访问的页面,保证这些页面不被换出;需要调页时从剩余的页面进行交换。如果频繁访问的页面数已经大于了当前进程可用的页面数,操作系统就应当把整个进程换出,以防止出现抖动现象。
Example
\(\delta=10\)
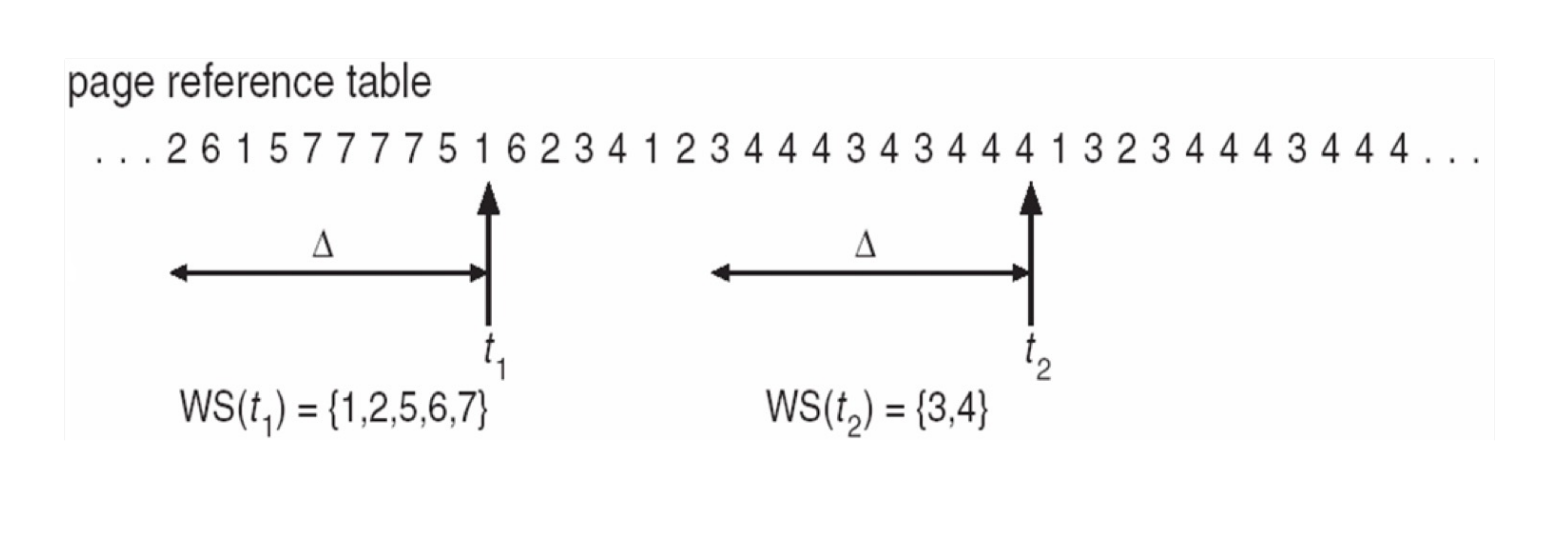
怎样找到工作集? an interval timer + a reference bit,访问了这个界面就把 reference bit 置 1,当定时器到了之后,我们就可以根据 reference bit 来将这个页面放到工作集中。

Other Considerations¶
-
Prepaging
page fault 时,除了被 fault 的 page,其他相邻的页也一起加载。
-
Page Size
- Fragmentation -> small page size
- Page table size -> large page size
- Resolution -> small page size
- I/O overhead -> large page size
- Number of page faults -> large page size
- Locality -> small page size
- TLB size and effectiveness -> large page size
- On average, growing over time
-
TLB Reach: the amount of memory accessible from the TLB
- TLB reach = (TLB size) \(\times\) (page size)
- Increase the page size to reduce TLB pressure
-
Program Structure
Program structure can affect page faults.

-
I/O interlock: Pages must sometimes be locked into memory.
把页面锁住,这样就不会被换出去。
Memory management in Linux¶
page fault 是针对 user space 的,kernel 分配的内存不会发生 page fault(否则会嵌套
一个进程有自己的 mm_struct,所有线程共享同一个同一个页表,内核空间有自己的页表 swapper_pg_dir。
注意这里的 pgd 存的是虚拟地址,但当加载到 satp 里时会转为物理地址。
Linux Buddy System¶
Buddy system 从物理连续的段上分配内存;每次分配内存大小是 2 的幂次方,例如请求是 11KB,则分配 16KB。
当分配时,从物理段上切分出对应的大小(每次切分都是平分
Example
分配 21KB 时的情况,\(C_L\) 会被分配。
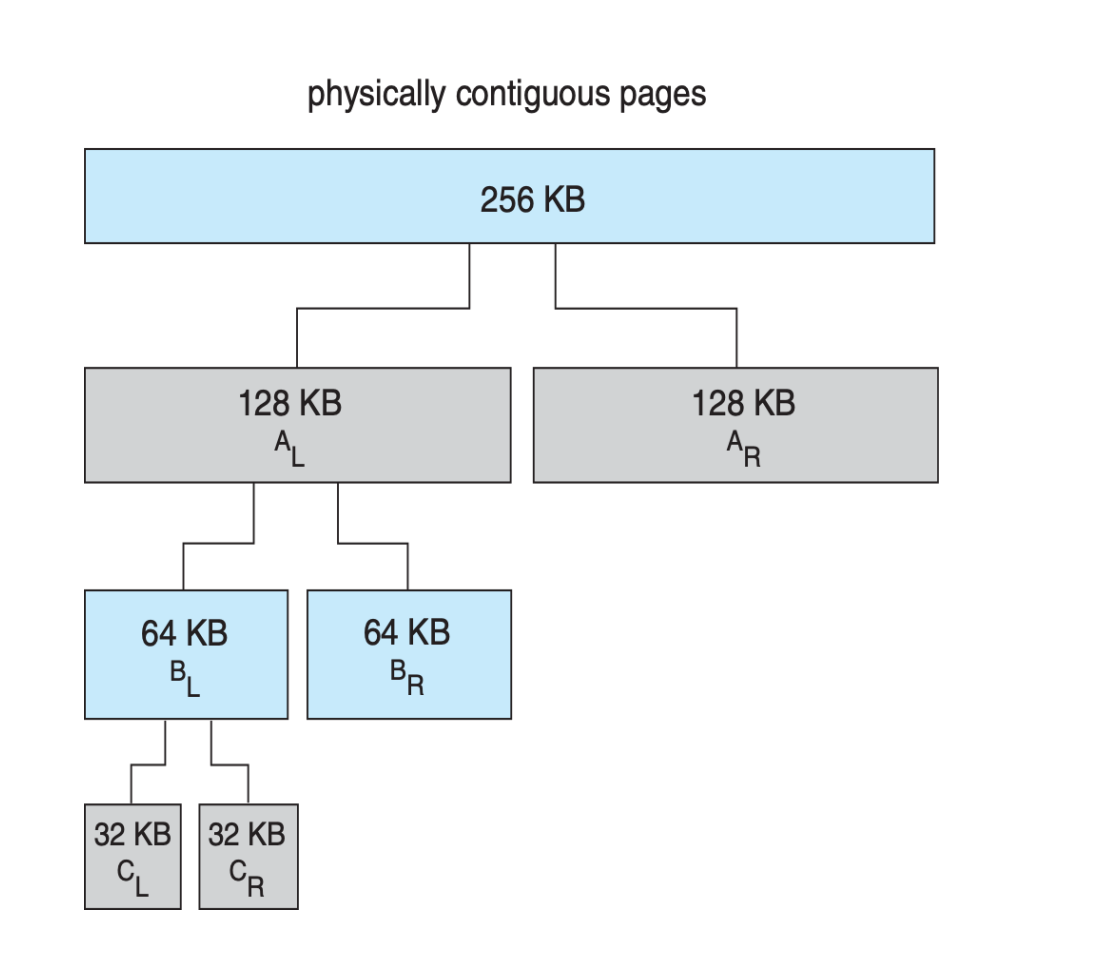
当它被释放时,会合并 (coalesce) 相邻的块形成更大的块供之后使用。
-
advantage: it can quickly merge unused chunks into larger chunk.
可以迅速组装成大内存(释放后即可合并
) 。 -
disadvantage: internal fragmentation
Slab Allocation¶
要分配很多 task_struct,如何迅速分配。我们把多个连续的页面放到一起,将 objects 统一分配到这些页面上。
Slab allocator is a cache of objects.
- a cache in a slab allocator consists of one or more slabs
- a slab contains one or more pages, divided into equal-sized objects
Upon request, slab allocator
- Uses free struct in partial slab
- If none, takes one from empty slab
- If no empty slab, create new empty
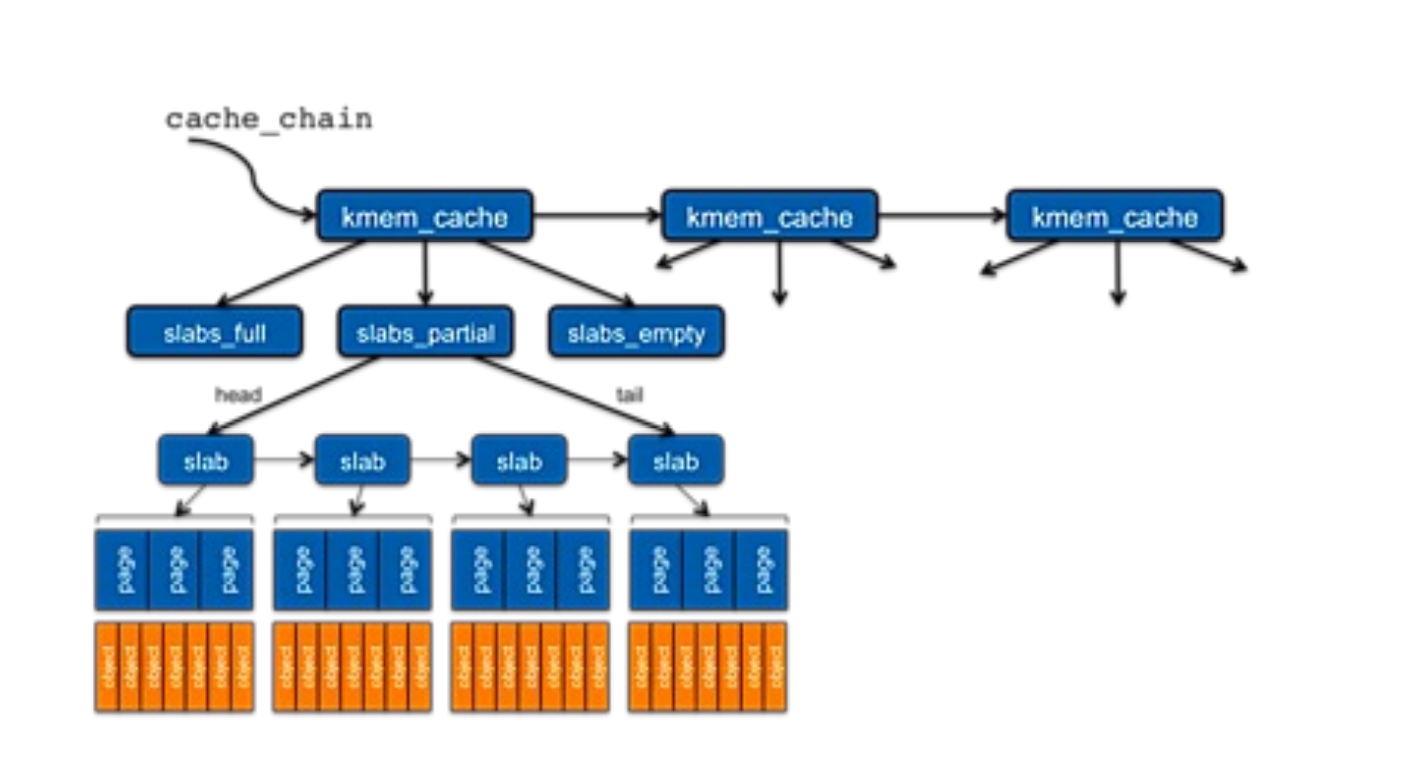
Example
A 12k slab (3 pages) can store 4 3k objects.

Takeaway¶
Takeaway
- Page fault
- Valid virtual address, invalid physical address
- Page replacement
- FIFO, Optimal, LRU, 2nd chance
- Thrashing and working set
- Buddy system
- slab