Diffusion + RL¶
约 1298 个字 29 行代码 7 张图片 预计阅读时间 5 分钟
Abstract
"Diffusion + RL"
参考文献:
- 知乎文章“Diffusion Model + RL 系列技术科普博客(11
) :Diffusion-DPO——运用于扩散模型的直接偏好优化” - 知乎文章“Diffusion Model + RL 系列技术科普博客(6
) :DDPO” - Training Diffusion Models with Reinforcement Learning
- Diffusion-DPO: Optimizing Diffusion Models with Reinforcement Learning
- FashionDPO:Fine-tune Fashion Outfit Generation Model using Direct Preference Optimization
- Science-T2I: Addressing Scientific Illusions in Image Synthesis
- ADHMR: Aligning Diffusion-based Human Mesh Recovery via Direct Preference Optimization
- EfficientML.ai Lecture 18 Diffusion Model by Prof. Song Han
Preliminaries¶

-
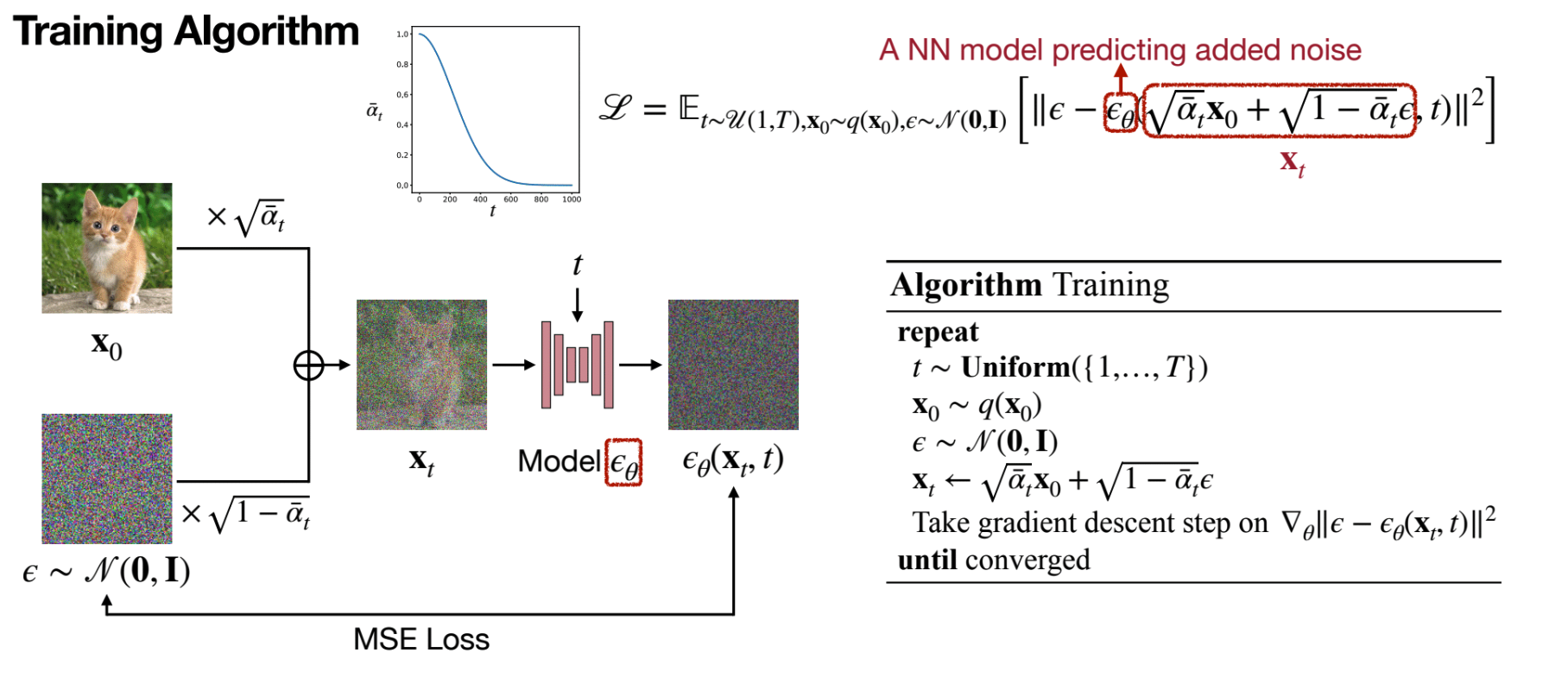
Training
-
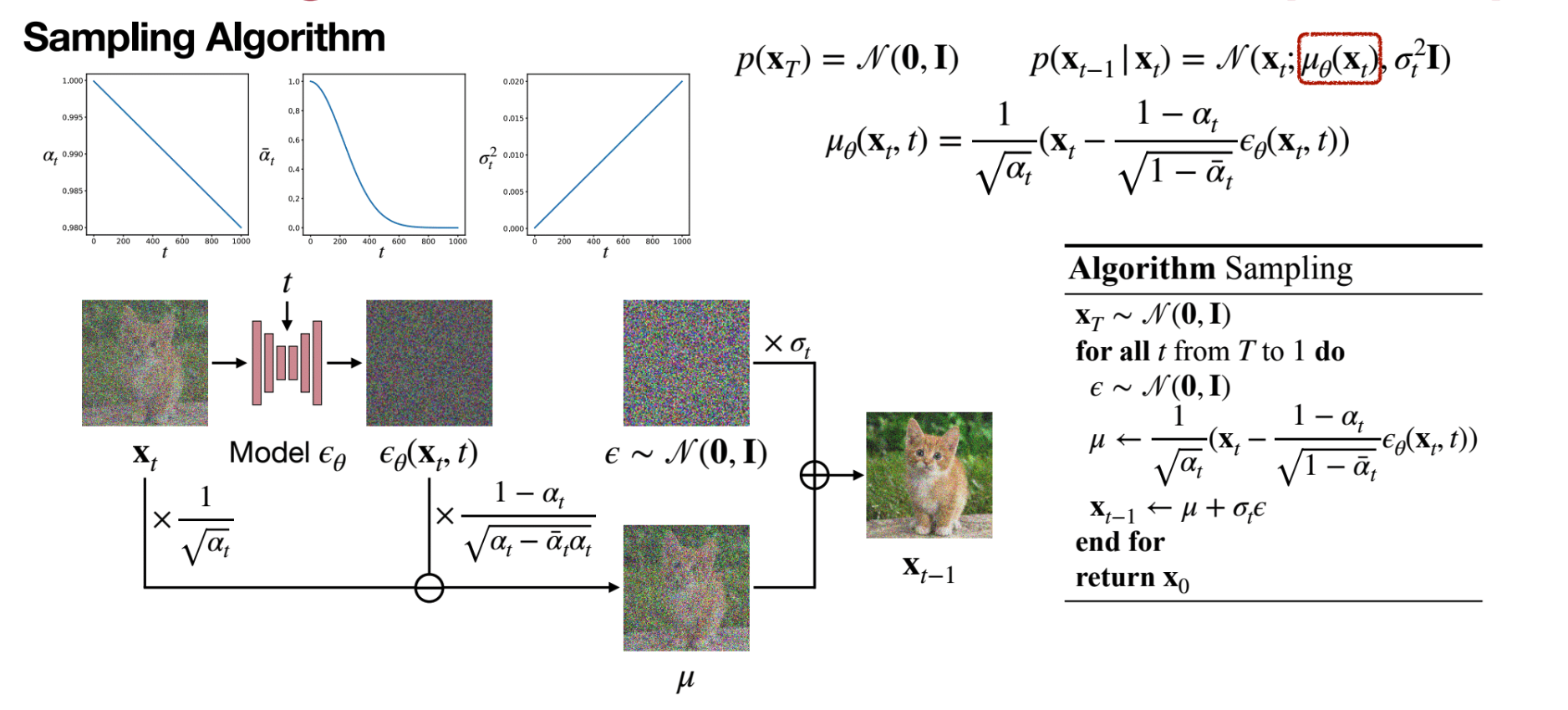
Sampling
DDPO¶
Training Diffusion Models with Reinforcement Learning
-
传统 Diffusion 的训练方式:
-
最大似然估计,损失函数为 MSE,训练目标为预测高斯噪声。
\[ \mathcal{L} = \mathbb{E}_{x_0 \sim p_{data}, \epsilon \sim \mathcal{N}(0, I)} \left[ \left\| \epsilon - \epsilon_{\theta}(x_t,c, t) \right\|^2 \right] \]
-
-
但是大多数应用场景并不直接关注似然值,而是聚焦于人类感知的图像质量、有效性等下游目标。
- 难以通过提示词明确指定的任务(如图像可压缩性
) 。 - 基于人类反馈的任务(如美学质量
) 。
- 难以通过提示词明确指定的任务(如图像可压缩性
- 使用 Markov Decision Process (MDP) 来建模 Diffusion 去噪声过程:
- \(\mathcal{S}\) 表示状态空间,\(s_t=(c,t,x_t)\)。
- \(\mathcal{A}\) 表示动作空间,\(a_t=x_{t-1}\),即去噪一步后的结果。
- \(\mathcal{R}\) 表示奖励函数,\(r_t=r(s_t,a_t)=\left\{\begin{matrix} r(x_0,c) & \text{if } t=0 \text{} \\ 0 & \text{otherwise} \end{matrix}\right.\)
- \(\mathcal{P}\) 表示状态转移概率,\(p(s_{t+1}|s_t,a_t)=(\delta_c, \delta_{t-1}, \delta_{x_{t-1}})\),这里的 \(\delta_t\) 是 Dirac delta 函数,只有在 \(x=t\) 时为无穷大,其他情况下均为 0。
- \(\mathcal{\rho}_0\) 表示初始状态分布,\(\rho_0(s_0)=(p(c),\delta_T,\mathcal{N}(0,I))\)。
- 建模后可以用 RL 的算法来优化梯度,这里称为 DDPO-SF 和 DDPO-IS。
-
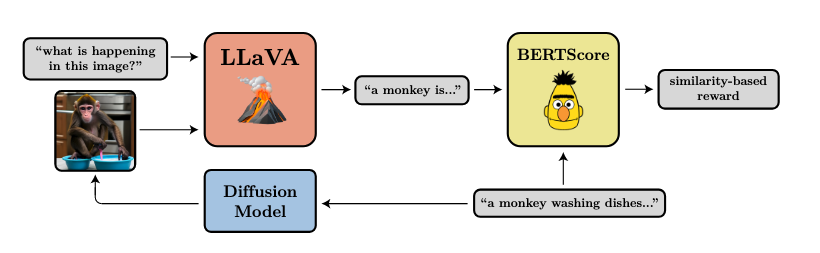
reward function 设计:
- 压缩性,对于扩散模型预训练的训练集,与图像相匹配的文本很少带有图像大小的信息。这就导致了在使用扩散模型生成图像时,很难通过提供文件大小采样出相应大小的图片。预训练模型的这一限制使得基于文件大小的奖励函数成为一个方便的研究示例,大小易于计算同时又无法通过提示词明确指定。这里固定分辨率 512*512。
- 艺术性,使用一个 LAION aesthetics predictor 的评测模型,是以 CLIP 图片编码为输入的一个线性模型,基于 17600 张由人类打分的图片训练而成。训练集中各图片分数从 1 到 10。
- 提示词与图像一致性,采用 VLM 打注释,最后用 CLIP 计算注释和原始 prompt 的相似度。
-
结果
-
从左往右随着 RL 训练的进行,图像生成结果与文本越来越接近,同时风格也变得越来越一致。

-
在压缩、美学、提示词与图像一致性三个指标上,DDPO-SF 和 DDPO-IS 都取得了更好的结果。同时训练中的 BERTScore 也逐渐提高。
- 原论文在 finetune 结束后,将提示文本中的主语和活动替换为训练时未曾见过的内容以测试泛化性。结果发现模型对训练集外的动物,非生命体,或者新的活动,都会采样出预期的结果。
-
Diffusion-DPO¶
Diffusion-DPO: Optimizing Diffusion Models with Reinforcement Learning
- 将 DPO 用在了 Diffusion,不再需要显式的 reward function。
-
损失函数
\[ \begin{aligned} L(\theta) = - \mathbb{E}_{x_0^w, x_0^l\sim D, t \sim U[0,T], x_t^w\sim q(x_t|x_0^w,c,t), x_t^l\sim q(x_t|x_0^l,c,t)} \log\sigma(-\beta Tw(\lambda_t)) \left( \|\epsilon^w - \epsilon_{\theta}(x_t^w,c,t)\|_2^2 - \|\epsilon_{ref}^w - \epsilon_{\theta}(x_t^w,c,t)\|_2^2 - \left(\|\epsilon^l - \epsilon_{\theta}(x_t^l,c,t)\|_2^2 - \|\epsilon_{ref}^l - \epsilon_{\theta}(x_t^l,c,t)\|_2^2\right)^2 \right) \end{aligned} \]- 这里的 \(x_0^w\) 和 \(x_0^l\) 是偏好样本对,我们认为 \(x_0^w\) 是更优的样本。
- 在训练过程中,\(\epsilon_{ref}\) 参数不会被修改,因此对损失函数造成影响的只有以下两项:\(||\epsilon^w - \epsilon_\theta(x^w_t,t)||^2_2\), \(||\epsilon^l - \epsilon_\theta(x^l_t,t)||^2_2\),因此可以看作是在改善 \((x^w_0, c)\) 的去噪过程,同时破坏 \((x^l_0, c)\) 的去噪过程。
Loss 代码实现
def loss(model, ref_model, x_w, x_l, c, beta):
"""
# This is an example psuedo-code snippet for calculating the Diffusion-DPO loss
# on a single image pair with corresponding caption
model: Diffusion model that accepts prompt conditioning c and time conditioning t
ref_model: Frozen initialization of model
x_w: Preferred Image (latents in this work)
x_l: Non-Preferred Image (latents in this work)
c: Conditioning (text in this work)
beta: Regularization Parameter
returns: DPO loss value
"""
timestep = torch.randint(0, 1000)
noise = torch.randn_like(x_w)
noisy_x_w = add_noise(x_w, noise, t)
noisy_x_l = add_noise(x_l, noise, t)
model_w_pred = model(noisy_x_w, c, t)
model_l_pred = model(noisy_x_l, c, t)
ref_w_pred = ref(noisy_x_w, c, t)
ref_l_pred = ref(noisy_x_l, c, t)
model_w_err = (model_w_pred - noise).norm().pow(2)
model_l_err = (model_l_pred - noise).norm().pow(2)
ref_w_err = (ref_w_pred - noise).norm().pow(2)
ref_l_err = (ref_l_pred - noise).norm().pow(2)
w_diff = model_w_err - ref_w_err
l_diff = model_l_err - ref_l_err
inside_term = -1 * beta * (w_diff - l_diff)
loss = -1 * log(sigmoid(inside_term))
return loss
Applications¶
-
FashionDPO:Fine-tune Fashion Outfit Generation Model using Direct Preference Optimization
- 场景:时尚搭配(衣服、鞋子、配饰等)生成
-
Evaluator:3 experts
- quality,用 MLLM 打分
- compatibility,resnet 投影,然后 VBPR prediction 打分
- personalization,利用 user history,CLIP 计算分数
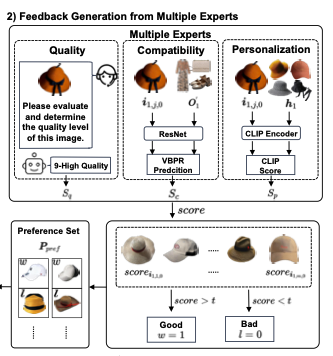
-
Science-T2I: Addressing Scientific Illusions in Image Synthesis
- 场景:模型生成出来的图片可能违背科学事实。
- 数据集:利用 GPT4o 生成并构成偏好数据对。
- 训练方法
- SFT,使用 Science-T2I 数据集微调,使其具备基本的科学知识。
- Online RL,使用 SciScore(奖励模型)进行 RL 训练。其中奖励模型基于 CLIP-H,也是在 Science-T2I 数据集上微调的。
-
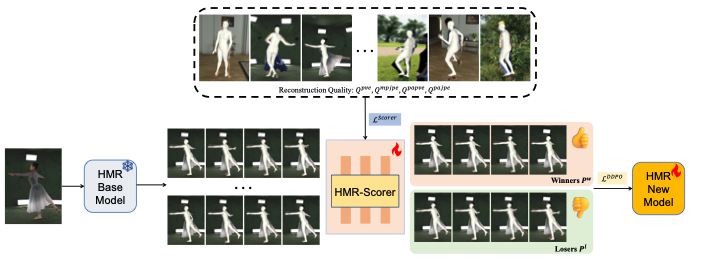
ADHMR: Aligning Diffusion-based Human Mesh Recovery via Direct Preference Optimization
- 场景:人体 mesh 恢复。
- 生成 \((x_{win}, x_{lose})\) 数据。
- Scorer,训了一个模型对输入进行打分,有一些领域的设计 ~(看不懂)~;训练方式是学习相对的好坏。
- 根据 Scorer 对候选数据打分,随后选最高分 K 个和最低分 K 个组成 K 组数据对;得到偏好数据集。
- 最后基于偏好数据对 DPO 训练。