ChatEDA: LLMs 驱动的 EDA 自主代理 ¶
约 926 个字 5 张图片 预计阅读时间 3 分钟
Abstract

- Paper: ChatEDA: A Large Language Model Powered Autonomous Agent for EDA
- 2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD)
介绍 ¶
- LLMs 展现了在 NLP 方面的卓越能力,可以将其用于 EDA 工具的交互(scripts 如 TCL
) ,简化 RTL 到 GDSII 的设计流程。 - 本文范围:用户以自然语言提出需求,框架能调用 EDA 工具的 API 生成可执行程序,并返回结果。
- 本文贡献:
- 第一个 LLM 驱动的 EDA 接口框架和方法论,ChatEDA。
- 一个微调的语言模型 AutoMage,用于增强 ChatEDA 的交互能力。
- 综合评估显示 ChatEDA 和 AutoMage 性能卓越,在各种任务中超越了 GPT-4 和其他知名 LLM。
框架 ¶
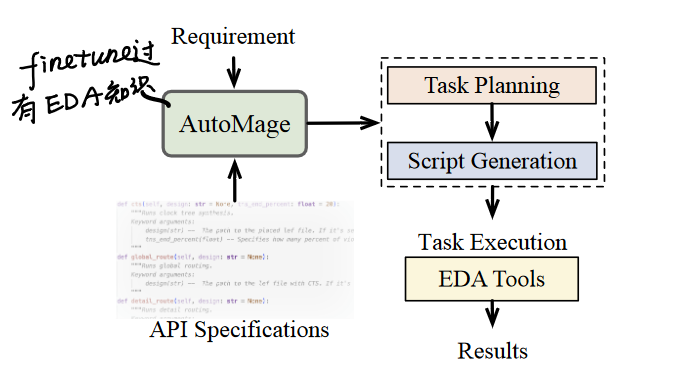
- Task Planning: 解释需求并将其分解为一系列 sub-tasks 子任务。
- Script Generation: 根据分解的小任务和外部工具(如 OpenROAD)的规范,生成对应任务的 python scripts。
- 需要同时将 API 规范、用户需求、分解的 sub-tasks 传入 AutoMage
。 (问题: token length limit?)
- 需要同时将 API 规范、用户需求、分解的 sub-tasks 传入 AutoMage
- Task Execution: 执行生成的脚本,并返回结果。
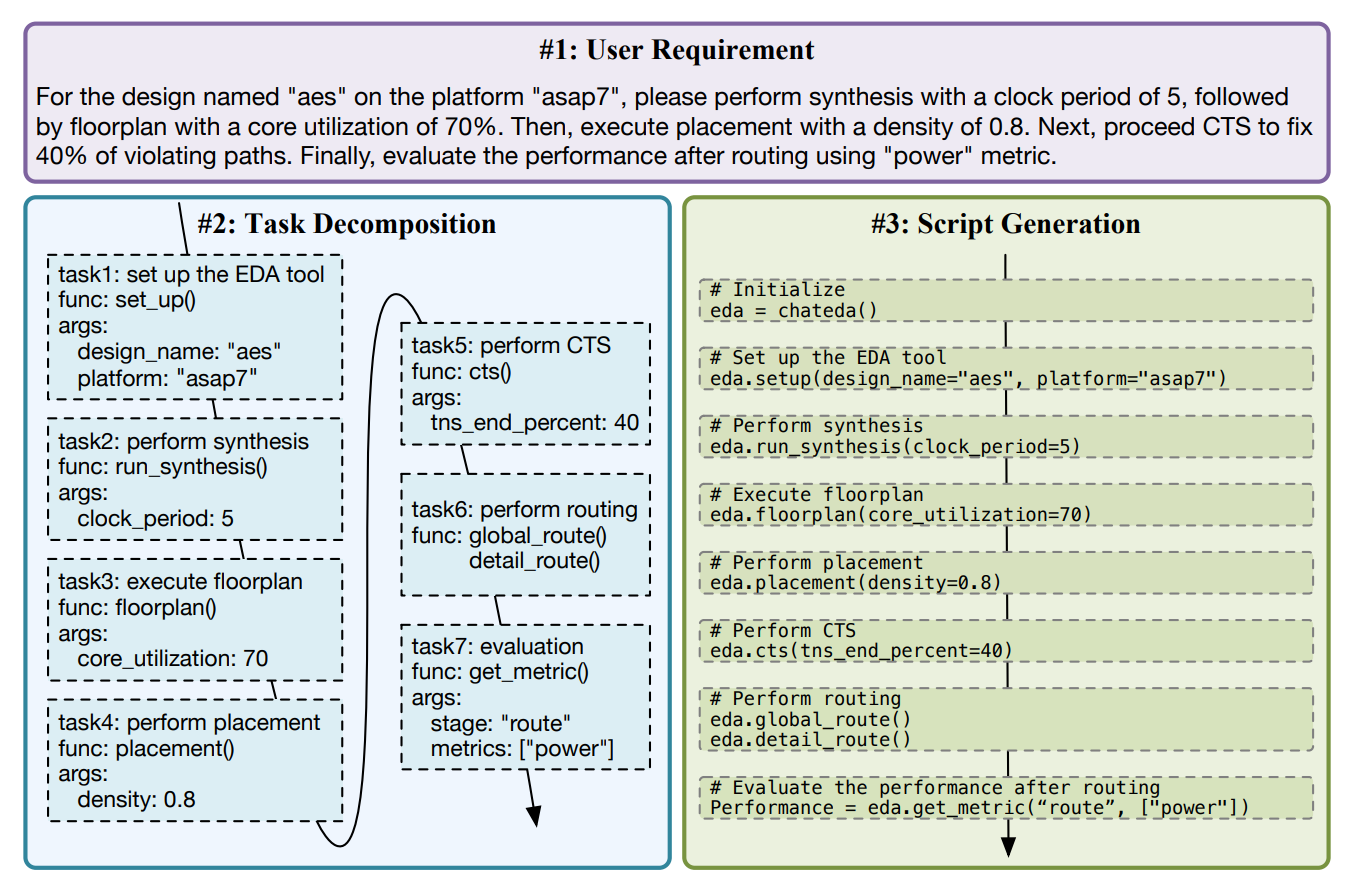
Example
Instruction Tuning¶
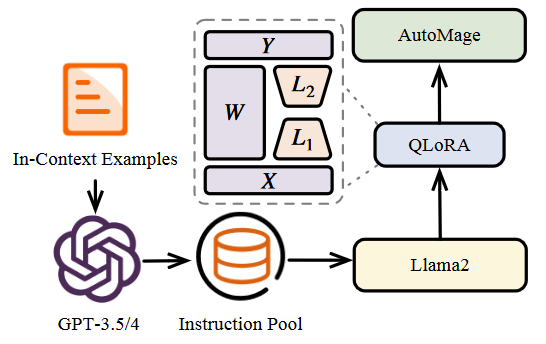
AutoMage 是一种专家级 LLM,擅长使用 EDA 工具。为此本文提出基于 LLaMA-2 进行指令微调,主要包括了下面的步骤:
- Self Instruction: 为了 Instruction Tuning,我们需要收集高质量的指令,教 LLM 如何通过 API 使用 EDA 工具。这里使用了 self instruction paradigm,即使用不同的指令模板来查询 GPT-3.5/4,并从中自动获取更多指令。
- Instruction Collection: 对部分 GPT 生成的数据进行了手动创建和调整,并对数据集进行校对,最后得到约 1.5k 指令。
- Instruction Fine-tuning: 在微调过程中,每条指令都包括一个 requirement 和 response,其中 response 包括一个 plan 和 script。为了确保适当的模型序列长度,整个训练集中的要求和响应都会被连接起来,并使用唯一的标记来划分这些片段。
- 使用 QLoRA 微调。
实验 ¶
Evaluation of LLMs¶
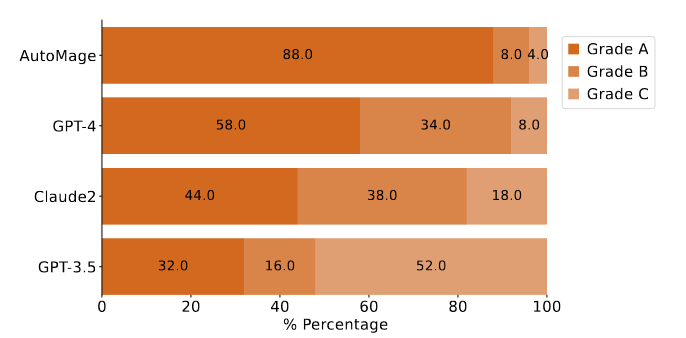
该系统采用三级评分制,A 级代表最高成绩。A 级表示 task planning & script generation 都正确且连贯,B 级表示 planning 正确但 generation 有错误,C 级表示 planning & generation 均有错误。
下图结果表明,AutoMage 的表现大大优于 GPT-4 和其他 LLM,它将成为 ChatEDA 最可靠的控制器。
Case Study¶
- Performance Evaluation: 要求模型成功执行综合流程,包括评估阶段。这项任务强调了 LLM 的基本应用及其与 API 接口相关的使用顺序。
- AutoMage 和 GPT-4 都圆满完成了这项任务。
- Parameter Grid Search: 要求 LLM 执行网格搜索,这在很大程度上依赖于逻辑,包括参数的遍历。这项任务进一步审查了 LLM 对每个 API 参数的理解能力。
- AutoMage 和 GPT-4 的表现都非常出色。
- Parameter Tuning Method: 要求模型提供参数调整解决方案。
- 与 GPT-4 相比,AutoMage 更倾向于生成一个复杂的搜索空间,这赋予了 AutoMage 的参数调整策略更大的潜力。
- Customized Optimization: 定制优化需要根据用户指定的搜索空间对模型中的参数进行调整。这一过程严格评估了模型对调整功能的理解以及每个 API 接口参数的重要性。
- AutoMage 恰当地理解了用户自定义参数调整的要求,而 GPT-4 则对参数组合优化的概念理解不足。
- Clock Period Minimization: 根据具体需求指导 AutoMage 使用 API 界面。但是,我们并没有教它使用从评估结果中获得的自我反馈来修改参数。
- AutoMage 成功完成了所提供的测试案例,而 GPT-4 却失败了。