VecPAC:可向量化且具有精度感知的 CGRA ¶
约 1064 个字 6 张图片 预计阅读时间 4 分钟
Abstract

- Paper: VecPAC: A Vectorizable and Precision-Aware CGRA
- ICCAD 2023: IEEE International Conference on Computer-Aided Design
- Code: https://github.com/tancheng/VectorCGRA
介绍 ¶
CGRA - acclerator,可以在性能和适应性之间实现平衡,具体介绍可见 CGRA 介绍 .
现有的 CGRA 要么专注于特定领域,不能有效地处理其他领域的应用;要么通过额外的 FU 来支持向量化和专有的数字格式,但这会影响 energy 和 area efficiency. 提高效率的一个方法是在向量化单元的层面支持可重构,即 trade-off 向量化 lane 数量(即一个向量包含多少个数据)和精度。
本文贡献:
- 新的 hybrid CGRA 架构 VecPAC,其中既有 scalar FU 又有 vector FU。
- 可以实现向量化通道数和精度的 trade-off。
- 用于映射可矢量化应用程序的软件堆栈
。 (编译器可以支持向量化的映射)
动机 ¶
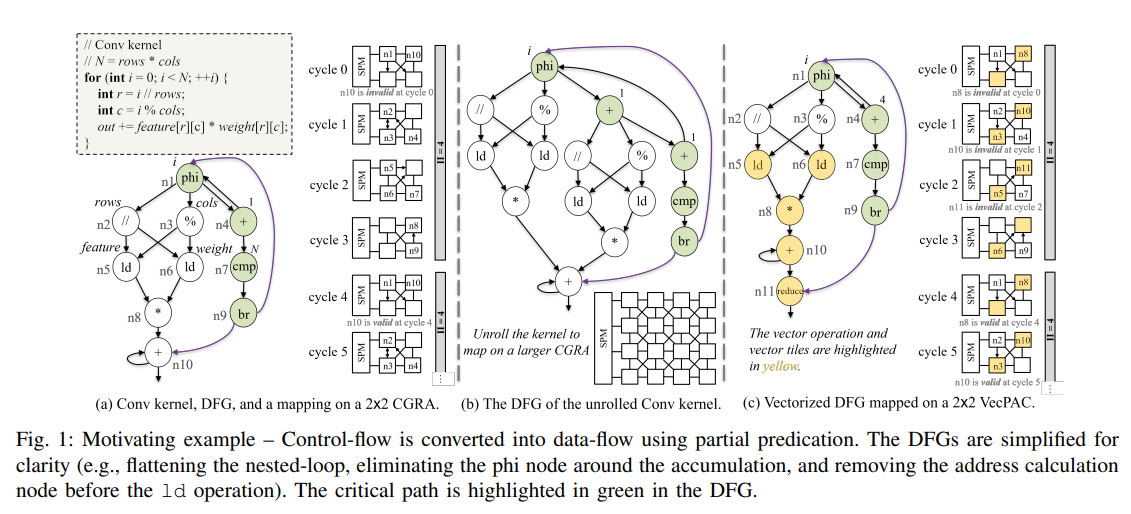
在上面的例子中:
- 这里我们将 CGRA 与单发射顺序执行的 CPU 相比,计算加速比的方法为
#nodes ÷ II。因为#nodes表示一共有多少节点,在 CPU 里我们认为一个周期执行完一条指令,而 II 表示我们开启 loop 的下一轮迭代需要多少个周期。 - (a) 中是朴素的映射,这里 II=4,相当于提供了 2.5x 的加速比。
- (b) 使用了循环展开 unrolling,这里展开因子为 2,II 为 5,得到了 4x 的加速比
。 (注意这里要#nodes ÷ (II ÷ unrolling factor),因为展开之后一轮迭代执行的是原来的两倍的指令) - © 使用了向量化,这里向量化因子为 2,II 为 4,得到了 5x 的加速比
。 (注意这里要#nodes ÷ (II ÷ vector factor),原因同上)
我们可以看到:
- 循环展开可以更好地利用指令级并行 ILP。同时 DFG 也会变大,增加映射的复杂性以及具有更长的关键路径。比如上面的例子中循环展开后 II 从 4 提高到了 5。
- 向量化可以更好地利用数据级并行 DLP。
- 所需面积:A vector FU with N lanes < N scalar FUs.
- 具有向量 FU 的 CGRA 不需要积极展开来提取更多 ILP 来改善映射机会,这样映射的复杂性和关键路径不会增加。比如上面的例子中向量化之后 II 依然为 4。
VecPAC¶
CGRA 架构 ¶
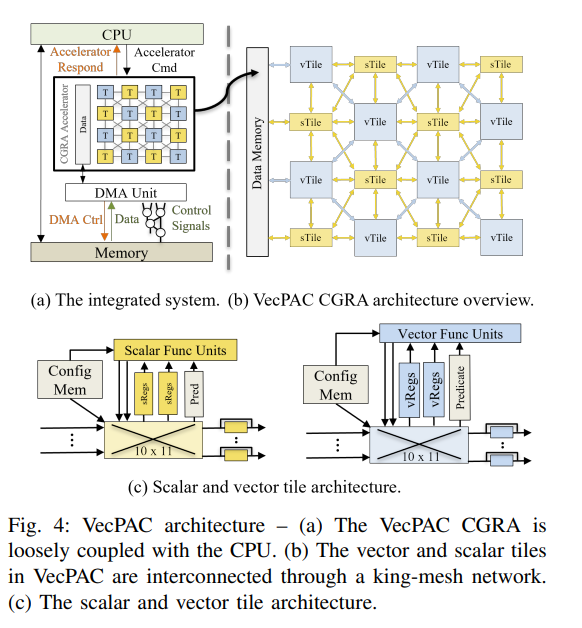
-
Hybrid and Interleaved Design
- 不用所有 tiles 都支持向量化操作,而是 interleave,只有对角线上是 vector FU。
- 原因:实验发现 <50% 的运算是可向量化的。
- 循环携带依赖和不安全的依赖内存操作的内核不能向量化。
- 在可向量化的内核里,也不是所有操作都能向量化,比如控制流运算。

-
Vectorization Support
- vector FUs 不仅支持向量操作,还有更宽的互联网络。
- vector FUs 需要更多的部件来支持向量化运算。在 4*4 VecPAC 中,每个向量 FU 有 4 个通道,每个通道可以支持 16 位定点运算。比如向量加法器就由 3 个全加器和 1 个半加器组成,可以同时进行 4 个 16 位定点加法,然后四个输出打包路由到其他 FU。
- LLVM IR 可以识别所有操作(包括向量化运算
) ,均有对应的硬件支持。归约操作需要 2 个周期。
-
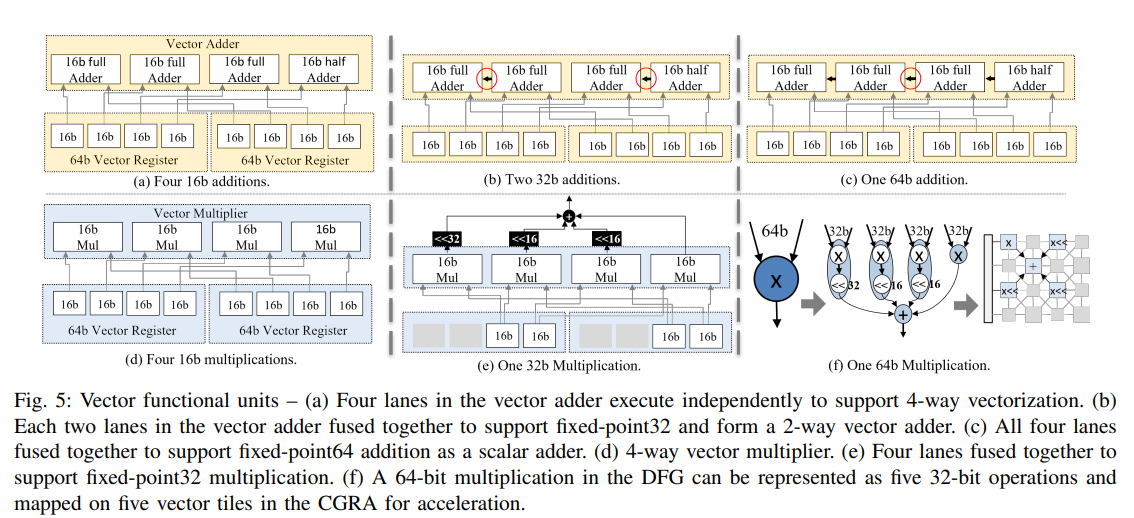
Precision-Awareness
- VecPAC 可以通过将通道组合在一起来配置向量 FU 以不同的精度执行操作。
- 向量加法器支持 4 个 16 位加法,2 个 32 位加法,1 个 64 位加法(需要传递进位
) 。 - 向量乘法器支持 4 个 16 位乘法,1 个 32 位乘法。
编译工具链 ¶
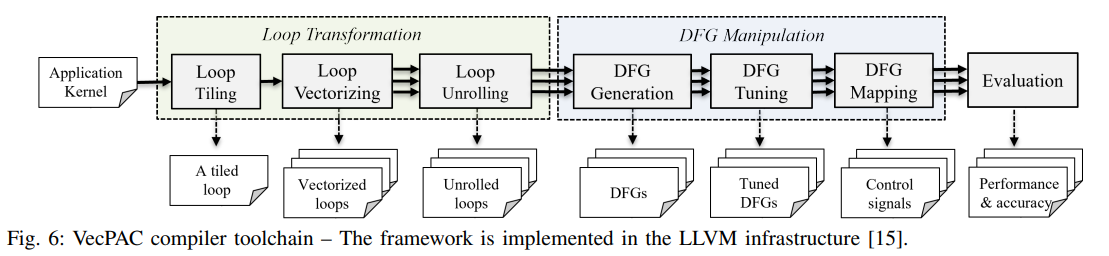
- Loop Transformation
- 循环向量化:这里使用了 LLVM 的 Auto-Vectorization pass 来向量化循环。
- 循环展开:若循环体操作数较少,可能导致 CGRA 计算资源无法被充分利用。展开循环会增加操作数量(扩大 DFG
) ,可能提高 ILP 和 CGRA 利用率。
- DFG Manipulation
- DFG 生成:每个 DFG 节点代表一个基本操作,对应于特定 FU 支持的 LLVM 中的一条指令。使用部分预测将控制流指令(包括分支和 phi 指令)转换为数据流。
- DFG 调整:如果乘法只能以 64 位定点精度执行,则调整过程会将其分成前面描述并如图 5(f) 所示的模式。
- DFG 映射:启发式优化算法,将 DFG 映射到 CGRA 的模路由资源图(MRRG
) 。该算法逐渐增加 II 直到找到一个可行的映射,用 Dijkstra 算法查找图块之间的最短路径并执行操作之间的数据通信路由。
TODO:实验部分