通过生成式预训练提高语言理解能力 ¶
约 946 个字 2 张图片 预计阅读时间 3 分钟

介绍 ¶
- NLP 里部分特定任务带标注的数据(labeled data)稀少,难以训练判别模型。
- 使用 unlabeled data 遇到的问题:
- 不明确该使用什么优化函数。
- 如何进行子任务迁移(NLP 中不同子任务的差距大
) ,某个任务上的表示在另一个任务上不一定有效。
- 本文发现可以通过在 unlabeled data 上对语言模型进行预训练,随后在特定任务上进行微调。这里通过 task-aware input 任务感知输入来微调。这样对模型的改动小。
- semi-supervised learning: unlabeled data 上的预训练,labeled data 上做微调。
- 模型:Transformer decoder.
- 结果表明在所研究的 12 项任务中,有 9 项任务中的表现明显优于使用专为每项任务设计的架构的判别训练模型。
Note
本文核心:将 Transformer decoder 拿出来,在 unlabeled data 上进行预训练,随后在 labeled data 上进行微调
框架 ¶
-
无监督预训练:
- 对于 token \(\mathcal{U}=\{u_1,\ldots,u_n\}\), 我们用损失函数 \(L_1(\mathcal{U})=\sum\limits_{i} \log P(u_i | u_{i-k}, \ldots, u_{i-1}; \Theta)\)
- 表示我们已知前 i-1 个词,预测第 i 个词的概率。
- \(k\) 表示上下文窗口,为输入序列的长度。
-
使用 Transformer decoder 架构。
\[ \begin{aligned} h_0 & = UW_e +W_p, \\ h_i & = \text{TransformerBlock}(h_{i-1}), \forall i \in [1, n], \\ P(u) & = \text{softmax}(h_n W_e^T), \\ \end{aligned} \]- \(U=[u_{-k},\ldots,u_{-1}]\) 是 token 向量,\(W_e\) 是词嵌入矩阵,\(W_p\) 是位置嵌入矩阵,\(n\) 是层数。
GPT 与 BERT 的区别
- BERT 使用的是非标准语言模型,即完形填空的方式,可以同时看到前后文。而 GPT 使用的是标准语言模型,只能通过前文预测后文。
- 因此 BERT 使用的是 encoder,GPT 使用的是 decoder。
- GPT 的目标函数是预测下一个词,BERT 是通过前后的词预测中间的词。相比之下 GPT 的任务更难,因此本文的实验结果是不如 BERT 的。但也因此这个方法的天花板更高,所以作者后续要一直把模型做大。
- 对于 token \(\mathcal{U}=\{u_1,\ldots,u_n\}\), 我们用损失函数 \(L_1(\mathcal{U})=\sum\limits_{i} \log P(u_i | u_{i-k}, \ldots, u_{i-1}; \Theta)\)
-
有监督微调:
- 对于输入 token \(x^1, \ldots, x^m\) 和标签 \(y\),我们用损失函数 \(L_2(\mathcal{C})=\sum\limits_{(x,y)}\log P(y|x^1, \ldots, x^m; \Theta) = \sum\limits_{(x,y)}\text{softmax}(h^m_lW_y)\)
- 这里的 \(h_l^m\) 表示前 m 个 token 经过 GPT 模型后最后一层的输出,\(W_y\) 是输出层的权重。
- 本文发现可以使用 \(L_3(\mathcal{C}) = L_1(\mathcal{U}) + \lambda * L_2(\mathcal{C})\) 作为损失函数,其中 \(L_1\) 是预训练中使用的语言模型损失函数,这样可以提高模型的泛化能力。
- 对于输入 token \(x^1, \ldots, x^m\) 和标签 \(y\),我们用损失函数 \(L_2(\mathcal{C})=\sum\limits_{(x,y)}\log P(y|x^1, \ldots, x^m; \Theta) = \sum\limits_{(x,y)}\text{softmax}(h^m_lW_y)\)
-
任务特定的输入转化:微调时把要把子任务表示为输入序列 + 标签的形式。
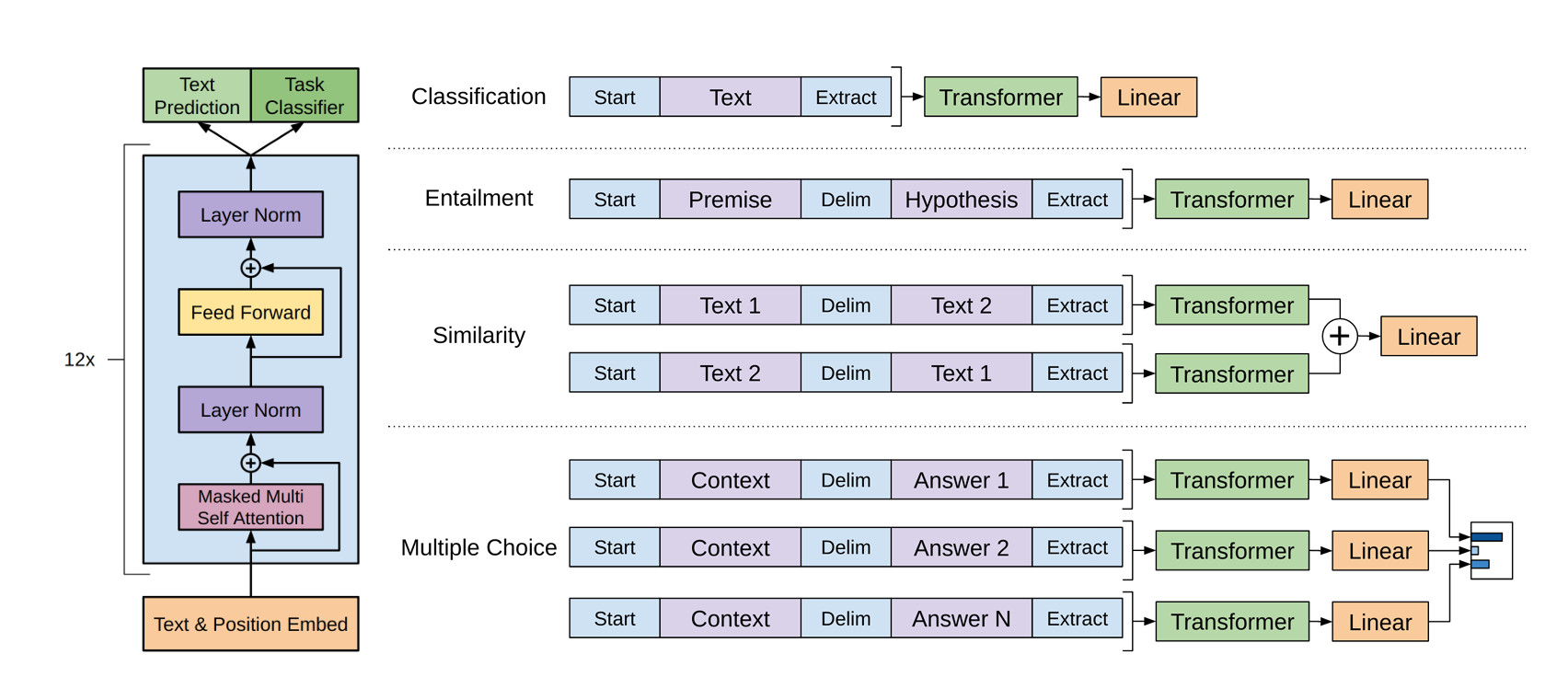
- Classification 分类:将文本加上起始和终止符(特殊符号,不与原文本重复
) ,最后的线性层用来将 Transformer 结果投影到标号空间(如对于两分类的问题,输出结果就为 [0,9] 的标号) 。 - Entailment 蕴含:将两个文本拼接起来,中间用特殊符号隔开。
- Similarity 相似度:本质是一个二分类问题。需要注意的是文本相似具有对称性,因此我们使用 Text1-Delim-Text2 和 Text2-Delim-Text1 两种方式进行拼接,分别计算 Transformer 的结果后相加。
- Multiple choice 多选:每一个答案我们将其和问题拼接作为一个输入,最后将所有的结果进行 softmax 计算,得到概率最大的答案。
- Classification 分类:将文本加上起始和终止符(特殊符号,不与原文本重复