深度学习简介 ¶
约 670 个字 19 张图片 预计阅读时间 2 分钟

- 特征不能学习 / 训练的
- 分类器通常是可训练的,如 SVM, HMM...
特征非常重要,很多特征都是为了特定的任务而手工设计,但手工设计一个特征提取需要相当大的努力。

- 为了特定的识别任务,找到更适合的特征,以可训练的方式提取特征
- 学习统计结构或者数据与数据之间的相互关系得到特征表达
- 学习得到的特征表达可以用来作为识别任务中的特征


CNN 卷积神经网络
- CNN 是少有的可以监督训练的深度模型,而且容易理解、实现。
神经
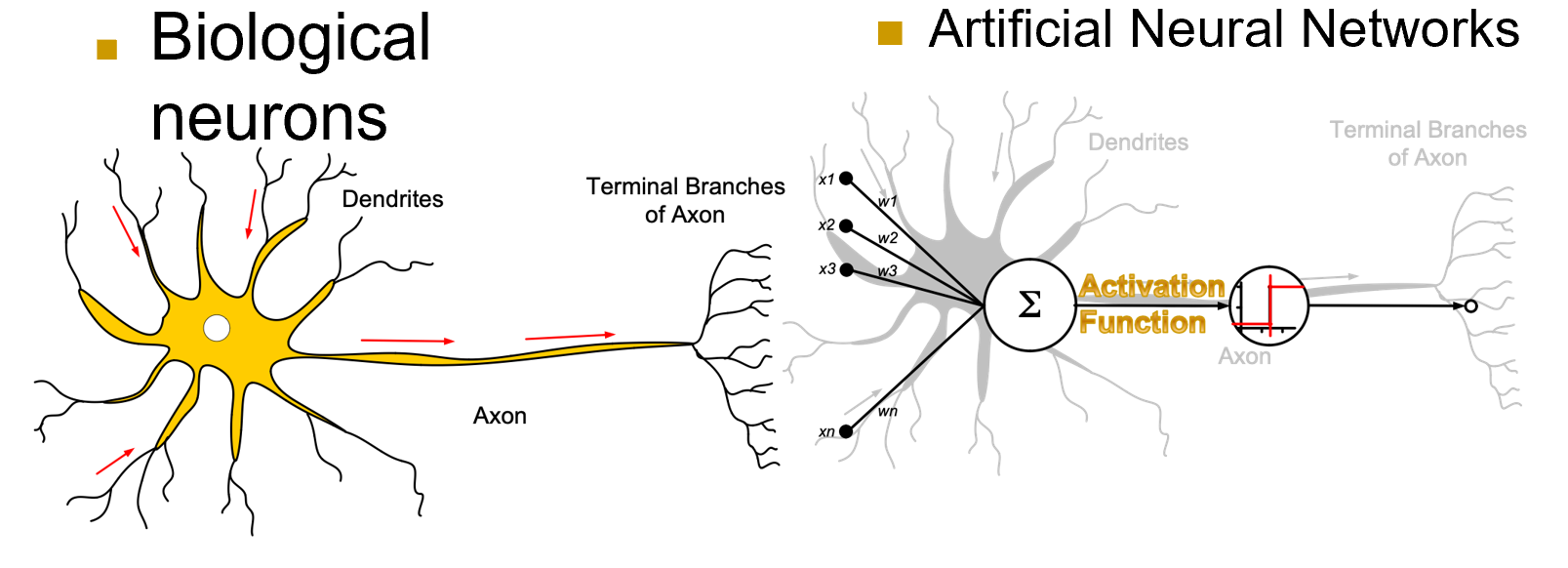
人工神经网络,对突触的观测值连到汇总的地方,并进行加权求和,通过激活函数产生输出

\(w_0\) 用于矫正数据的偏置量 Bias
常用的激活函数
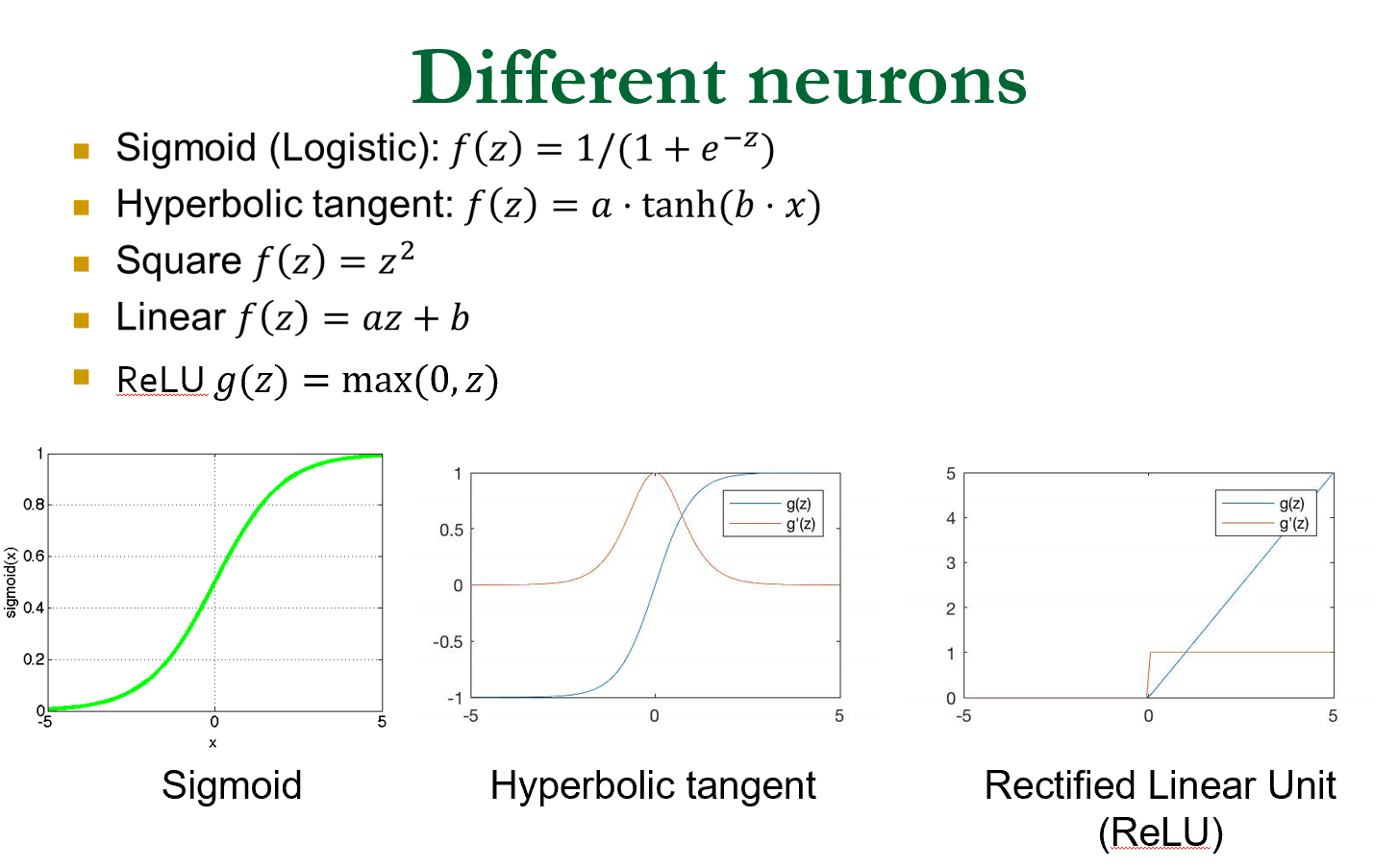
ReLU 会把输入的信号去掉一部分
多层神经网络

如何解深度神经网络 ( 解,指求出 \(w\))
反向传播 Back-propagation(BP)
- 随机初始化权重,计算 \(h_W(X)\)
- 计算误差 \(E=(h_W(X)-y)^2\)
- \(W_k=W_{k-1}-\epsilon \frac{\partial E}{\partial W}\) 特别地 , \(w_{ij}^{(k)}=w_{ij}^{(k-1)}-\epsilon \frac{\partial E}{\partial w_{ij}^{(k-1)}}\) 梯度下降法
\(\epsilon\) 是个超参,称为学习率。如果设置过大可能会在收敛的两边剧烈震荡;如果过小容易陷入局部最优爬不出来,以及收敛更慢。

共享权重
设计一个卷积核用来提取特征,得到一个新的图像 feature map 特征图。
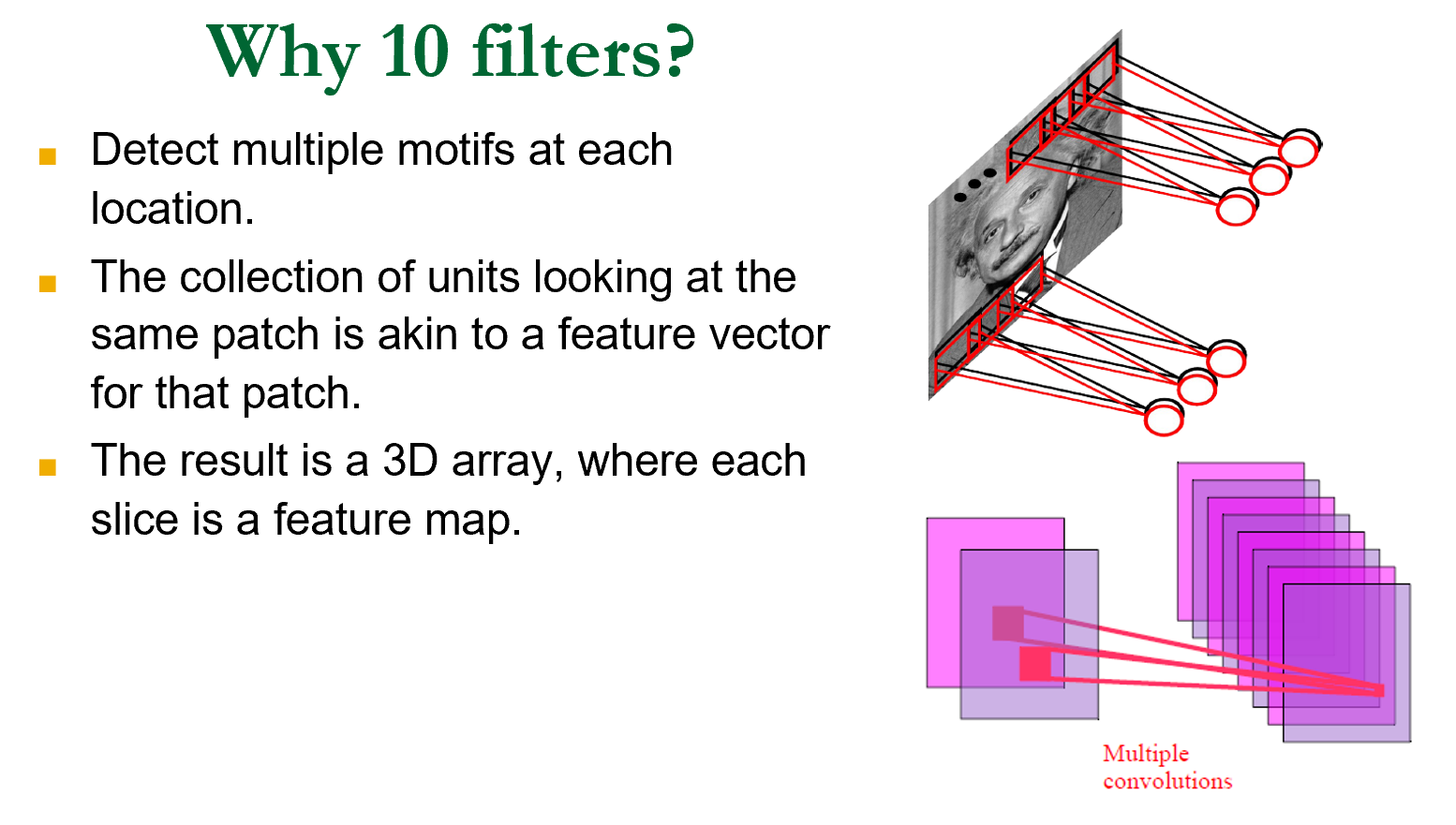
10 个卷积核得到 10 张特征图,形成一个三维的特征体。
卷积核可以复用
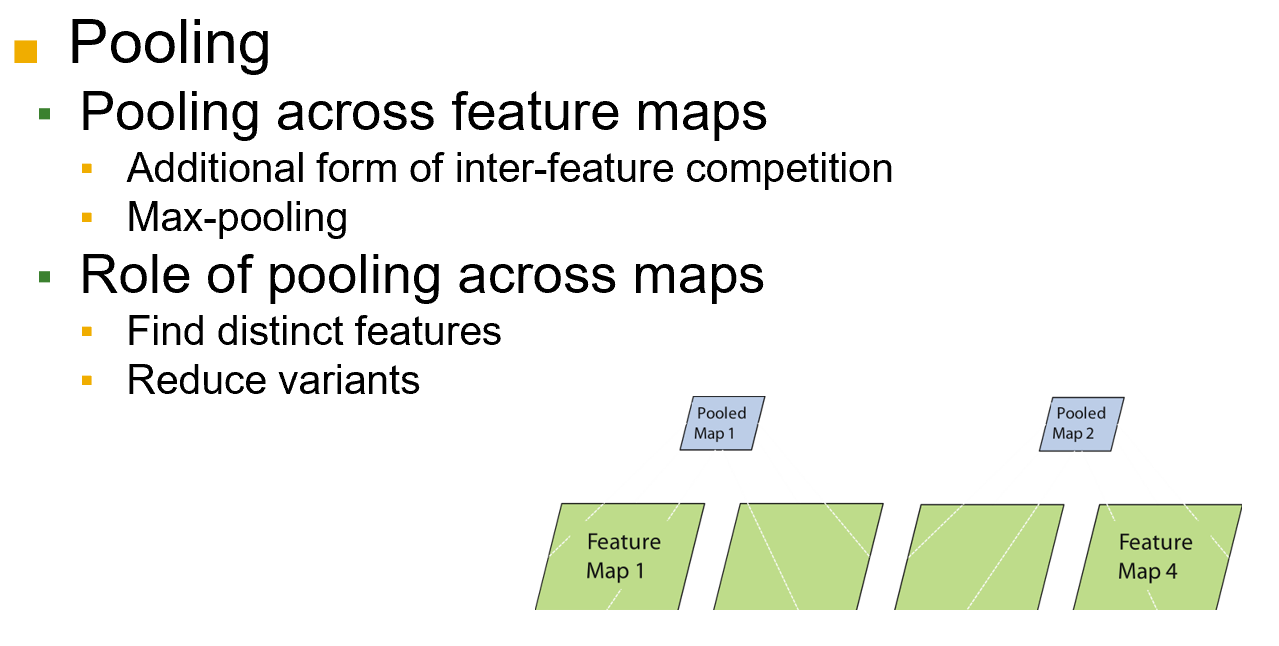
简单的细胞检测局部特征;复杂的细胞会池化,筛选提取特征(特征图的降采样)
池化:

空间,选择重要的值,降低复杂度
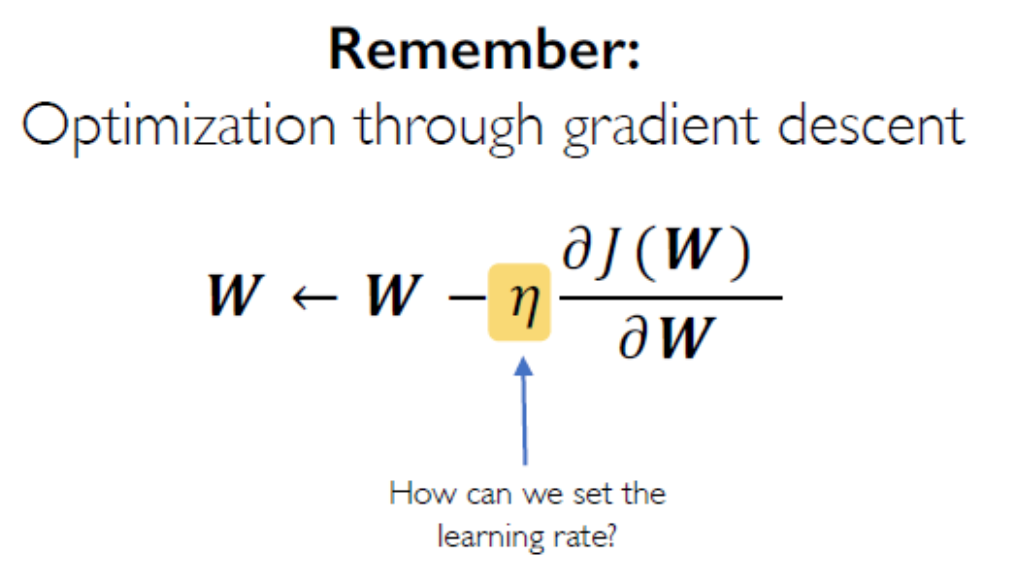
是通过梯度下降的方法来优化,如何设置学习率?
学习率低,收敛慢,容易掉到坑里陷入局部最优;学习率高,可能使得收敛过程不稳定,来回震荡,一直不收敛
idea:
- 设置不同的学习率,看哪种情况最好
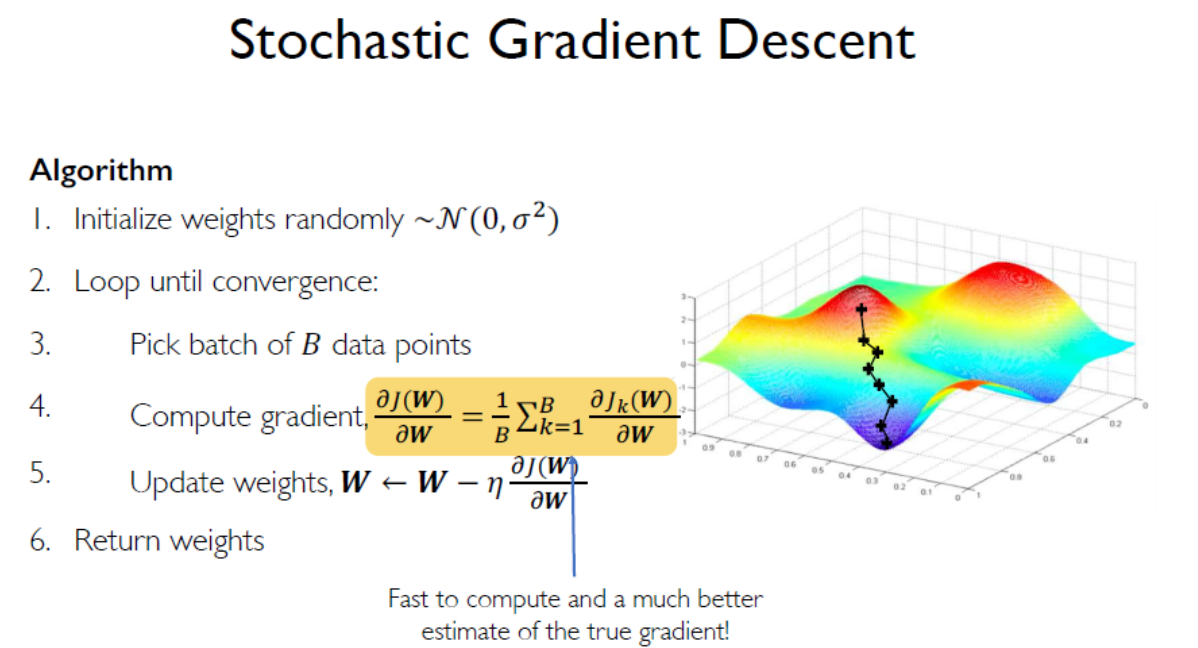
- 设计一个自适应学习率。此时学习率不再固定,可以通过外在条件算 ( 梯度,学习要有多快,特征权重的大小 ...)

第三步的梯度,可以很容易的算出
如果我们随机选一个点,很容易被噪点影响。所以我们用一个 batch B
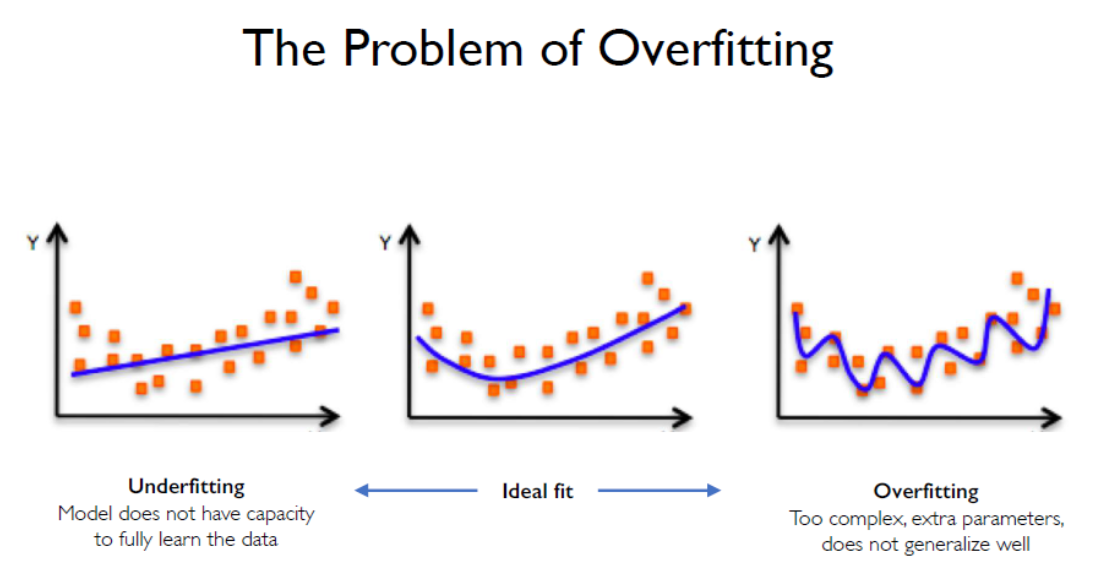
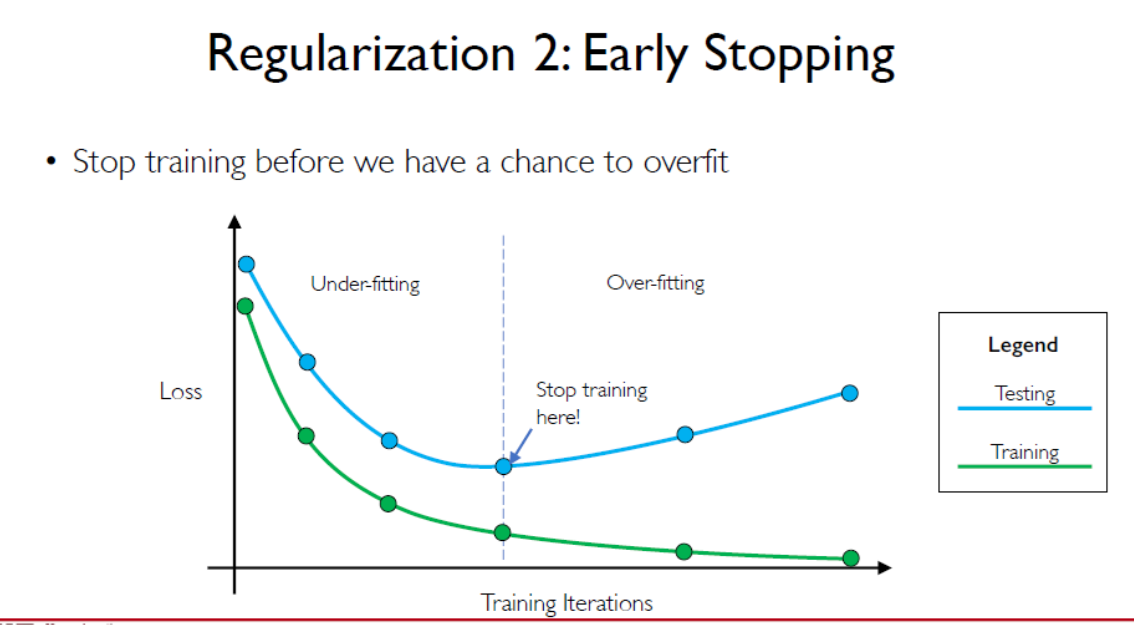
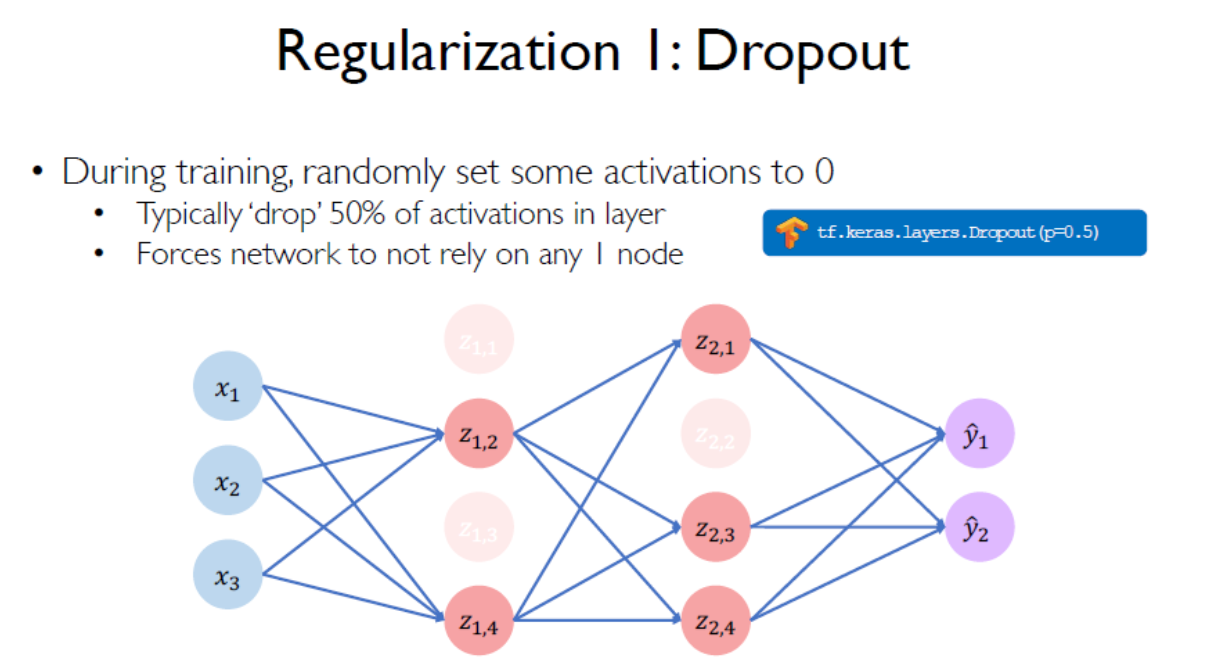
正则化:dropout 丢掉一半,防止过拟合
早停法,见好就收