CNN Architectures¶
约 1879 个字 17 张图片 预计阅读时间 6 分钟
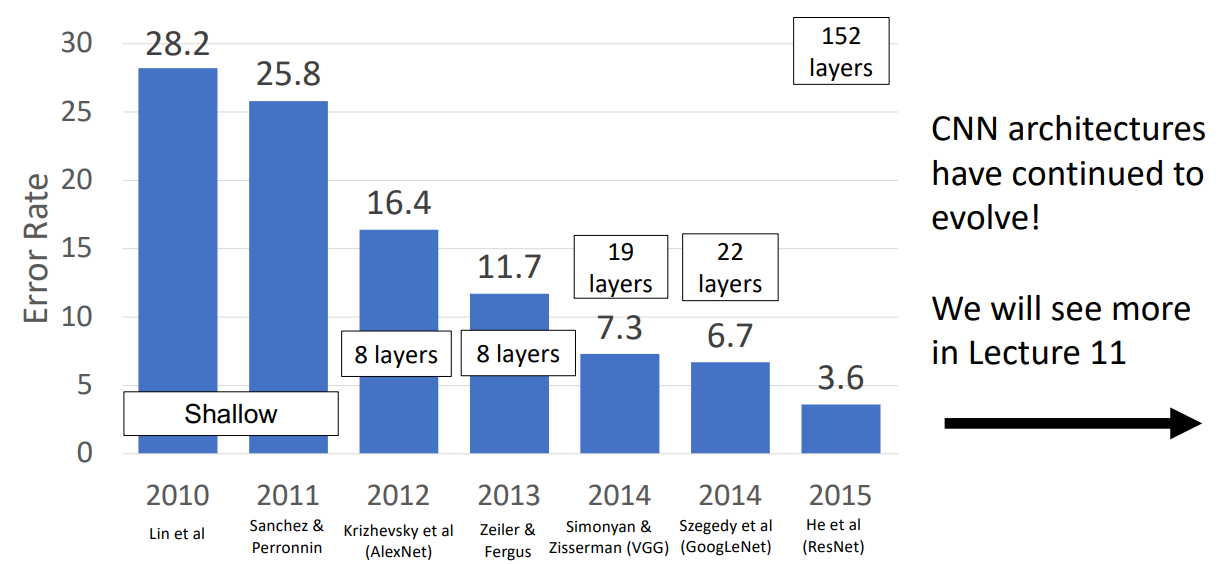
本节从历史角度,基于 ImageNet Classification Challenge 这个 benchmark 讲解著名的神经网络结构,尝试对下面的问题给出 insight:
Problem: What is the right way to combine all these components?
AlexNet¶
- 2012 年之前不是基于神经网络的,2012 年比赛的获胜者是 8 层的 AlexNet:
- 227 x 227 inputs
- 5 Convolutional layers
- Max pooling
- 3 fully-connected layers
- ReLU nonlinearities
- Used “Local response normalization” (Not used anymore)
- Trained on two GTX 580 GPUs – only 3GB of memory each! Model split over two GPUs.
-
网络具体配置:

-
Number of floating point operations
(multipl + add) = (number of output elements) * (ops per output elem)我们倾向于将乘法和加法共同作为单个操作来计算(multiply + add
) ,因此有上面的计算式,这个结果非常重要。 -
For pooling layer:
#output channels = #input channels- Pooling layers have no learnable parameters!
- 卷积层往往需要大量计算,池化层相比之下小很多。
- 实际上这里卷积层的确切配置经过了大量的试验和错误,但在实践中效果很好。
-
观察最后三列:Interesting trends here
-
Most of the memory usage is in the early convolution layers.
大部分内存消耗在早期的卷积层,这是因为前期的输入图像分辨率高,同时有更多的滤波器数量。
-
Nearly all parameters are in the fully-connected layers.
卷积层的参数很少,参数主要在全连接层,尤其是第一个。
-
Most floating-point ops occur in the convolution layers.
完全连接层需要很少的计算,因为只需要乘一个矩阵,然而卷积层需要很多计算。
这些趋势不止在 AlexNet 上,后来也是一种普遍趋势。

-
-
ZFNet¶
-
2013 年的优胜者是 8 layers ZFNet.
- 本质就是更大的 AlexNet.
-
尝试更多,错误更少,需要更多的内存和计算。基本思想类似,除了某些层的配置。

-
takeway from AlexNet to ZFNet: 更大的网络往往会工作得更好。
VCG¶
- 2014 年的优胜者是 VCG.
- Idea: Deeper Networks, Regular Design.
- AlextNet 有一定数量的卷积层、池化层,但每层的配置是通过反复试验手动独立设置的,这使得扩展缩小网络变得相当困难。
- 设计原则:
- All conv are 3x3 stride 1 pad 1
- All max pool are 2x2 stride 2
- After pool, double #channels
-
Network has 5 convolutional stages:
- Stage 1: conv-conv-pool
- Stage 2: conv-conv-pool
- Stage 3: conv-conv-pool
- Stage 4: conv-conv-conv-[conv]-pool
- Stage 5: conv-conv-conv-[conv]-pool
(VGG-19 has 4 conv in stages 4 and 5)
为什么选择这些设计原则?
-
为什么 3*3 卷积:
-
Two 3x3 conv has same receptive field as a single 5x5 conv, but has fewer parameters and takes less computation!
感受野大小相同,但是两个 3*3 卷积层 的参数、计算量更小
-
Insight:可能没必要使用更大的滤波器。我们关心的只是需要用多少 3*3 滤波器。
- 而且在 2 个 3*3 之间我们还可以插入 ReLU,提供了更多的深度和非线性。

-
-
为什么最大池化都是 2*2 步长为 2,且池化之后要双倍通道数:
-
Conv layers at each spatial resolution take the same amount of computation!
我们希望卷积层花费相同数量的浮点运算。
-
可以通过在卷积节点结束使用具有空间大小和双倍 channel 来做到。

-
AlexNet vs VGG-16: Much bigger network!
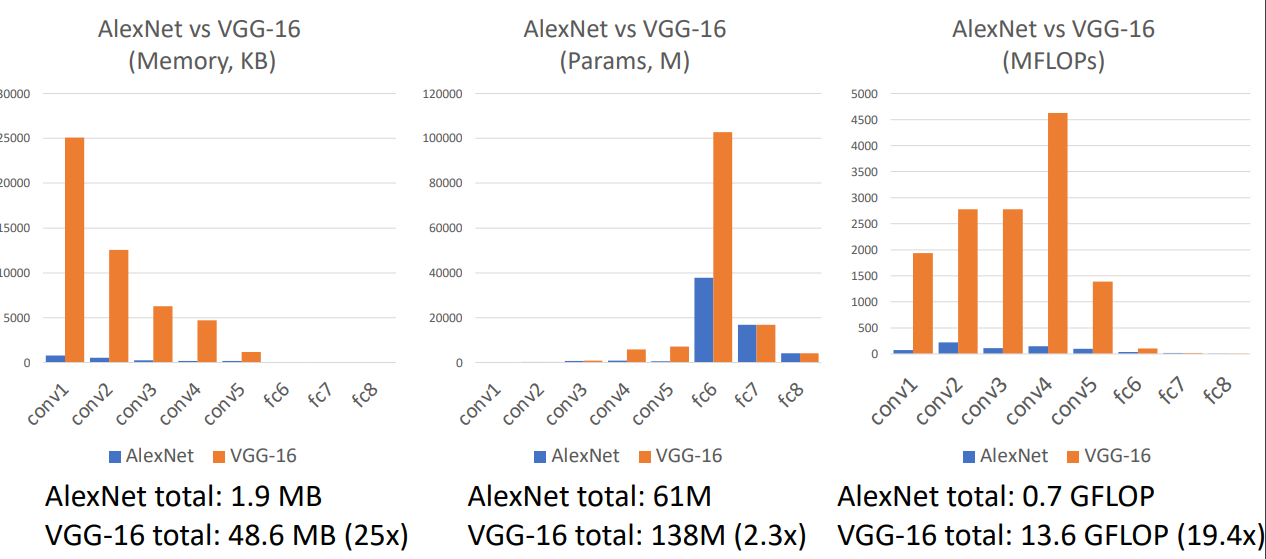
值得一提的是 VGG 巨大,但是数据并行,不用拆分模型。
GoogLeNet¶
-
2014 年还有一个重要的神经网络 GoogLeNet: Focus on Efficiency.
-
Many innovations for efficiency: reduce parameter count, memory usage, and computation
设计高效的神经网络,save money,降低复杂度。
-
-
网络具体配置:

-
Stem network at the start aggressively downsamples input
大空间特征图上的卷积很昂贵,为了避免这种情况,他们使用了快速下降的轻量级 stem,对输入进行采样。
-
Inception module
-
Local unit with parallel branches
引入了并行计算分支的想法。
-
Local structure repeated many times throughout the network.
卷积核大小是个超参数,我们希望避免这个参数。在 VGG 中固定使用了 3*3 的卷积,谷歌选择一直处理所有内核大小。不再需要调整卷积核大小。

上面的结构在网络中多次出现。
-
Uses 1x1 “Bottleneck” layers to reduce channel dimension before expensive conv (we will revisit this with ResNet!)
1*1 卷积被用来减少通道数量(在空间卷积前
) 。 -
-
No large FC layers at the end! Instead uses global average pooling to collapse spatial dimensions, and one linear layer to produce class scores
消除了全连接层,使用了不同的策略破坏空间:使用平均池化,核大小等于最后一个卷积的最终空间大小。
-
GoogleLetNet 出现在 BatchNorm 之前,那时训练超过 10 层的网络是很难的。
- Network is too deep, gradients don’t propagate cleanly
-
As a hack, attach “auxiliary classifiers” at several intermediate points in the network that also try to classify the image and receive loss
最后会收到三个分数,一个来自网络末端,两个来自中间部分。中间的分类器也要计算损失并传播梯度
。 (VGG 也用了一些其他的技巧) -
GoogLeNet was before batch normalization! With BatchNorm no longer need to use this trick.
Residual Networks¶
- 2015 年的优胜者是 ResNet. 神经网络的层数从 22 增加到了 152 层。
-
Problem: Deeper model does worse than shallow model!
超过了某个点后,更大更深的网络表现的更差。
- Initial guess: Deep model is overfitting since it is much bigger than the other model
-
In fact the deep model seems to be underfitting since it also performs worse than the shallow model on the training set! It is actually underfitting.
你可能认为发生了过拟合。但实际上看训练误差会发现其实还没有训练到位 under fitting。

-
A deeper model can emulate a shallower model: copy layers from shallower model, set extra layers to identity.
一个更深的模型应该能模拟更浅的模型,意味着我们更深的模型至少需要做的和更浅的模型一样好。
比如 20 层和 56 层的网络,实际上 56 层的网络可以只学习 20 层,其他层学习恒等函数。
-
Hypothesis: This is an optimization problem. Deeper models are harder to optimize, and in particular don’t learn identity functions to emulate shallow models.
-
Solution: Change the network so learning identity functions with extra layers is easy!

如果我们把这两个卷积的权重设为 0,那么我们就学习到了恒等函数。反向传播时,会复制上游梯度到每个输入,这样做也有利于改善梯度信息。
- A residual network is a stack of many residual blocks.
- Regular design, like VGG: each residual block has two 3x3 conv.
- Network is divided into stages: the first block of each stage halves the resolution (with stride-2 conv) and doubles the number of channels.
- as GoogleNet Uses the same aggressive stem to downsample the input 4x before applying residual blocks; global average pooling and a single linear layer at the end
Example

-
Basic & Bottleneck Block: More layers, less computational cost!

上图可以看到,我们可以采用 bottleneck block 的方法,减少计算量,同时增加深度。
-
ResNet-50 is the same as ResNet-34, but replaces Basic blocks with Bottleneck Blocks. This is a great baseline architecture for many tasks even today!
- Deeper ResNet-101 and ResNet-152 models are more accurate, but also more computationally heavy.
- Able to train very deep networks
- Deeper networks do better than shallow networks (as expected)
- Swept 1st place in all ILSVRC and COCO 2015 competitions
- Still widely used today
Improving ResNets: Block Design¶
- Slight improvement in accuracy (ImageNet top-1 error).
- Not actually used that much in practice.
Improving ResNets: ResNeXt¶
如果一个瓶颈分支很好,那可以并行做多个瓶颈分支。
Summary¶
Comparing Complexity
右图半径是网络的参数量,横坐标是计算量,纵坐标是准确率,越靠左上效果越好。

Summary
- Don’t be heroes. For most problems you should use an off-the-shelf architectures; don’t try to design your own.
- If you just care about accuracy, ResNet-50 or ResNet-101 are great choices.
- If you want an efficient network(real-time, run on mobile, etc) try MobileNets and ShuffleNets.