Recovery System¶
约 2374 个字 17 张图片 预计阅读时间 8 分钟
Failure Classification¶

- Database application
逻辑错误:比如不满足数据库约束条件(主键) 系统错误:死锁。 常用方法是撤销 undo, 把这个事件抹掉。(基于日志,在产生修改之前先记日志,故障后可以根据日志进行撤销)
记日志比较快(顺序访问) - DBMS
掉电、硬件故障、软件故障
system crash 是全局性的,所有运行的程序都会受到影响。分为两类:一类是事务已经提交(但是数据还在缓冲区),另一类是正在执行的事务(还没有提交)。
已经提交的事务要 redo(数据可能没写回去), 没有完成的事务要 undo. 先记日志,现在的数据库采用 repeating history 的方法。 - Database
介质故障
要防止介质故障,需要做备份(拷贝或者远程)
Storage Structure¶
日志可能也会出故障?我们假设日志存储在 Stable storage 里。
- Volatile storage
- Nonvolatile storage
survives system crashes - Stable storage:
- a mythical( 虚拟的 ) form of storage that survives all failures
- approximated by maintaining multiple copies on distinct nonvolatile media
可以近似实现
Implementation¶
- Maintain multiple copies of each block on separate disks
- Failure during data transfer can still result in inconsistent copies
修改过程中可能发生故障 - Protecting storage media from failure during data transfer
Database Recovery¶
Recovery algorithms are techniques to ensure database consistency and transaction atomicity and durability despite failures.
Recovery algorithms have two parts
- Actions taken during normal transaction processing to ensure enough information exists to recover from failures
先记日志 - Actions taken after a failure to recover the database contents to a state that ensures atomicity, consistency and durability
理想的算法:恢复得很快,对事务正常操作没有影响(记录信息的时候不能消耗太多性能
We assume that strict two-phase locking ensures no dirty read.
使用严格两阶段封锁协议保证没有脏数据。
Idempotent( 幂等性 ): An recovery algorithm is said to be idempotent if executing it several times gives the same result as executing it once.
算法恢复多次的效果是一样的。(恢复过程中可能也发生 crash)
Log-Based Recovery¶
Log Records¶

A log is kept on stable storage( 稳定存储器 ).
The log is a sequence of log records, and maintains a record of update activities on the database.
- When transaction Ti starts, it registers itself by writing a “start” log record: \(<T_i\ start>\)
事务开始. Ti 表示事务的 id. - Before Ti executes write(X), writing “update” log record \(<T_i, X, V_1, V_2>\)
事务把 X 数据项的值从 V1(old value) 改为 V2(new value).
这个就是恢复的基础. undo 就用 old value, redo 用 new value.
Insert 就是 old 为空, Delete 就是 new 为空。 - When Ti finishes it last statement, writing “commit” log record: \(<T_i\ commit>\)
- When Ti complete rollback, writing “abort” log record: \(<T_i\ abort>\)
Log Example

这里当执行到 T2 回滚的时候我们会进行恢复(绿色的行表示补偿日志)比如 T2 把 C 恢复为 500, T3 把 B 恢复为 300, 最后 T2 abort. (undo 操作也会记录到日志中 )
发生 crash 的时候 repeat history(undo 正常的操作也会重复), 随后得到并执行 undo list.(事务开始后先把事务放进去,如果提交或者回滚了就把事务移除) 只需要把 T4 undo.(假设故障前只执行到 15 行)
Write-Ahead Logging¶
Before a data in main memory is output to the database, the log records pertaining to data must have been output to stable storage.
先写日志原则。
数据修改之前,和数据有关的记录要先写入日志。
Transaction Commit¶
A transaction is said to have committed when its commit log record is output to stable storage
日志已经记录 commit, 说明事务已经提交。(因为后续可以根据这个恢复状态了)
但此时数据不一定已经写回到数据库里(不一定高校)
all previous log records of the transaction must have been output already
Writes performed by a transaction may still be in the buffer when the transaction commits, and may be output later.
不一定在磁盘。如果立刻将 block 写回磁盘可能引起大量 I/O 操作
Undo( 撤销 ) and Redo(重做) Operations¶
Checkpoints¶
Redoing/undoing all transactions recorded in the log can be very slow.
Streamline recovery procedure by periodically performing checkpointing.
重演历史可能很长。checkpoint 是确认之前的操作都已经反映到数据库里去了,这样重演的时候就可以直接从 checkpoint 开始。
- Output all log records currently residing in main memory onto stable storage.
日志不是生成就往内存写,而是有一个日志缓冲区。
确保把日志项写到日志中去了。 - Output all modified buffer blocks to the disk.
把 buffer 里所有数据都刷写一遍。 - Write a log record \(<checkpoint\ L>\) onto stable storage where L is a list of all transactions active at the time of checkpoint.
写一个日志的标记(新的日志类型). L 是当前正在工作的事务的表。(用来做 undo list 的初始化列表) - All updates are stopped while doing checkpointing!!! 做 checkpoint 的时候其他活跃事务都要停下来。
Log File with Checkpoint : Example

重演历史从最近的 checkpoint 重演 . {T2 T4} 作为 undo list 的初始化值。
checkpoint 之间的间隔应该如何确定?
根据日志量。
Example of Recovery

Log Record Buffering¶
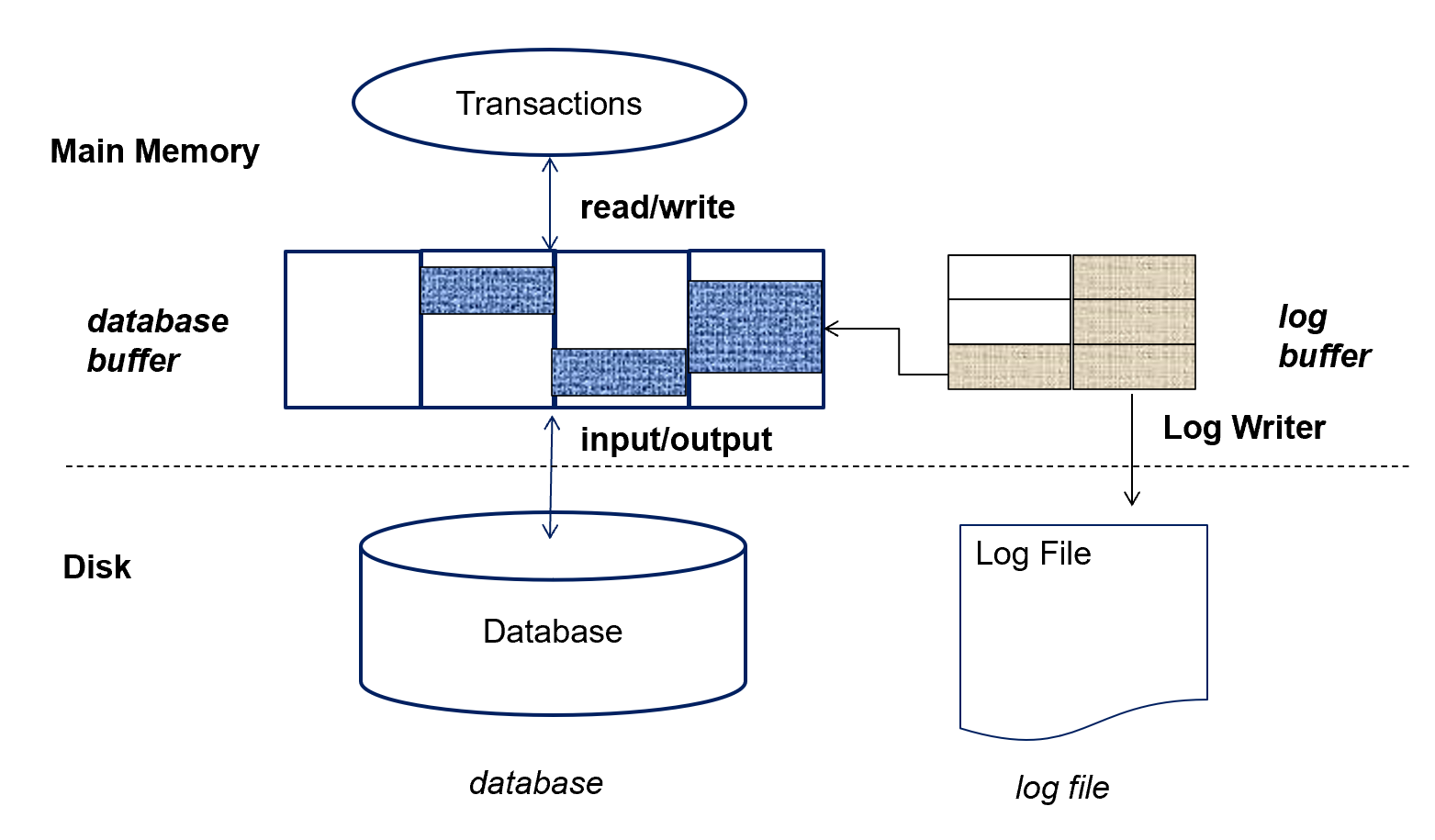
我们在把数据 buffer 中的块写到数据库时,要先把块对应的日志先写到日志文件(直接把日志全部刷写一遍
事务提交之后有一个对日志的强制刷写。
Group commit: several log records can be output using a single output operation, reducing the I/O cost. commit 可能在日志里等待一段时间, 等到 buffer 里有足够多的日志记录再写出去。
- The recovery algorithm supports the no-force policy( 非强制 ): i.e., updated blocks need not be written to disk when transaction commits.
好的恢复算法:我事务 commit 了但不强制日志刷写出去。 - The recovery algorithm supports the steal policy( 窃取策略 ):i.e., blocks containing updates of uncommitted transactions can be written to disk, even before the transaction commits. 事务提交之前脏数据能不能被写到磁盘里去?(同样地需要先把日志写出去)
Fuzzy Checkpointing¶
Fuzzy 模糊
做 checkpoint 的时候我们如果要求其他活跃事务都停下来,一次性把脏数据都刷写出去,吞吐率会忽高忽低,系统的可用性就比较差。
记录脏数据,在后面不 check 的时候慢慢写。
- Temporarily stop all updates by transactions
- Write a \(<checkpoint\ L>\) log record and force log to stable storage
- Note list M of modified buffer blocks
- Now permit transactions to proceed with their actions
- Output to disk all modified buffer blocks in list M

在把所有脏数据都写回磁盘后,我们会认定这个 checkpoint. 有一个指针指向最近一次成功的 checkpoint.
这样 checkpoint 的时候就只需要记录一下,不用一下子写脏数据了。
Failure with Loss of Nonvolatile Storage¶

Can be extended to allow transactions to be active during dump; known as fuzzy dump or online dump.
类似于 checkpoint, 不是完全备份,而是记录一下,随后慢慢备份。
Recovery with Early Lock Release and Logical Undo Operations¶
Logical Undo Logging¶
如果早放锁,后续恢复为 old value 可能没有意义。比如存款 100, 转入 100. 那么我们恢复为 100( 物理撤销 ) 就没有意义。这个时候应该采用逻辑撤销,即如果a+=100 , 恢复时就应该a-=100 .

如 B+ 树的插入和删除操作。
我们需要对逻辑操作记日志。
Transaction Rollback with Logical Undo

需要把每个操作的日志项记录下来(开始和结束). C 表示自加操作。这里在 end 时会记录 logical undo 的操作 ( 减法撤销对应加法 )
注意我们是在 end 的时候记录逻辑撤销的方法,如果这个操作还没有结束,那么我们只能物理撤销。
这里我们早放锁了,没有遵循严格两阶段放锁协议。在 T0 还没有提交的时候 T1 就对数据进行了修改.
恢复中做的是物理撤销(old+new), begin/end 这些日志就不需要记录了。
Failure Recovery with Logical Undo
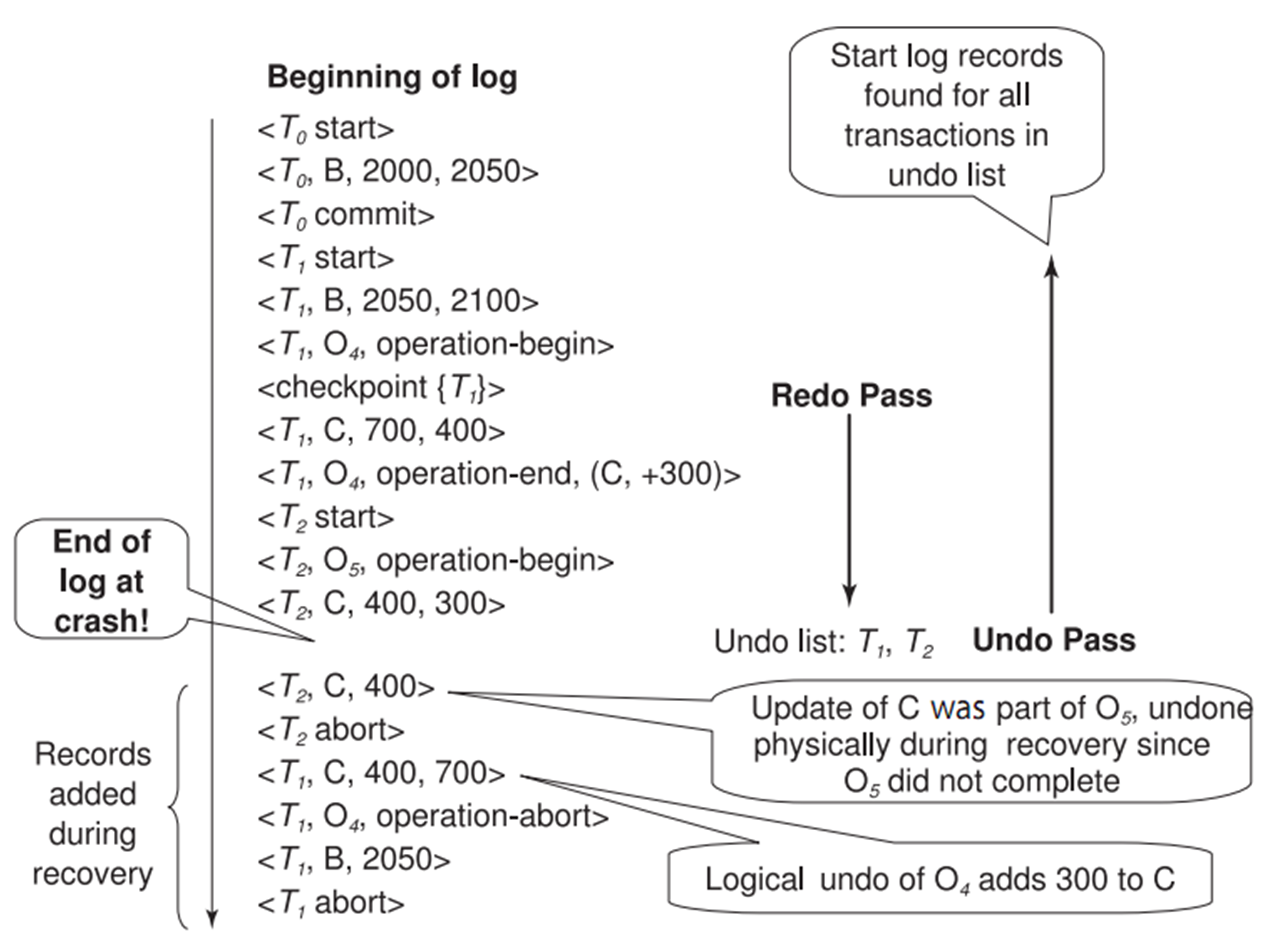
这里还没有 T2 end, 因此物理撤销。
ARIES Recovery Algorithm¶
ARIES is a state of the art recovery method.
每个日志都有一个日志编号 log sequence number (LSN)
每个数据块里都会记一个 LSN, 表示这个块反应了最近哪个日志的操作。
ARIES Data Structures¶
- Log sequence number (LSN) identifies each log record
- Must be sequentially increasing
- Page LSN
每个页(块的 LSN) - Log records of several different types
- Dirty page table
脏页表要记录在日志中。
Log Record

日志记录通过 UndoNextLSN 串起来,提高恢复效率。
DirtyPage Table
- PageLSN of the page
- RecLSN is an LSN such that log records before this LSN have already been applied to the page version on disk 每一页都有 PageLSN 和 RecLSN, Rec 反应的是最近的被反映到数据库的日志。
ARIES Data Structures

这里 4894.1 表示这个块里的第一个数据。 RecLSN 表示 7564 开始数据就没有反映到数据库中去了。
- Checkpoint log record
- Contains:
- DirtyPageTable and list of active transactions
- For each active transaction, LastLSN, the LSN of the last log record written by the transaction
要记最近的事务项(从哪里开始恢复)
- Fixed position on disk notes LSN of last completed checkpoint log record
- Contains:
- Dirty pages are not written out at checkpoint time
Instead, they are flushed out continuously, in the background
脏页不会在 check 的时候写出去。 - Checkpoint is thus very low overhead can be done frequently
ARIES Recovery Algorithm¶
- Analysis pass
- Which transactions to undo (undo-list)
- Which pages were dirty (disk version not up to date) at time of crash
得到 dirty page table. - RedoLSN: LSN from which redo should start
真正的 redo 要从哪里开始(RecLSN 的最小值就是 redo 的起点)
- Redo pass
从 RedoLSN 开始重演
RecLSN and PageLSNs are used to avoid redoing actions already reflected on page.
用来优化,有些日志不用 redo(没有意义) - Undo pass
把 undolist 进行撤销操作。
Example

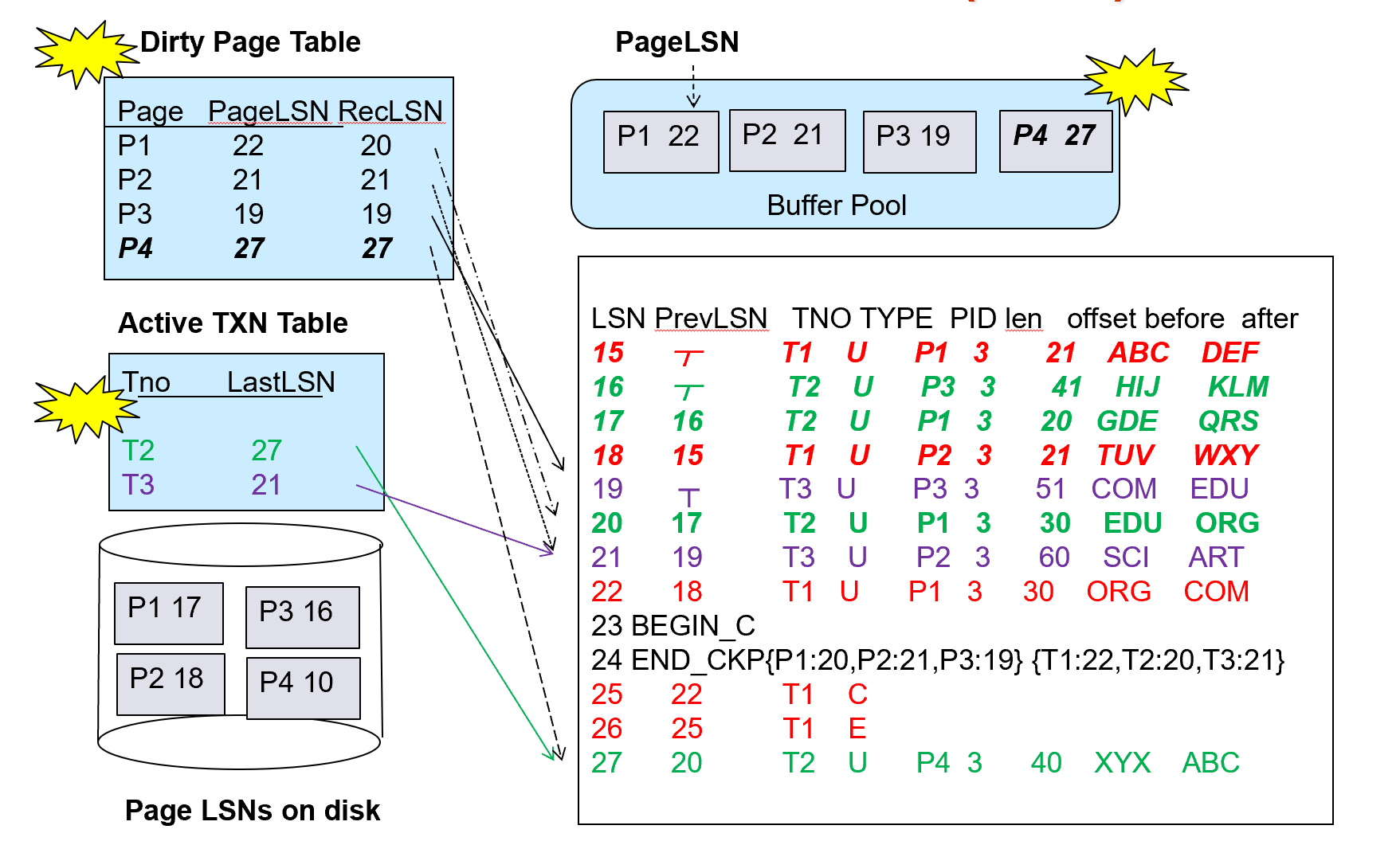
crash 之后,得到上页的 Dirty Page Table 和 Active TXN Table 以及磁盘里的日志。
Example
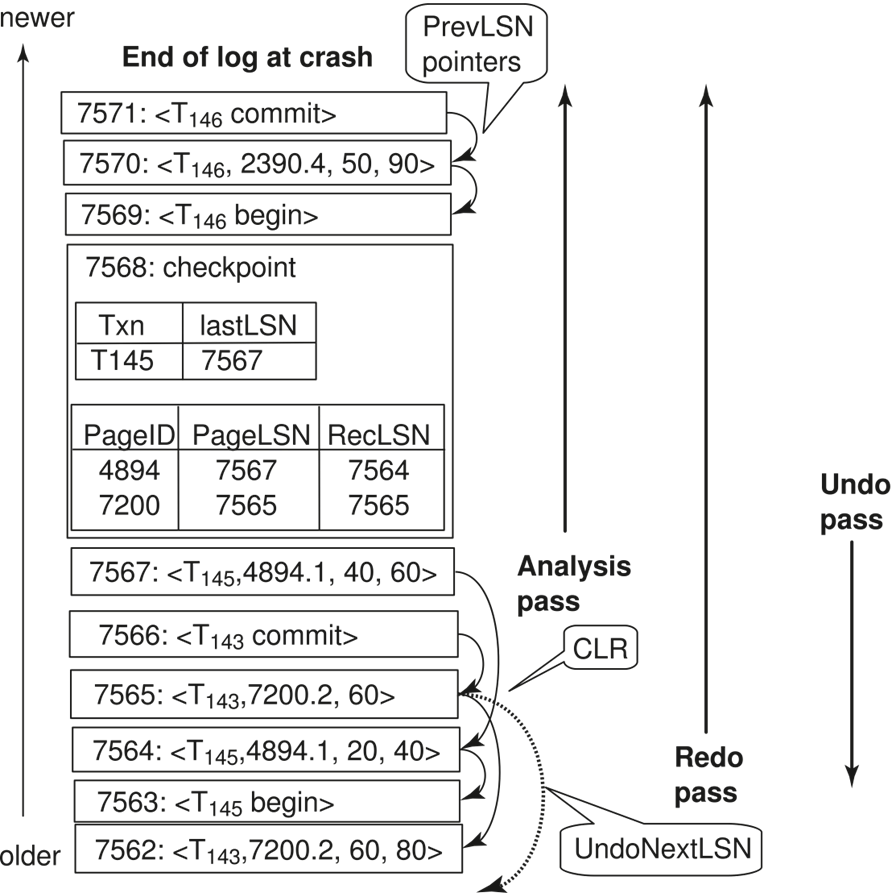
要把 2390 加到表里去。