CLIP¶
约 1296 个字 5 张图片 预计阅读时间 4 分钟
Abstract

摘要 ¶
- SOTA 的视觉系统都是训练预测固定预定义好的类别的能力(如 ImageNet 有 1000 个类
) 。 - 直接从图像原始文本中学习是一种很有前途的替代方法,它可以利用更广泛的监督来源。本文在 4 亿对 (image, text) 数据集上进行与训练来学习图像特征,自然语言被用来引用已学过的视觉概念(或描述新的概念
) ,从而在下游任务进行 zero-shot 推理。 - 在 30 多个数据集中进行测试,无需任何特定的数据集训练,通常就能与完全有监督的基线模型相媲美。例如,在 ImageNet zero-shot 上的准确率与原始 ResNet-50 不相上下。
介绍 ¶
- 预训练从网络文本中学习的可扩展预训练方法,在 NLP 上取得了革命性成功,但 CV 领域在 crowd-labeled datasets(如 ImageNet)上进行预训练仍然是主流。
- 随后本文梳理了 20 年来 CV 技术的发展脉络,其中也有相关工作使用自然语言监督进行 image representation 图像表征学习,但是效果远低于其他方法。这些弱监督模型与最近直接从自然语言学习图像表征的探索之间的一个关键区别在于规模,即方法是正确的,但是数据集的大小不足。
- 使用自然语言监督的好处:更容易 scale,不用人工定义 label,自然语言在网络上资源丰富;模型不仅学习到 representation,还将该表征与自然语言联系起来,从而实现灵活的 zero-shot。
- 因此本文创建了 4 亿图像文本对的数据集,并从头开始训练 CLIP,即 Contrastive Language-Image Pre-training。
方法 ¶
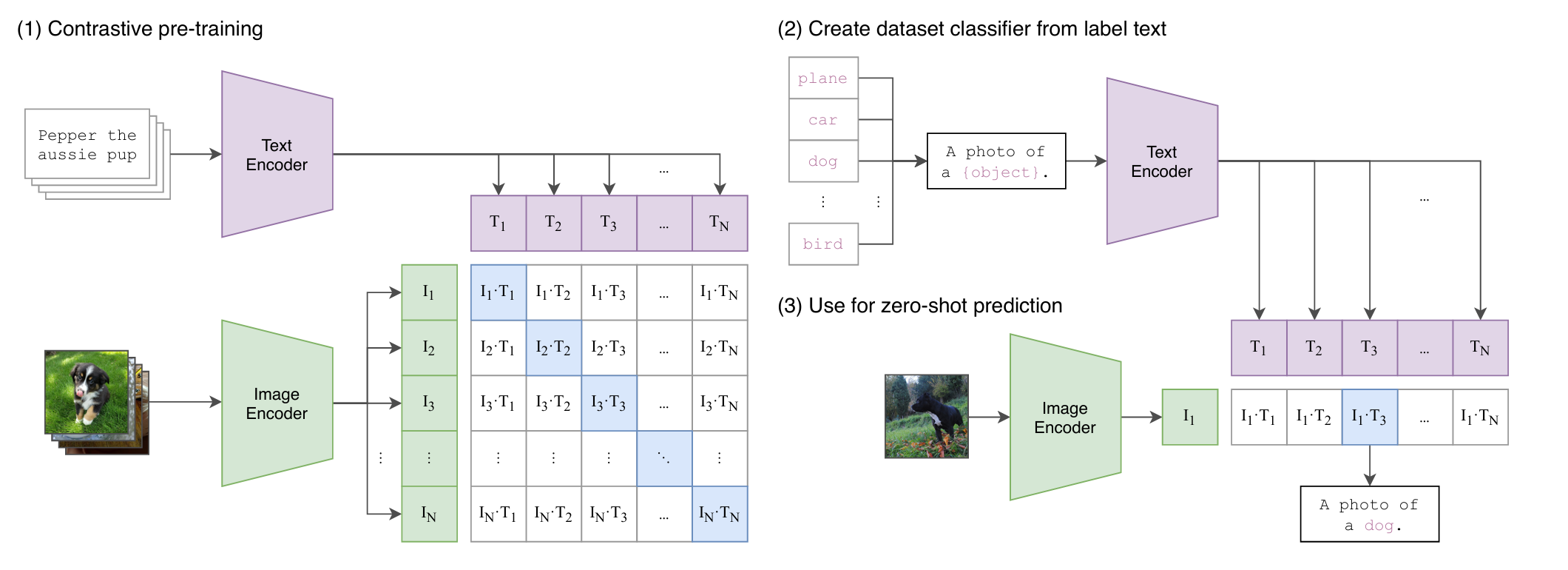
- Contrastive Pre-training
- N 张 image 和 N 个 text 输入,分别通过 Encoder,随后得到 N+N 个 token,共有 N^2 个图像文本对,其中对角线上 \(I_i\cdot T_i\) 为正样本对(共 N 对
) ,其余 N^2-N 个为负样本对。 - Image Encoder 这里使用的是 ResNet (RN50x4, RN50x16, and RN50x64) 或者 ViT (ViT-B/32, ViT-B/16, and ViT-L/14)
- training efficiency was the the key to successflly scaling natural language supervision.
- 为什么使用对比学习:对于给定 image 预测文本,这个问题是很难的,因为可以有不同角度的描述。相反 contrastive 的目标函数比 predictive 的要更容易训练。
- N 张 image 和 N 个 text 输入,分别通过 Encoder,随后得到 N+N 个 token,共有 N^2 个图像文本对,其中对角线上 \(I_i\cdot T_i\) 为正样本对(共 N 对
- Dataset
- Zero-shot prediction
- 做推理时,首先定义好要提取的 class(可以是 ImageNet 的 1000 个类,也可以是其他类
) ,随后将每个 class 送入 Text Encoder 得到 token \(T_i\)。对于给出的图像通过 Image Encoder 得到 \(I_1\), 最后得到 N 个 pairs \(I_1\cdot T_i\),最后根据 softmax 得到每个 class 的概率,最后输出对应的 class。 - prompt template: 本文定义了提示词模板,例如
A photo of a {object}这里 object 用 class 来进行填充,输出的也就是这个句子。- 在训练时是使用自然语言的句子,因此在推理时我们希望保持一致,否则性能会下降。
- polysemy 多义性,即打标签的单词可能会有多重含义。
- 类似于 GPT-3 的 prompt engineering,这里我们可以在句子里添加额外信息以帮助推理,例如
A photo of a {label}, a type of pet.也可以使用 ensembling 的方法,即多次推理。在 ImageNet 里本文提供了 80 个不同的 context prompt。
- 做推理时,首先定义好要提取的 class(可以是 ImageNet 的 1000 个类,也可以是其他类
实验 ¶
- 性能远超同样的设计(Visual N-Grams)在 ImageNet 上的数据。
- 但是比较是不公平的,因为训练使用的数据集和训练资源差了几个量级。
-
Zero-shot performance

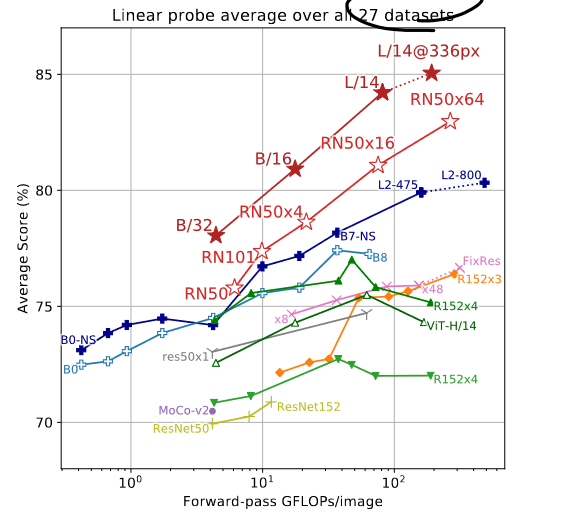
- Linear Probe 指的是将权重冻住,只训练一个最后的分类头。
- 可以看到 CLIP 在很多数据集上的表现都好于 ResNet,对于一些比较难的问题(如 计数、推理)表现较差。
-
泛化性较好,不受数据分布和偏移的影响。

-
few-shot 情况下,如果只给一两个样本,CLIP 的表现反而会变差(即不如 zero-shot
) ,当样本增多时,CLIP 的表现会逐渐变好。 - 使用全部的下游数据进行 linear probe 微调,可以看到 CLIP 的表现会更好。
-
和人类表现进行了比较,可以发现对人类较难的问题 CLIP 也表现较差。
局限 ¶
- 这里使用了 ResNet50 作为 baseline,但实际上在大多数数据集上它并非 SOTA。
- CLIP 的 zero-shot 性能依然不够,对于一些比较难比较抽象的问题,CLIP 的表现相当于瞎猜。
- 对于一些 out-of-distribution 的数据,依然缺乏泛化性。
- 类别需要提前给定,无法完成生成式任务。
- 数据利用的效率不够高效(DL 模型的通病
) 。 - 这里展示的结果也是在调参后得到的,现有的 benchmark 也不能代表真正的模型的能力。
- 数据没有清洗,可能会有 bias。
- 许多复杂的任务和视觉概念都很难仅仅通过文本来指定。而且在从 zero-shot 到 few-shot 时性能会下降,这和人类的学习方式不同。