Routing¶
Abstract
- Introduction
- Routing Algorithms
- Maze Routers
- Routing in Practice
Introduction¶
- The Problem
- scale: 有上千个 macro,上百万的 gates 和 wires,而我们要将他们都连接起来。
- geometric complexity: 在布线过程中,通常使用 grid 作为基本的出发点。但是在纳米尺度上,几何规则变得非常复杂。此外,集成电路中通常有多个布线层,每个层的“成本”(如制造难度、电阻、电容等)都不同,这增加了布线的复杂性。
- electric complexity: 除了连接所有的线以外,还要让 delay 尽可能小,以及电线之间的相互作用(cross-talk 串扰)尽可能小。
- Definition
- Problem: 给定的 placement 和固定的 meta layers,找到一个有效的 horizontal & vertical wires 模式,以连接所有 nets 的端点。
- Input: cell 的位置,netlist,网表则列出了所有需要连接的端点组合。
- Output: net 的几何布局,即每个 net 在芯片上的实际布线图案,连接了各个标准单元。
- Two-step process: Global routing and detailed routing.
- Objective: 100% connectivity,以及最小 area 和 wirelength。
- Constraint: 布线层数、时序、设计规则、串扰、工艺变化。
Routing Algorithms¶
-
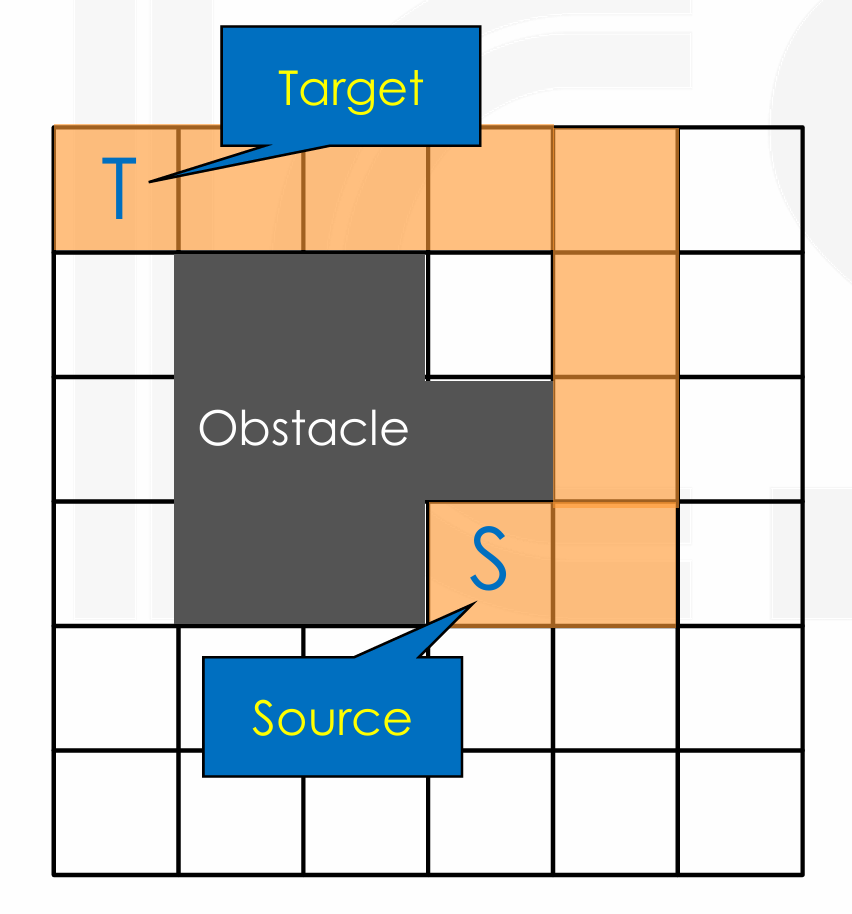
Grid Assumption
- layout 是一个规则的方形网格。
- A legal wire is a set of connected grid cells through unobstructed cells.
- Obstacles 障碍物标记在网格中的某些单元。
- 导线只能在网格的垂直和水平方向上走线(Manhattan Routing)。
Maze Routers¶
- Strategy: 一次布线一个 net,为当前 net 找到最佳的布线路径。
- Problems: 早期布线的 net 可能会阻挡后来 net 的路径,对一个 net 的最优选择可能会阻塞其他 net。
-
Idea: Expand => Backtrace => Cleanup
-
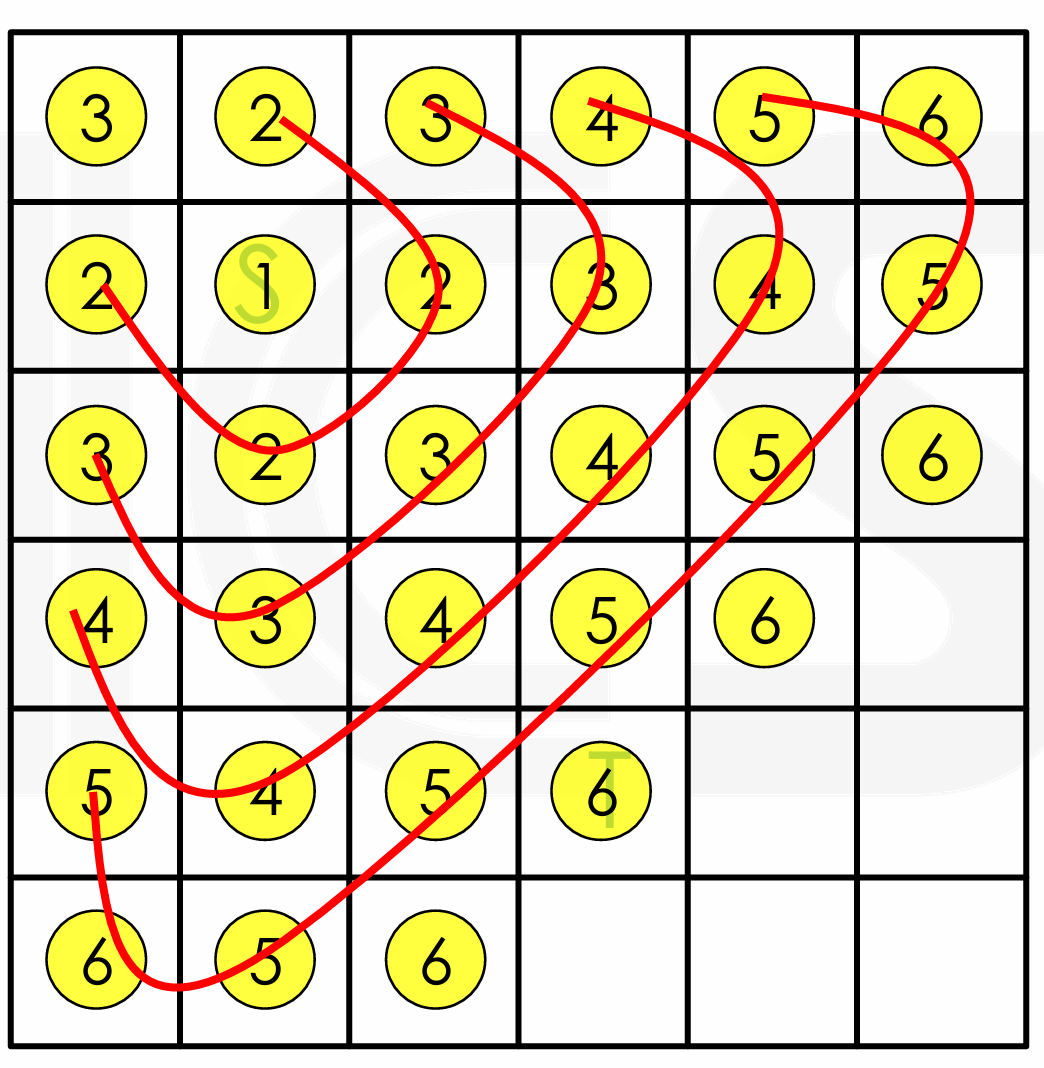
Expand: 从源点到目标点,以四个基本方向(上、下、左、右)扩展,寻找可行路径。通常用 BFS 实现。
- 从源点开始,寻找所有与源点相邻的、可达的单元格(即没有被障碍物占据的单元格)。以这些单元格为新的起点,继续寻找它们相邻的可达单元格,如此类推,不断扩展。这个过程一直持续,直到达到目标点。
- We approach the target with a “wavefront”.
Expand
这里只需要 6 步即可从 S 到达 T。
-
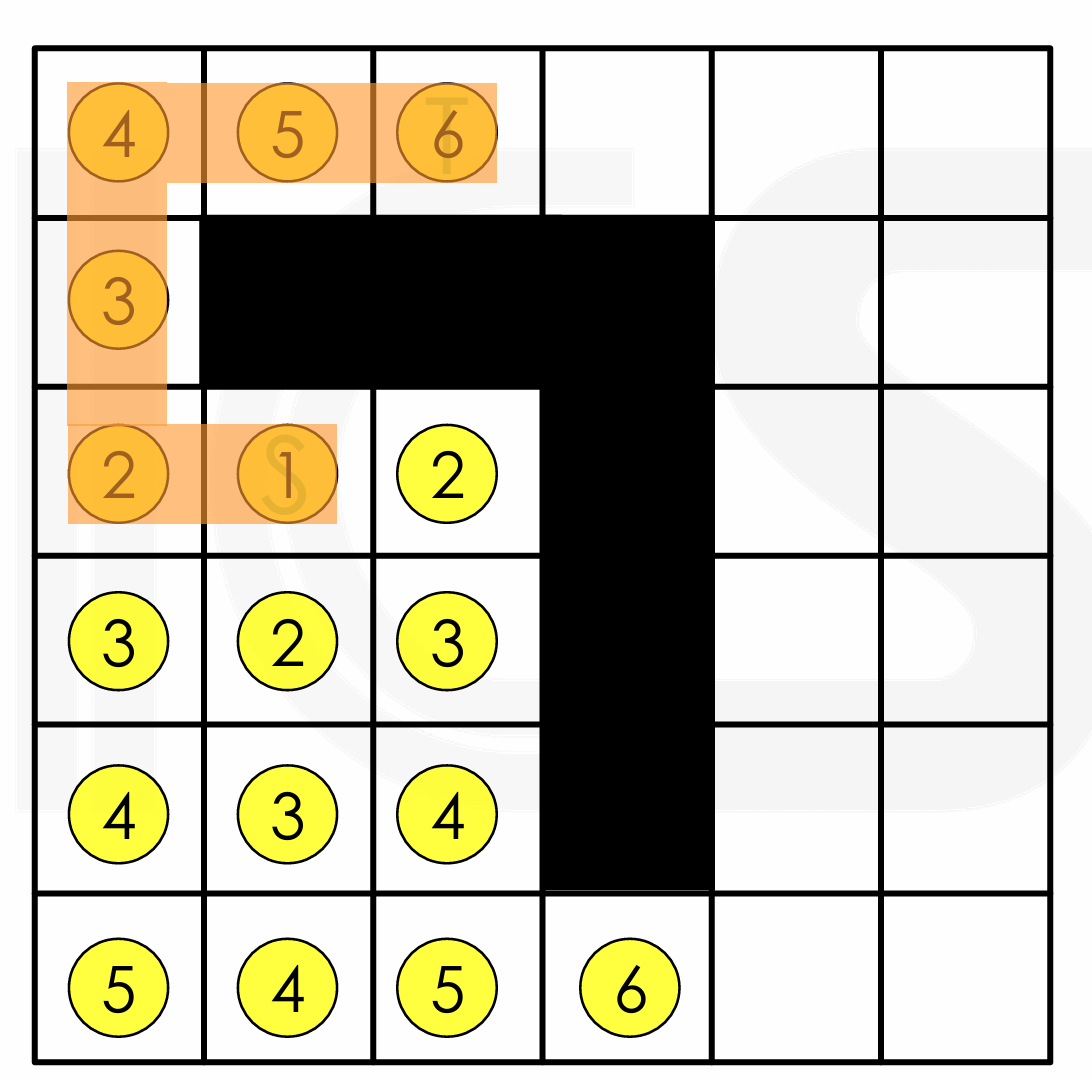
Backtrace: 回溯是指从目标点开始,沿着路径长度递减的顺序反向追踪。这样做可以标记出一条到目标点的最短路径。
- 通常情况下,可能存在多条同样长度的最短路径,这时可以采用优化策略来选择最佳路径。例如,可以根据路径的直线性、拐角数量或与其他网络的干扰程度来决定。
-
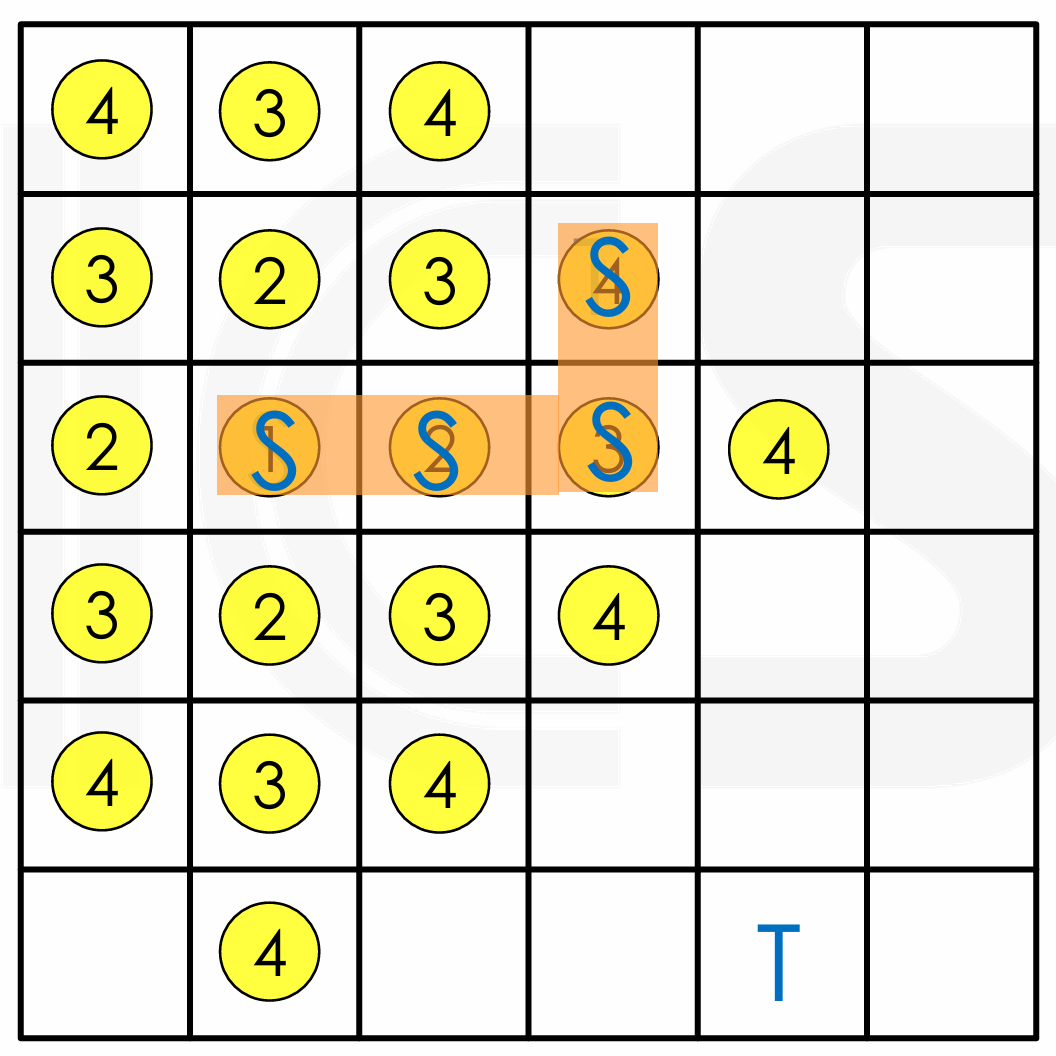
Cleanup: 在确认了布线路径之后,移除所有为了寻找路径而设置的临时标记,只保留最终的布线路径。
- 假设我们在回溯时启发式地选择了一条路径,我们要将这条从源点到目标点的网络路径标记为障碍物。其他网络进行布线时,就不会考虑已经占用过的路径。
Backtrace & Cleanup

-
-
Blockages: Just “go around” them!
Blockages
-
Multi-Point Net
- 有时一个 net 有多个目标点(即 fanout>1),即一个 S 对应多个 T。
- 使用 maze routing algorithm 找到从源点到最近目标点的路径。这里的目标点是最近的目标点,而不是所有。随后进行重新标记,我们将路径上所有的单元格重新标记为 sources,然后重新运行 maze router,同时使用所有源点。重复运行知道连接所有目标点。
- 因为一条 wire 上电势相同,所以可以将路径上的所有点视为源点。
- 这样得到的结果不一定最优,但是是一个较好的解(Steiner Tree)。
Multi-Point Net
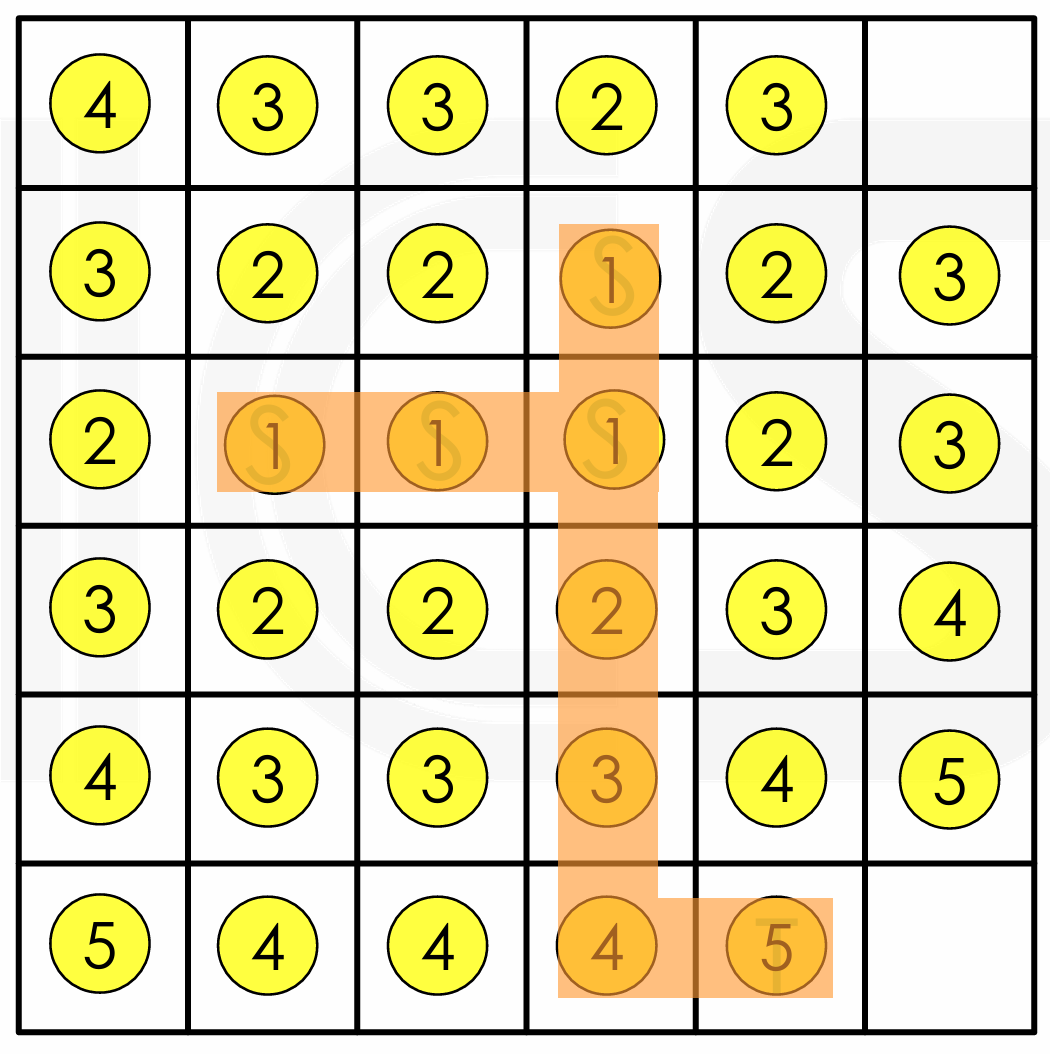
-
Multi-Layer Routing
- Idea: one grid for each layer, Each grid box can contain one via, New expansion direction – up/down.
Multi-Layer Routing
这里可以看到,我们可以在 via 处切换层,随后在另一个 via 切回来,这样的 cost 更低。
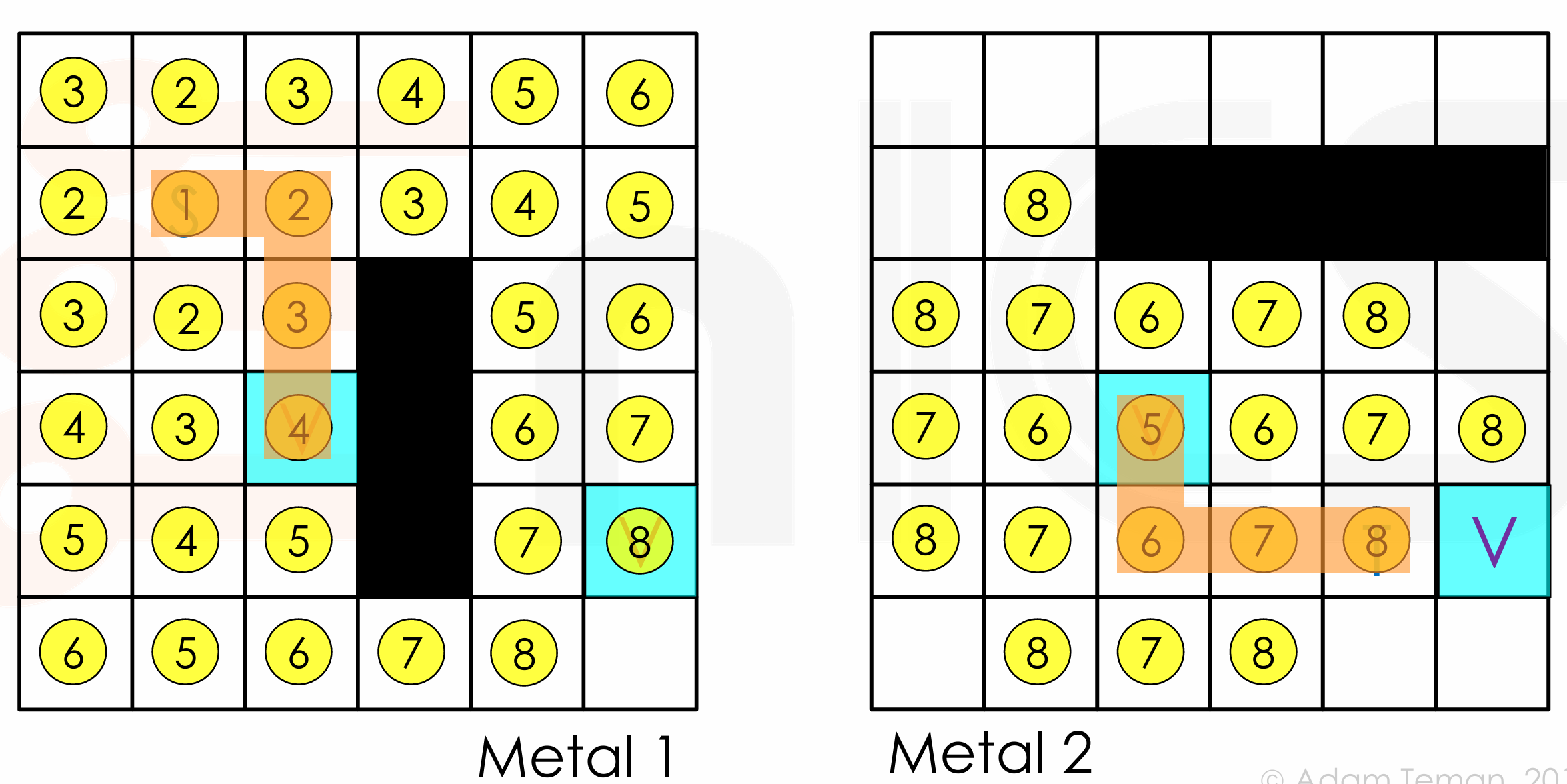
-
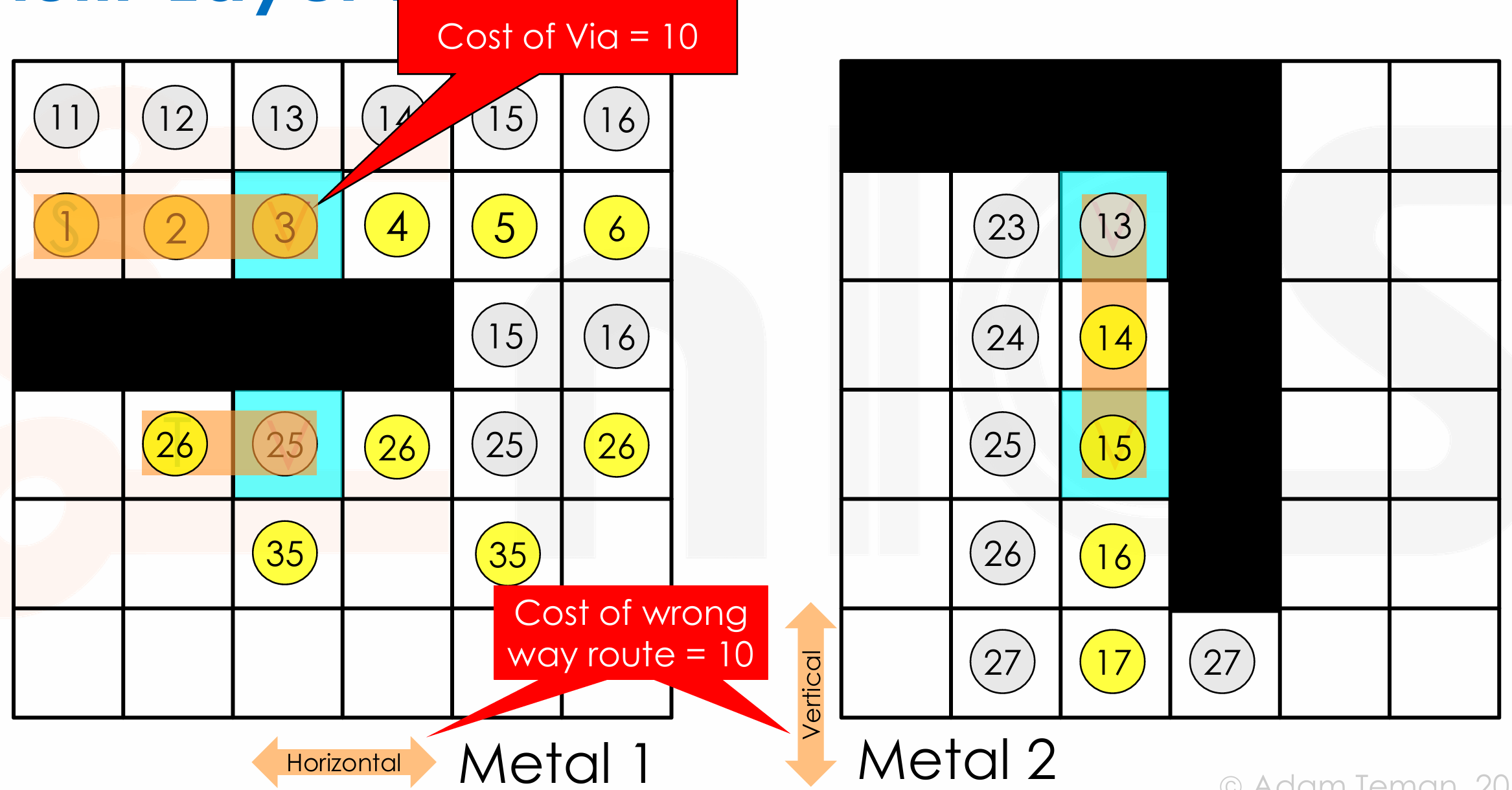
Non-Uniform Grid Costs
- via 的电阻通常较高,我们应该尽可能的在同一层布线。同时我们也希望每层的线都保持同一方向(如水平、竖直),有助于减少导线之间的交叉和干扰。
- 因此我们对 turn 或者 via 的 cost 进行调整,对此类操作进行惩罚,以鼓励更直接的布线方式。
Non-Uniform Grid Costs
这里我们假设 metal1 水平方向布线,metal2 竖直方向布线,布线方向错误或者通过 via 的 cost 都为 10。
Implementation¶
- Grids are huge.
- 实现这样的布线算法需要高效的算法和数据结构。对于如此巨大的网格,我们需要一种低成本的表现形式来处理这个问题。
- e.g., 一个 1cm x 1cm 的芯片,100 纳米的轨迹,10 个布线层,总共 1000 亿个网格单元。
- low cost representation
- Only store the wavefront.
- Remember which cells have been reached, at what cost, and from which direction.
- Use Dijkstra’s algorithm to find the cheapest cell first.
- Store data in a heap.
- 同时我们还需要使用一些启发式的算法,决定先处理哪些 net,沿哪个方向,如何处理 fixing 问题等等。
-
Divide and Conquer
-
先 Global Routing 再 Detailed Routing。我们将一个芯片分成 big, coarse regions,这个大格子我们叫做 GBOX/GCell。Global Routing 基于大格子先粗略确定每个格子到每个格子的入口和出口。
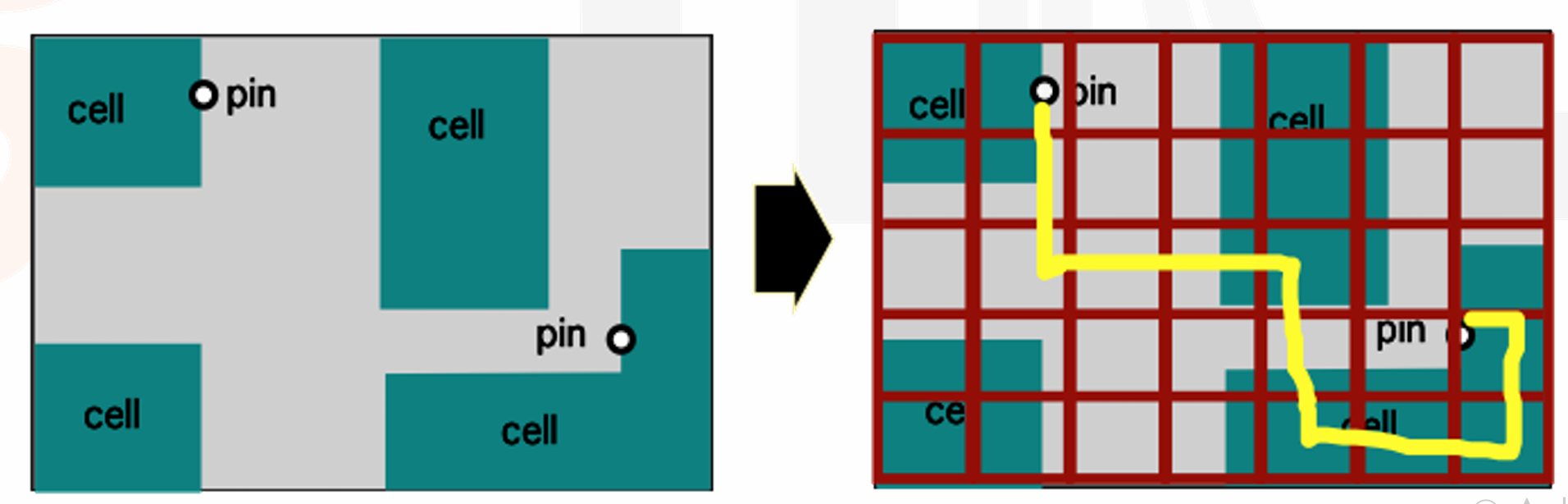
-
完成以后再对格子内部的连线确定细节,这一步叫做 Detailed Routing。
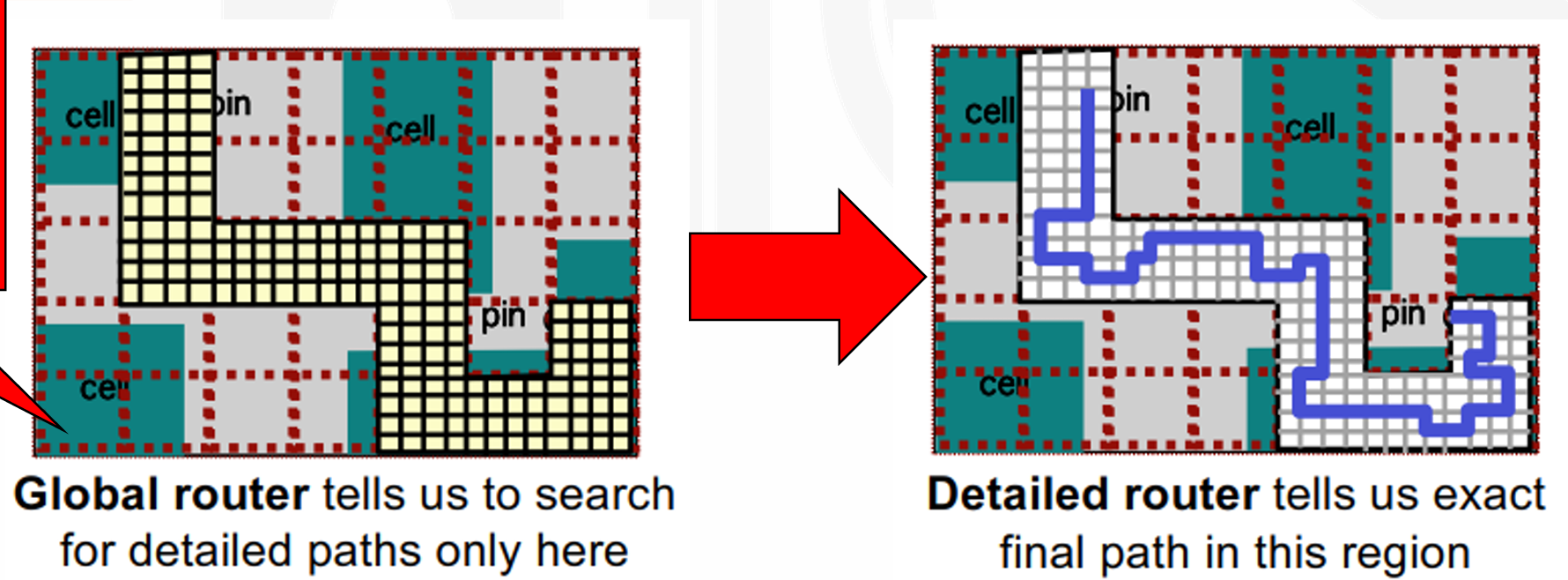
-
Routing in Practice¶
-
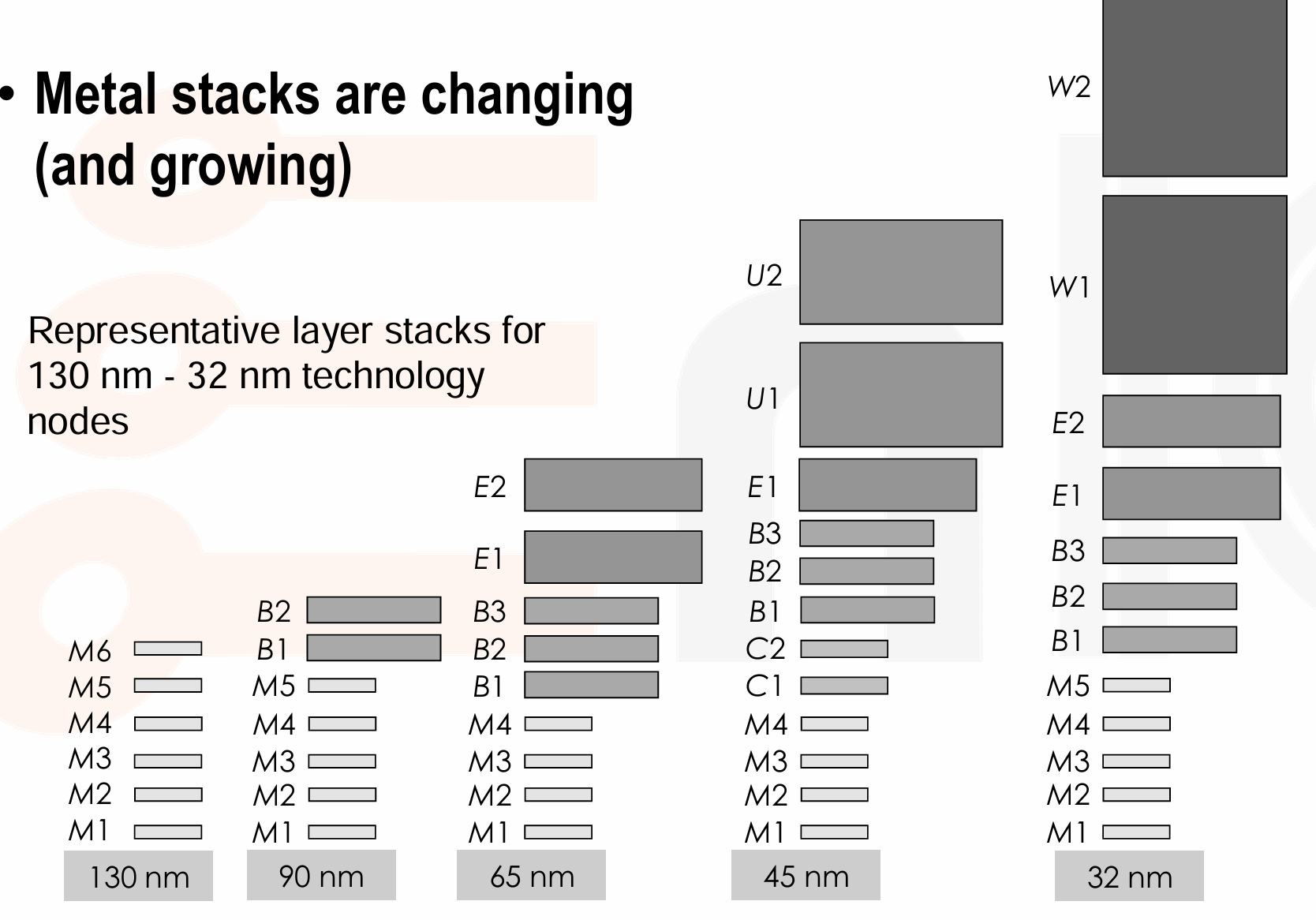
Layer Stacks: Meta stacks are changing and growing.
- 对于早期的工艺,我们可以看到其尽管有很多层,但最小间距和最小宽度保持一致。
- 随着工艺的推进,我们需要 higher thicker 的金属层,从而减少 RC 值并提高更好的电源布线。
- 较低的金属层主要用于局部互连,中间层可能用于 clock 或者更长的全局布线,顶层主要用于电源连接。
-
Global Route
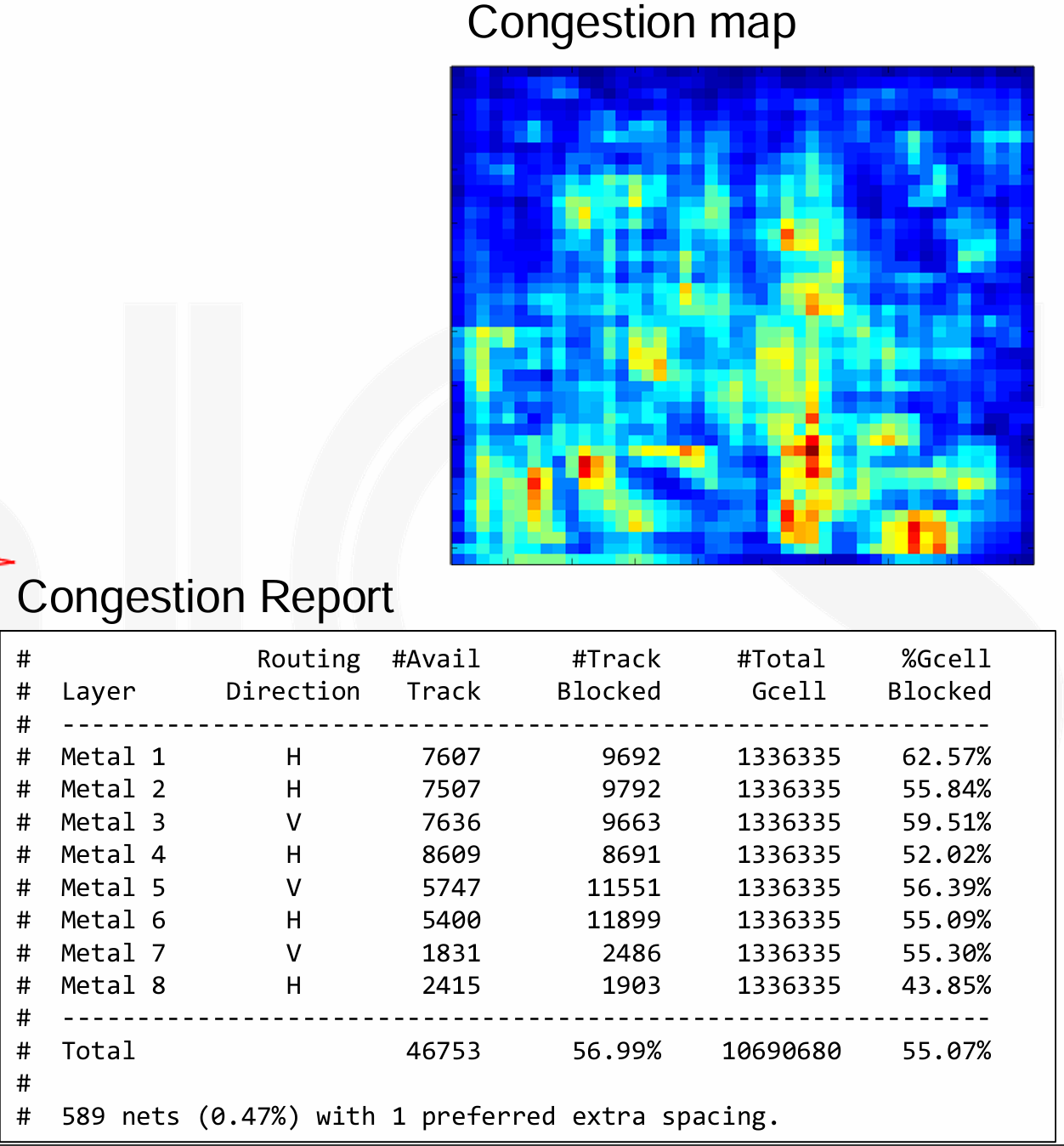
- 全局布线首先将芯片的布局划分为一系列的 GCell。每个 GCell 包含了一定数量的布线资源,如 wire tracks 导线轨道。在每个布线层上,每个 GCell大约包含 10 个导线轨道。这些轨道用于连接芯片上的不同模块。
- 全局布线的目的是执行快速的网格布线,也可以用来 trial route。
- 在完成 Gloabl Route 之后,可以使用 congestion map 展示较高拥塞的区域。然后就要进行布局规划的迭代过程,针对这些区域进行修正。
-
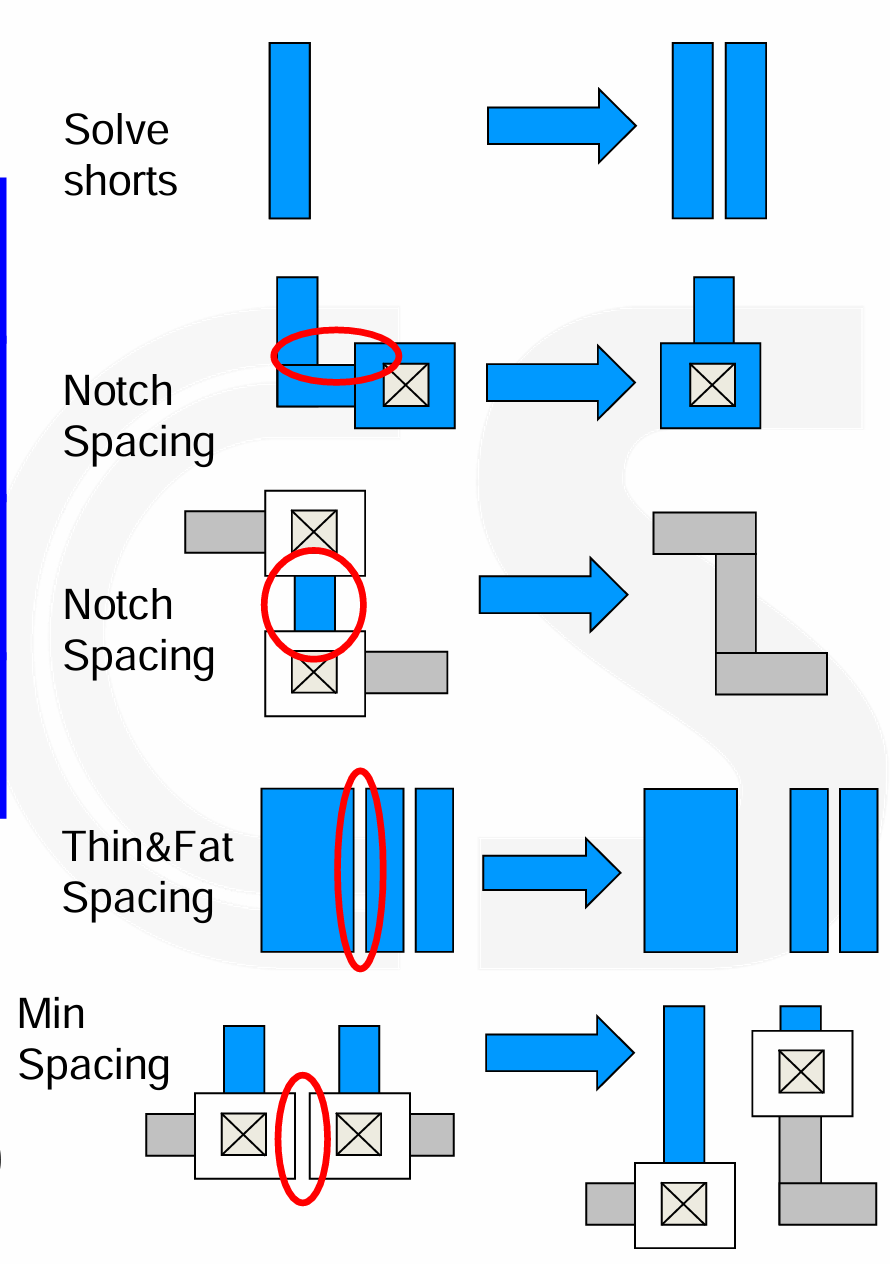
Detailed Route
- Assign nets to tracks
- Lay down wires
- Connect pins to nets
- Solve DRC violations
- Reduce cross couple cap
- Apply special routing rules
Example
-
Timing-Driven Routing
- 主要是尝试对 critical paths 进行优化,如果系统仍然存在时序问题,通过布线的方式可以进行一定的优化,对关键路径采用最短的路径,以减少延迟。
- 我们需要采用权重的方式,给不同的 net 分配不同的重要性,工具优先对其进行布线,尽可能不要经过 Via,不要拐弯。
Signal Integrity (SI)¶
-
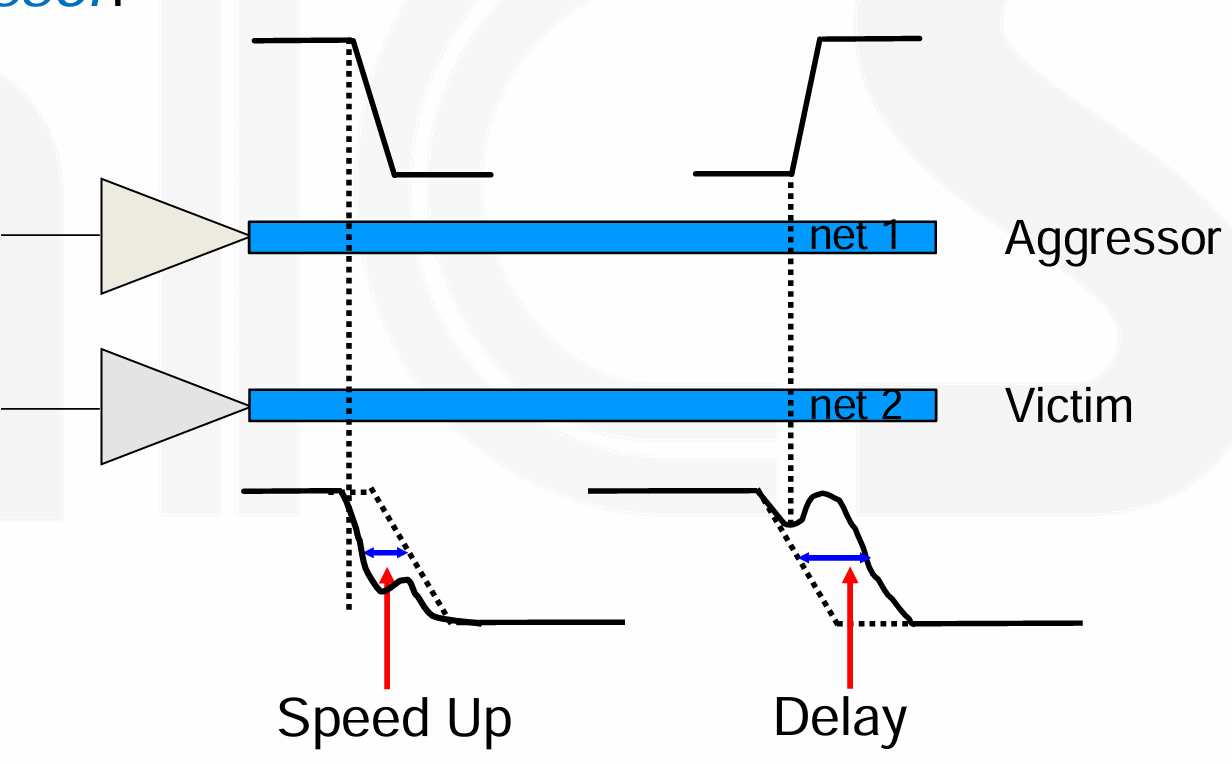
Signal Integrity during routing is synonymous with Crosstalk 串扰。
- A switching signal may affect a neighboring net,把切换信号的 net 为 aggressor,被影响的 net 为 victim。
-
可能带来两个影响:当 aggressor 和 victim 同方向变化时,Signal speed up;当 aggressor 和 victim 反方向变化时,Signal slow up。
-
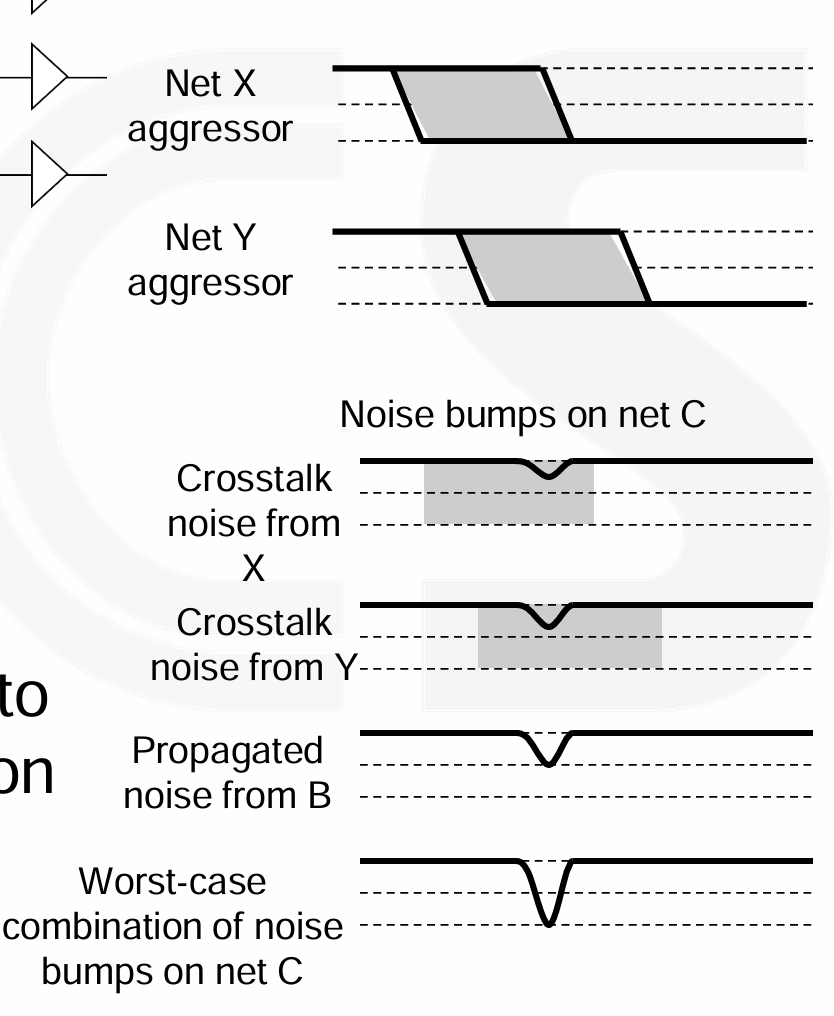
SI Multi-Aggressor Timing Analysis
- Infinite Window Analysis,考虑所有可能的 transition,估计串扰可能带来的最大的 delay。但是随着工艺进步,间距降低,交叉面积增大,导致了极端情况的出现。
- Propagated Noise Analysis,为每个 aggressor 相对于 victim 创建一个时间上的 transition window。噪声只在干扰源的过渡窗口和受害线的敏感窗口重叠时才被考虑,这样可以更准确地确定由多个干扰源引起的最坏情况下的噪声尖峰。
-
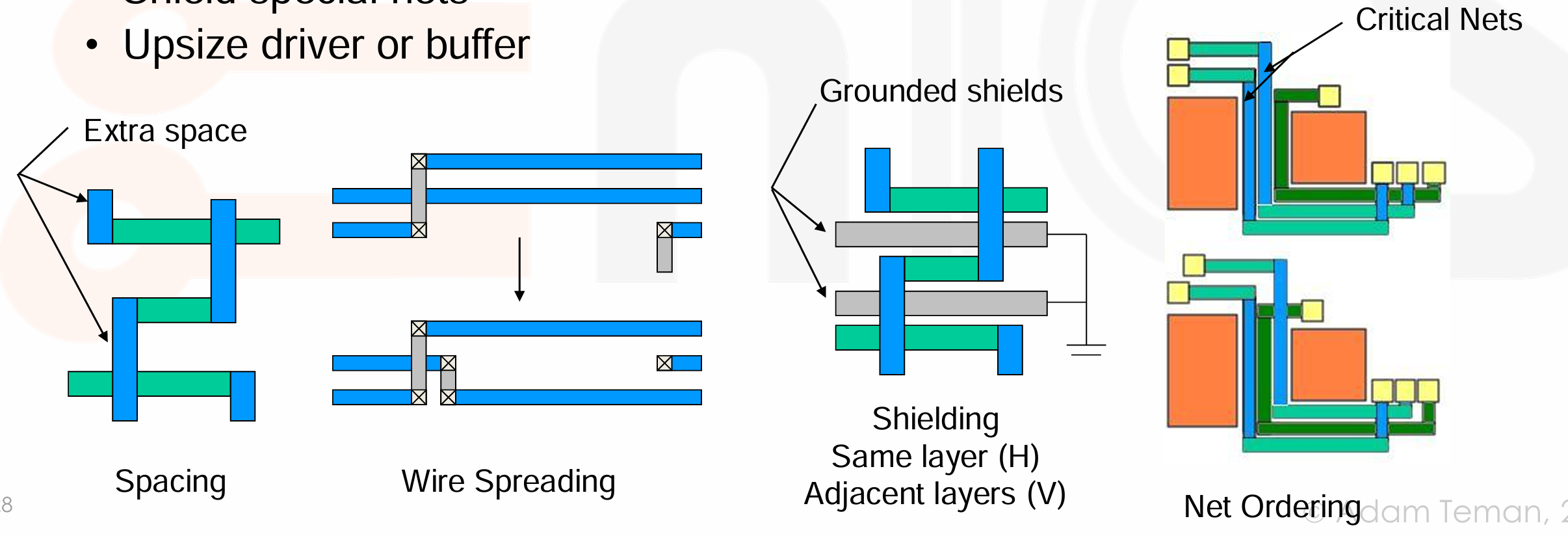
Crosstalk Prevention
- Limit length of parallel nets
- Wire spreading
- Shield special nets
- Upsize driver or buffer
Design For Manufacturing (DFM)¶
-
During route, apply additional design for manufacturing (DFM) and/or design for yield (DFY) rules.
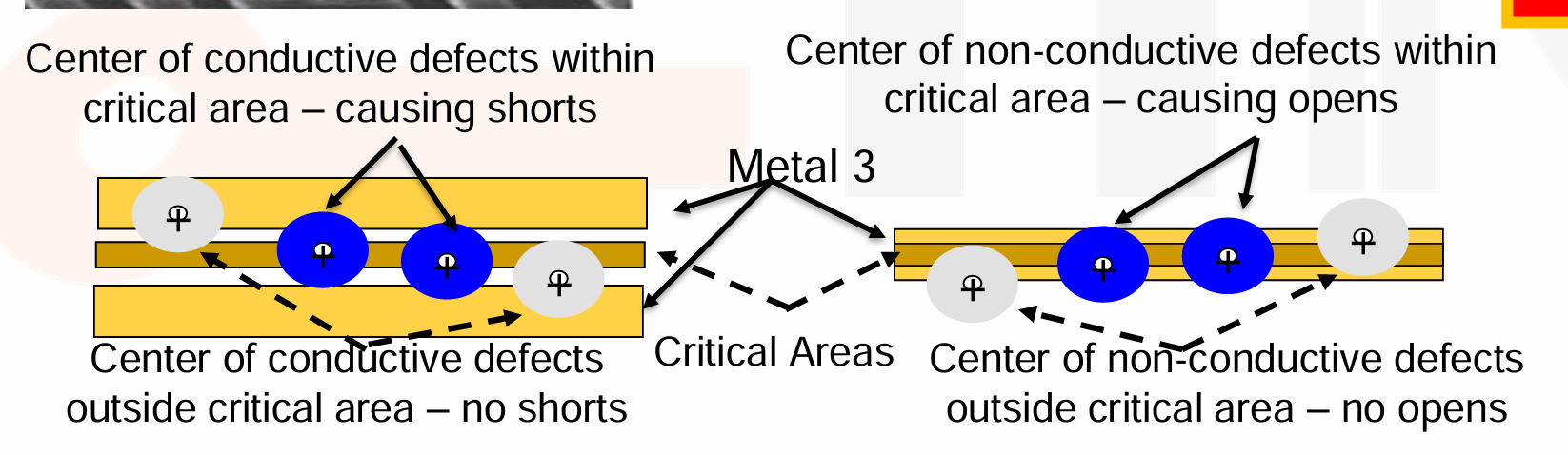
- Via Optimization
- via 电阻大,而且更容易内部出现缺陷。
- 因此我们可以使用 Post-Route Via Optimization,包括 incremental routing 来最小化使用的 vias,以及将单个 via 替换为 multi-cut vias。
-
Wire straightening

-
Wire spreading
- 线展开可以降低 capacitance,获得更好的 SI(减少串扰)。
- 更不容易受到短路或者开路的影响。
- Via Optimization
Routing in Innovus/Encounter¶

