EMNLP2024¶
Abstract
速读了 EMNLP 2024 和多模态有关的一些论文,记录如下。 参考:知乎文章"EMNLP 2024 多模态学习最新论文合集出炉!快速关注热点研究!"。
Paper 价值 = 新意 * 有效性 * 问题大小
RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models¶
- 医学。
- LVLM 回答会出现事实性错误,因此需要 RAG。
- 但是 RAG 可能有两个问题:
- 检索的 k 太小(无法覆盖必要信息)或者太大(干扰信息);
- 这里的 retriever 是通过 CLIP 来训练的。
- 方法 Factuality Risk Control,在校准集上找最合适的 k。给定一个 k,计算他的事实风险(通过概率、KL 散度),随后如果 \(p_k\) 小于等于阈值就加入候选集合。可以证明这样选出来的集合的准确性。(问题:泛化性?只在当前数据集做了)
- 过度依赖上下文,即使模型原本能够正确回答,引入检索上下文后可能导致错误答案。
- 方法 DPO,进行微调,给定 image query,把 groundtruth y 作为偏好的答案,如果 ab=y 但是 af≠y 就进行调整。
- 检索的 k 太小(无法覆盖必要信息)或者太大(干扰信息);
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models¶
- 故事:多模态MLLM => 引出幻觉问题 => 相关工作(基于推理或者基于微调)
- 基于推理的缺点:有额外开销。
- 微调的问题:要大量数据,之前是人力解决;微调对齐模型需要计算资源。
- 本文:不需要配对数据并且在微调阶段更加高效。基于 unlearning 遗忘原理,在负样本上进行梯度上升。关键是如何以既经济又可靠的方式管理正样本和负样本,即区分真实物体和幻觉物体。这里用了 CLIP。
- motivation:做了实验(输入 200 images 给 MiniGPT 和 LLaVA 生成 caption,然后人工标注是否出现幻觉,接着送到 CLIP 里)发现有幻觉和没幻觉的分数确实有差距,可以通过阈值来区分。
-
方法:
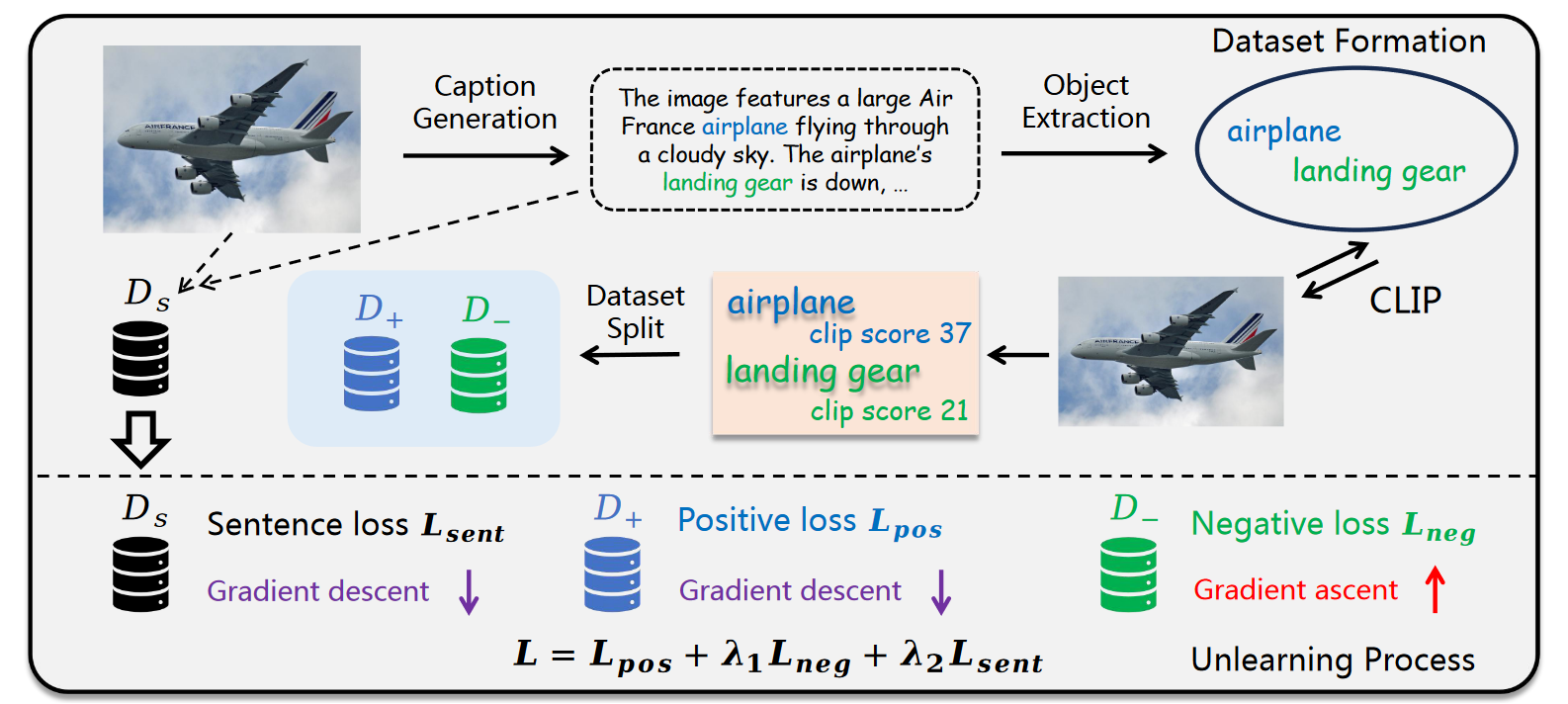
- 数据集生成,给一个图像,生成字幕,根据 objects 划分子句,分别送入 CLIP 计算分数,和阈值比较是否出现幻觉。这里有三个数据集,Ds 表示总体句子,D+ 表示无幻觉的子句(每个子句截止到这个物体的所有句子,之后的句子不用)集合。D- 表示有幻觉的子句集合。
- Unlearning,如果只使用 unlearning 会破坏语言理解能力,因此这里有三个损失,D- 是梯度上升,其他为梯度下降。
By My Eyes: Grounding Multimodal Large Language Models with Sensor Data via Visual Prompting¶
- 传感器领域,text-only prompt 可能很长,效果不好(因为 LLM 有上下文限制)而且很贵(token/dollar)。
- 方法:
- 将传感器数据可视化为图像,并结合任务描述作为视觉提示输入到支持多模态的LLMs中。这种方法能够有效减少输入序列的长度,降低计算成本。
- 设计了自动化工具,根据任务描述自动生成最优的可视化图表。
- 局限:处理需要精确数值计算,以及可视化的方法。
M^2PT: Multimodal Prompt Tuning for Zero-shot Instruction Learning¶
- 故事:MLLM zero-shot 不行,可以用 instruction tuning。之前的 PEFT 只关注单模态,没有跨模态。
-
方法:
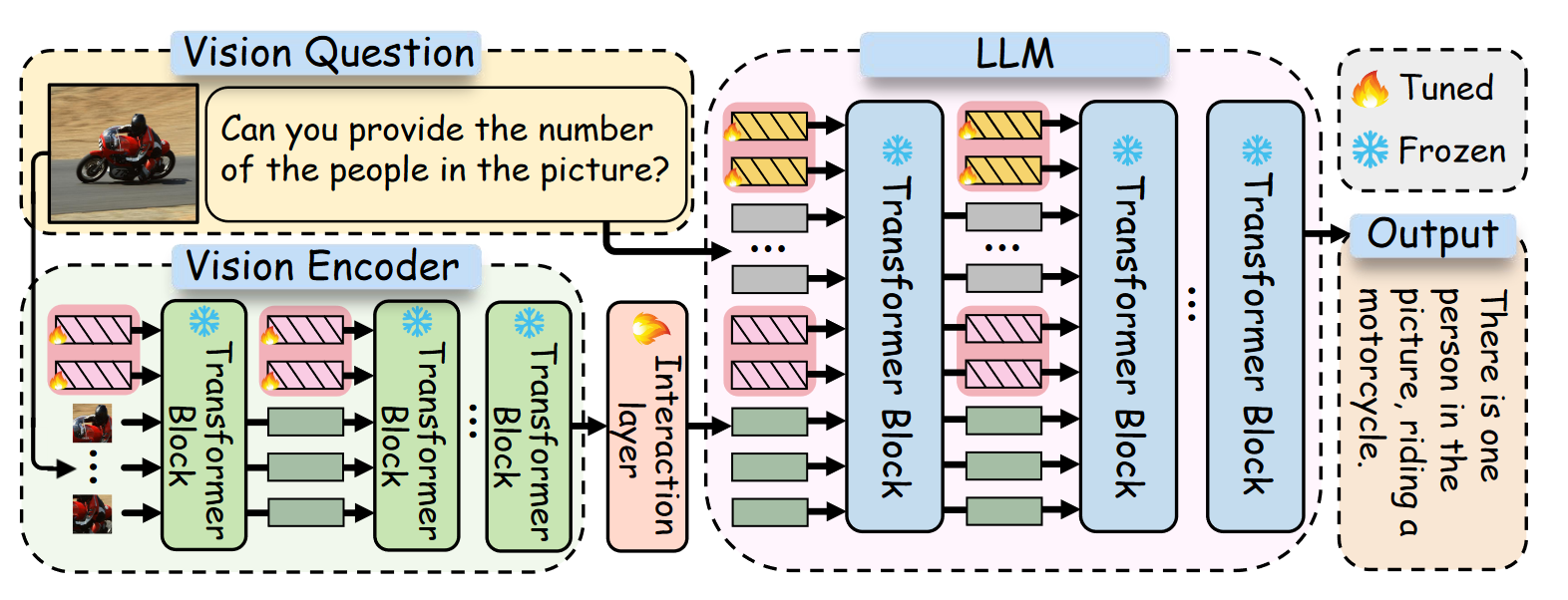
- text prompt(在 LLM 每层的输入前);visual prompt(在 vision encoder 每层前);Cross-modality Interaction(在 visual encoder 最后一个投影,这个看上去和 VLM 的 projection 差不多)。
- 实验发现插入 prompt 的 activation 较大,说明起到了重要作用。消融实验发现这三个 prompt 去掉都会掉点。不存在能够在不同任务中一致实现最佳性能的通用最佳 prompt 长度。同时较早层的 prompt 比后面层的更重要,“困难”的任务可能需要更长的提示才能有效捕获潜在的模式。
Unifying Multimodal Retrieval via Document Screenshot Embedding¶
- retrieve 文档,要对不同文档进行解析(问题:需要预处理,破坏了文档本身的外观,如布局位置信息)。本文希望用截图代替,DSE(Document Screenshot Embeeding)。
-
方法:分别用 VLM 和 LM encode,随后对比学习。
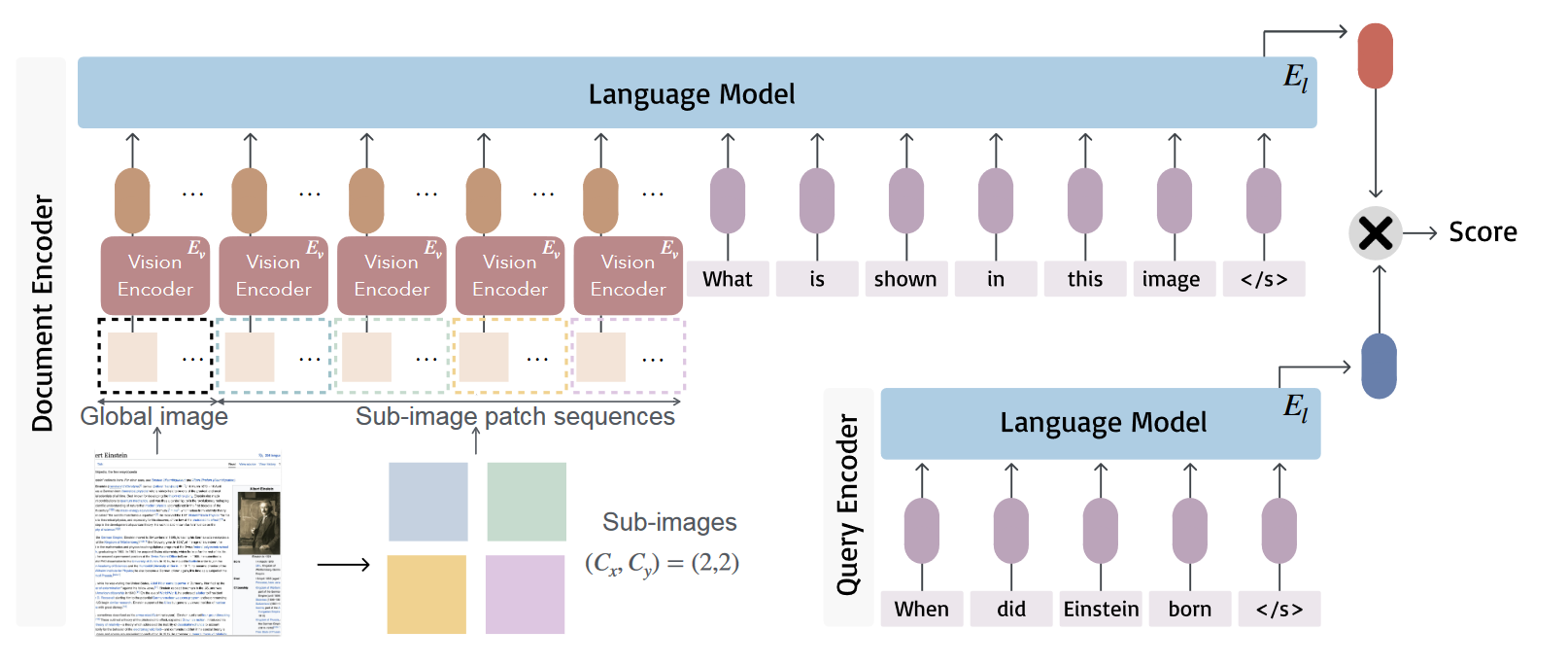
-
局限:要在更通用的 tasks 上检验(文档不同格式的);这里是 SFT,可以尝试 pretraining;现在依赖视觉数据,可能出现低质量的截图。
Nearest Neighbor Normalization Improves Multimodal Retrieval¶
-
CLIP 这样的对比学习,预训练的损失(如 InfoNCE)不代表下游任务的准确性,往往需要微调。可能出现 hubness 问题,即匹配的结果太多,某些检索候选成为许多查询的最近邻。(有些图像只是比其他图像更受对比模型的青睐是因为它们与各种查询标题具有很高的 cos sim)
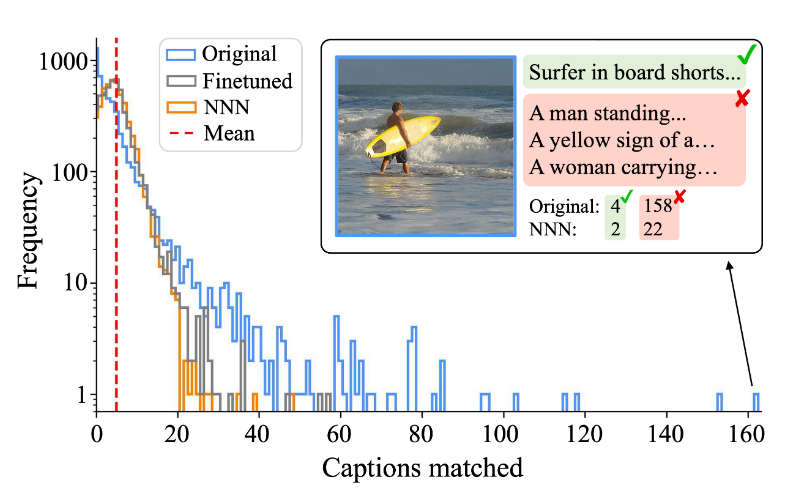
-
引入了离线的 bias,计算方法:有一个参考数据库,里面有一些 query。对每个 retrieve candidate,计算与他最相近的 k 个 queries,随后对这 k 个相似分数求平均,乘上一个常数因子,作为 bias。进行检索时,将本来的分数减掉 bias 即可。
- 局限:对于跨模态模型来说要慢得多,因为计算每个 img-text pair 匹配分数需要前向传递。
To Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Modelss¶
- 本文系统研究了 MLLMs 中 connector 的选择对模型性能的影响。任务分为 coarse-grained perception,fine-grained perception,reasoning。
- feature-preserving,保持视觉特征的 patch 数量,分成 linear(只有线性层,如 LLaVA);nonlinear(线性+激活函数,如 LLaVA-1.5)。
- feature-compressing,通过减少视觉 token 的数量来优化计算效率,括平均池化(average pooling,易于训练,但丢失局部信息,不利于细粒度)、注意力池化(attention pooling,复杂度高,不利于训练,也不容易保留局部信息,更多是全局)和卷积映射(convolutional mapping,有局部细节,缺乏直观捕获全局特征的能力,参数量适中)。
- 结论:connector 的选择取决于 resolution、任务粒度和计算预算。虽然 feature-preserving 通常提供最佳性能,但它们相对于 feature-compressing 的优势随着分辨率的提高而减弱,而它们的计算成本呈指数级上升。在 feature-compressing 中平均池化和 C-Abstractor 的性能优于 QFormer,在所有分辨率和任务粒度上始终提供更好的结果。