混合精度训练 ¶
约 1627 个字 6 张图片 预计阅读时间 5 分钟
Abstract

- Paper: Mixed Precision Training
- ICLR 2018: International Conference on Learning Representations
- 本文中的图片部分来自文章,部分来自网络。
介绍 ¶
摘要 ¶
- 增加神经网络的规模通常会提高精度,但同时也会增加训练模型所需的内存和计算量。
- 本论文提出了使用半精度浮点数(half-precision,FP16)训练模型的方法,且不会损失精度,也不需要修改超参数。具体来说,将权重、激活值、梯度均以 FP16 的格式存储。
- 为了防止关键信息的丢失,论文提出了 3 个技术:
- 保存单精度浮点数(FP32)的 master copy,用于更新权重。
- 对损失缩放(loss scale
) ,防止小梯度的消失。 - 使用半精度算术:计算过程中使用 FP32 精度,最后存储回内存时转为 FP16。
- 论文证明了所提出的方法适用于各种任务和现代大规模(超过 1 亿个参数)模型架构,并在大型数据集上进行了训练。
导言与背景 ¶
任何程序(包括神经网络训练和推理)的性能(速度)都会受到以下三个因素之一的限制:算术带宽、内存带宽或延迟。本论文提出的方法可以改善前两者。
FP16 的格式如下:
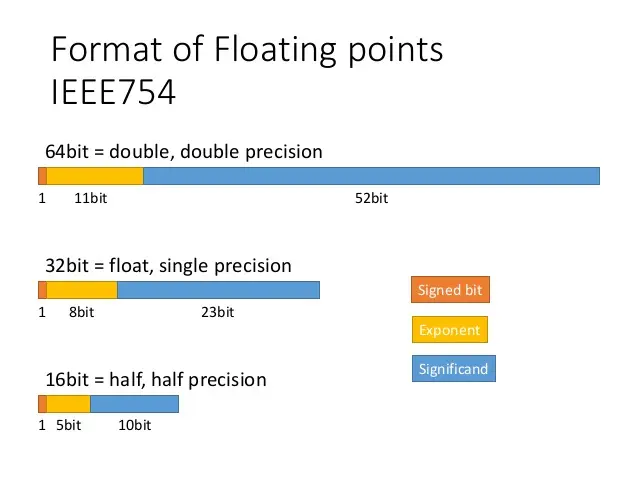
有 5 位阶码,\(bias=15\),10 位尾数,可表示的正数范围从 \([2^{-24}, 65504]\).
FP16

算法 ¶
FP32 权重主副本 ¶
在混合精度训练里,权重、激活值、梯度均是 FP16,用于前向传递和反向传递的权重都是 FP16 的。但同时我们把权重的 FP32 的主副本保存下来,在优化器更新权重时使用(即更新时主权重和更新值均使用 FP32 格式
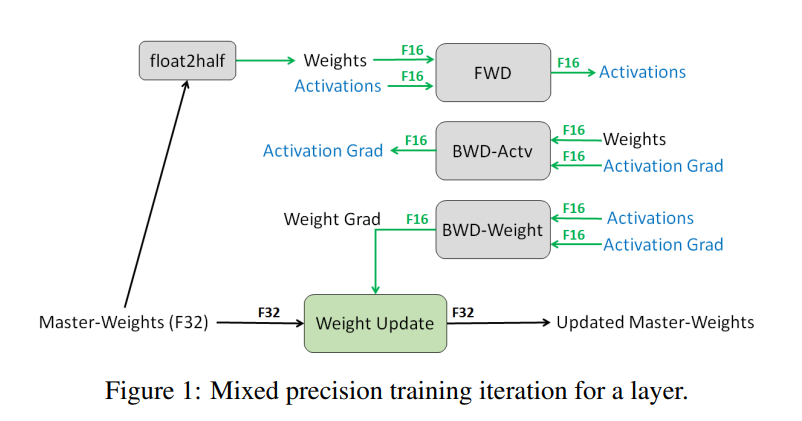
保存 FP32 权重主副本的原因有两个:
- 下溢出问题:更新值可能很小(权重梯度乘上学习率
) ,在 FP16 中如果小于 \(2^{-24}\) 那么就是 0 了。可以看到约有 5% 的权重梯度值会发生下溢出,进而影响模型精度。而使用 FP32 权重来更新,就可以规避这个问题。 - 舍入误差问题:当权重值值很大,但是权重更新值很小时,在 FP16 中会发生舍入误差。回顾浮点数加法,我们要对齐指数,而且是小的往大的对齐。那么如果权重值是权重更新值的 \(2^{11}=2048\) 甚至更大,那么我们在做对齐的时候会 10 位尾数和前导 1 全部移掉(\(1.frac\)
) ,这样这个值在 FP16 下就是 0 了。通过 FP32 更新可以抵消这个问题。
为了说明单精度 FP32 副本的必要性,发现在经过 FP16 前向和后向传递后更新权重的 FP32 主副本时,我们的训练结果与 FP32 一致。而更新 FP16 权重则会导致 80% 的相对准确率损失。
在训练中,内存消耗主要是激活值,激活也以半精度格式存储,因此训练深度神经网络的总体内存消耗大约减少了一半。
损失缩放 ¶
下面是 Multibox SSD 检测器网络在 FP32 训练过程中收集的各层激活梯度值直方图。可以看到,FP16 的大部分可表示范围都未使用,而许多值都低于最小可表示范围,变成了零。因此如果直接使用 FP16 进行训练,网络是发散的。但如果我们把梯度缩放 8 倍(指数增加 3 倍

为此论文提出了 loss scaling(损失缩放)的技术。在反向传播开始前,对前向计算(forward pass)的损失值进行缩放,这样反向传播计算的梯度也会有相应的缩放,避免了梯度变为 0。在更新权重之前,我们要对权重梯度进行反缩放(unscale

可以选择一个恒定的缩放因子,论文使用了 8 到 32K 训练了各种网络;可以根据经验选择。如果有梯度统计数据,可以选择一个较大的因子,同时保证其与最大绝对梯度值的乘积小于 65504(FP16 的最大值
- 通过检查计算出的权重梯度,例如权重梯度值未缩放时,可以有效地检测到溢出。一种方法是在检测到溢出时跳过权重更新,直接进入下一次迭代。
半精度算术 ¶
神经网络运算可分为三类,为此我们的半精度算术有相应的计算方法:
- 向量点积(vector dot-products
) :向量点乘并累加时,使用 FP32 精度,最后存储回内存时转为 FP16。 - 还原(reductions
) :从内存中读写 FP16 张量,并在 FP32 中进行运算。 - 逐点运算(point-wise operations
) :算术精度不会影响这些运算的速度,因此可以使用 FP16 或 FP32 数学运算。
其中还原和逐点运算受内存带宽限制,对运算速度并不敏感,因此这样做并不会减慢训练过程。
实验 ¶
论文中对分类任务(ILSVRC/ImageNet
- baseline:权重、梯度、激活值都是单精度存储,运算也是在 FP32 下进行。
- 混合精度(Mixed Precision, MP
) :FP16 用于存储和运算。权重、激活和梯度使用 FP16 存储,权重的 FP32 主副本用于更新。损失缩放用于某些应用。运算过程中使用 Tensor Cores 将累加过程(卷积层、全连接层、矩阵相乘)转为 FP32 来计算。
实验结果基本与单精度的结果一致,甚至有些任务的精度还有所提高。
结论 ¶
- FP32 copy 解决的是 update 时的下溢出问题。
- Loss scaling 解决的是梯度的下溢出问题。
- 半精度算术解决的是激活值的下溢出问题。
参考资料 ¶
- Youtube 视频“NVIDIA Developer How To Series: Mixed-Precision Training”
- 知乎文章
“ 【PyTorch】唯快不破:基于 Apex 的混合精度加速”,内有详细的 FP16 的优点、不足介绍,以及如何在 apex 中使用。