APEX: 使用频繁子图分析的自动化处理元素设计空间探索框架 ¶
约 1358 个字 5 张图片 预计阅读时间 5 分钟
Abstract

- Paper: APEX: A Framework for Automated Processing Element Design Space Exploration using Frequent Subgraph Analysis
- ASPLOS 2023: Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems
介绍 ¶
- 本文 APEX: PE design space exploration 框架
- Frequent Subgraph Mining 找 patterns
- 子图合并生成定制的 PE
- 自动把生成定制 PE 的 verilog 代码
- PE 的设计空间:
- 操作的数量和类型
- 最简单的 PE:加法器 / 乘法器;更通用的 PE:ALU + 乘法器 + LUT + ...
- 专用的 PE 可能会有多个 ALUs 来执行向量操作(但利用率可能因此降低
) 。
- 互联方式:可配置路径极少的 PE vs 很多 Mux 的 PE。
-
输入输出的数量:
- 2 输入 1 输出 vs 很多输入。
- 可以利用常数寄存亲减少 PE 的输入数量(如图像处理中的卷积
) 。
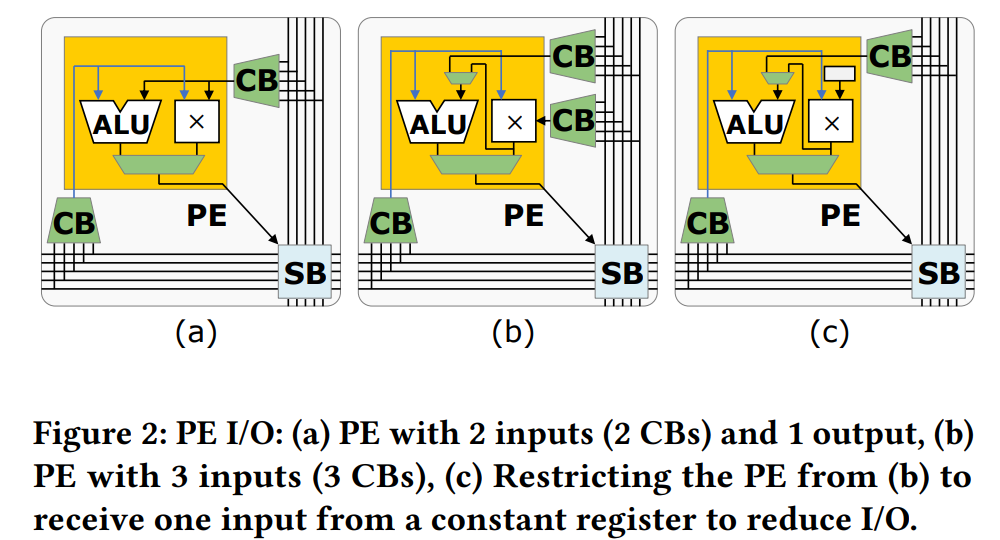
- 操作的数量和类型
APEX¶
算法 ¶
-
Subgraph Mining
- 基于 Halide 表示的 kernel,将应用程序简化为包含计算和内存节点的 CoreIR DFG。DFG 的 frequent subgraph 频繁子图代表了应用中的潜在的复杂操作。
-
使用 GRAMI,将 DFG 和 threshold(如果出现了 >threshold 次,那么我们认为是 frequent)作为输入,找到频繁子图。
Example
这里可以看到子图 b, c, d 之间有重叠的点。
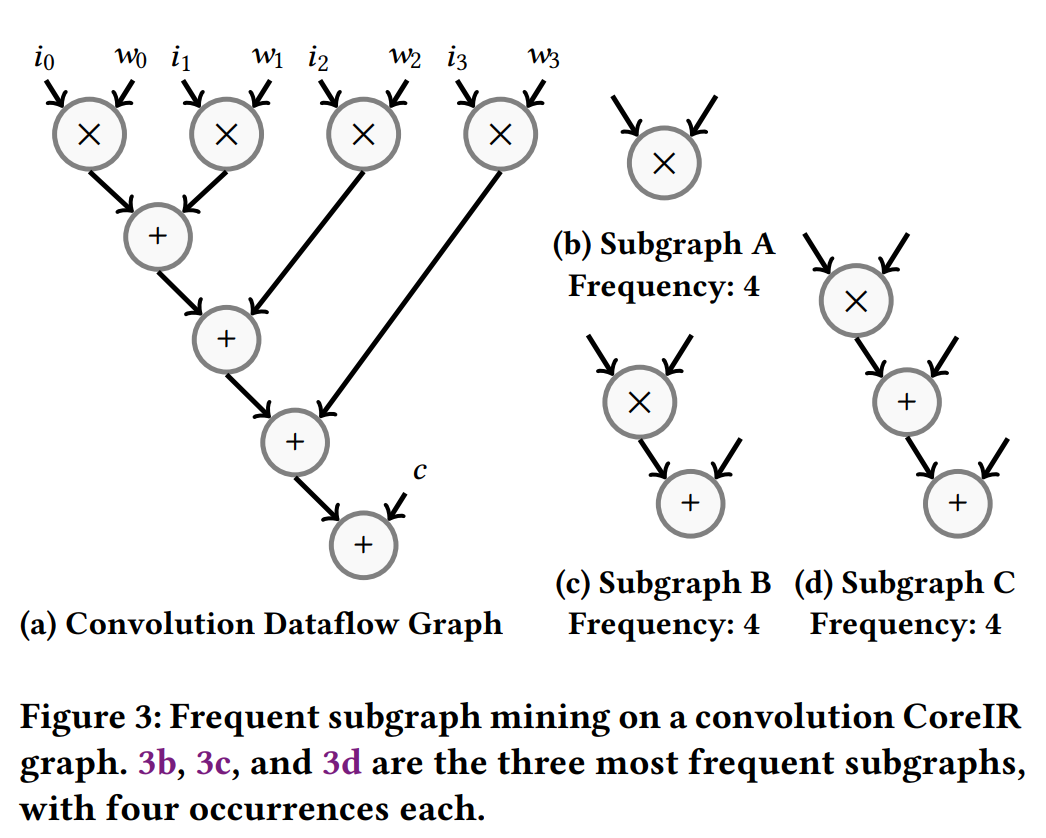
-
Maxmial Independent Set Analysis(MIS)
- 找出的频繁子图可能会有 overlap,因此需要找独立集。
- 将每个子图表示为一个点,如果两个子图有 overlap 则在两个点上连边。最后计算这个新图的 MIS。
- 子图的 MIS 大小表示有多少个充分利用了该子图的 PE 可用于加速应用。
-
Subgraph Merging
- 如果两个节点的操作相同,或可以在同一硬件块上实现,则可以合并。如果两条边的每个端点节点都可以合并,且目的节点上的端口匹配,则可以合并(最后一个条件对于非交换操作是必要的
) 。 - 然后,将这些潜在的 merging opportunities 合并机会转化为 compatibility graph。如果两个合并机会可以同时实现,就说他们是 compatibile 的,两个点会有一条边。
- compatibility graph 中的每个节点都有一个权重 w,与应用给定合并所减少的面积相对应。这种面积缩减是通过合成子图中使用的原始节点并确定其面积来计算的。例如,节点 a1/b2 表示将 a1 与 b2 合并。如果进行合并,合并后的子图将只包含这两个节点的一个加法器。因此,减少的面积就是一个加法器的面积。
- 最后计算 compatibility graph 的最大权重独立集。
Example
图 5c 显示了一个二分图,子图 A 的操作 / 边在左侧显示为节点,子图 B 的操作 / 边在右侧显示为节点。从左边节点到右边节点的边代表潜在的合并机会。在这个例子中,节点 a0 和 b0 都是常量,因此在二分图中有一条相应的边。节点 a1、a2、b2 和 b3 都是加法运算,因此这些节点之间有相应的边。最后,边 a2 → a1 和边 b3 → b2 以加法运算为起点,以加法运算为终点,并且 a1 和 b2 的端口都匹配,因此这些边也有可能被合并。
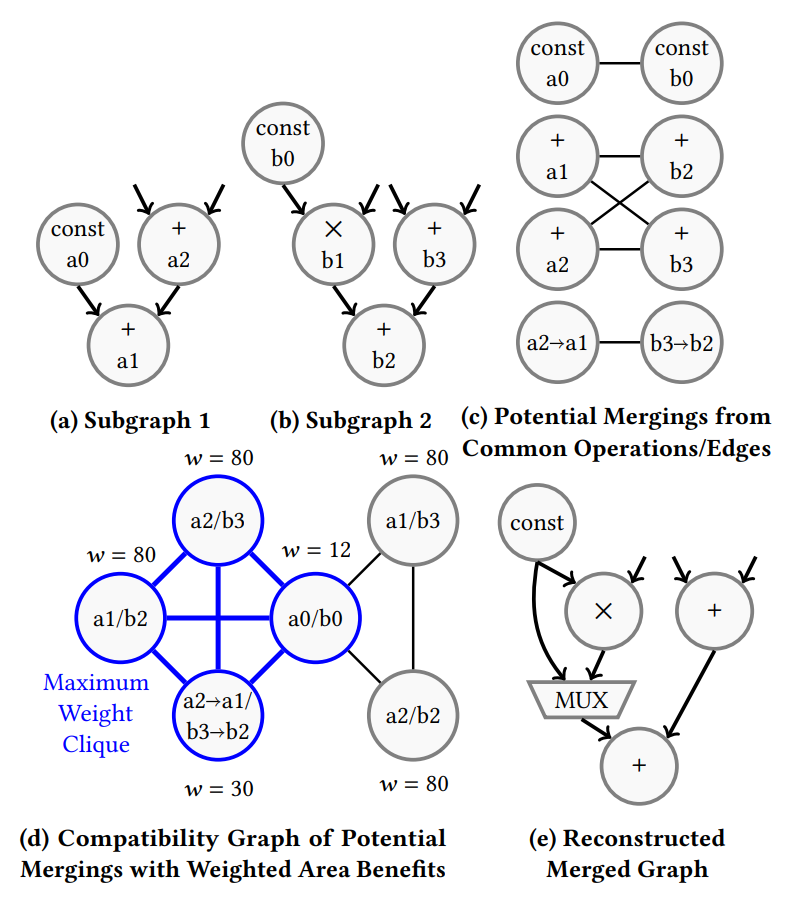
- 如果两个节点的操作相同,或可以在同一硬件块上实现,则可以合并。如果两条边的每个端点节点都可以合并,且目的节点上的端口匹配,则可以合并(最后一个条件对于非交换操作是必要的
框架 ¶
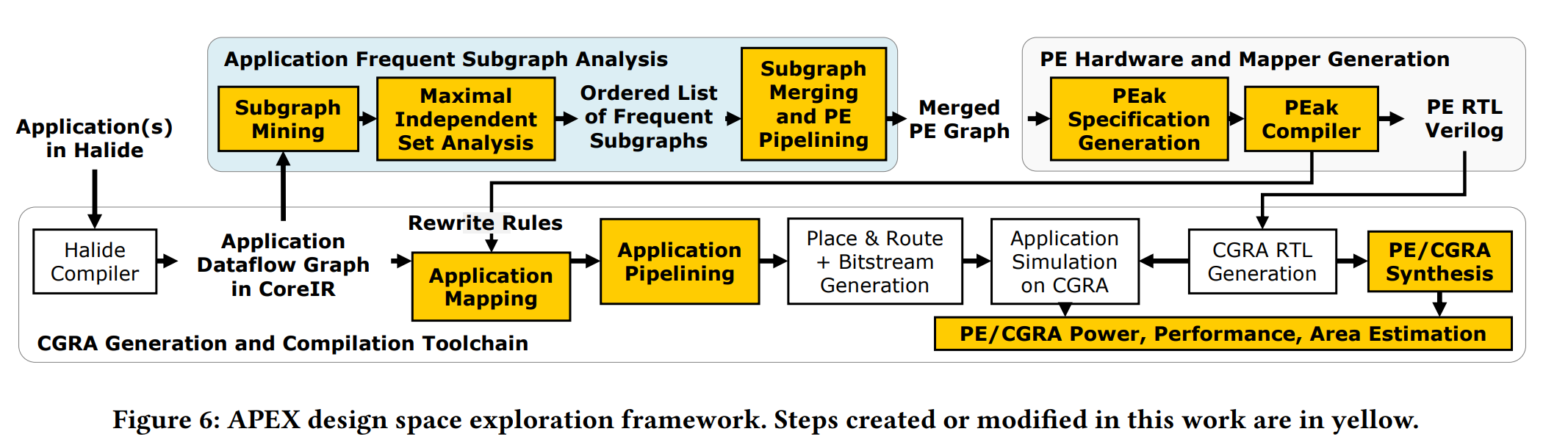
- Frequent Subgraph Analysis
- 执行上一节的 算法,生成 frequent subgraphs。
- 将 PE graph 转为 PE 规范(PEak DSL
) 。 - 自动流水线工具对 PE 进行流水线处理。
- PE Hardware and Mapper Generation
- 输入 PEak 规范,通过 PEak 编译器生成 PEak RTL Verilog 和 application mapper 的重写规则。
- PE RTL 送入 CGRA RTL Verilog 生成器,生成最后的 CGRA 硬件。
- Application Mapping and Application Pipelining
- application mapper 利用重写规则,生成 CoreIR 图的覆盖,同时尽量减少使用的 PE 数量。
- 自动流水线工具利用寄存器文件流水线技术对映射应用图进行流水线处理。
- 根据流水线映射图,我们生成 CGRA 配置比特流,并使用 Synopsys VCS 对 CGRA Verilog 进行仿真。
- PE/CGRA Synthesis and Evaluation
PEak¶
看不懂,略
自动化 PE 流水线 ¶
在物理设计过程中,为了达到较高的目标频率(∼1 GHz
- 类似于静态时序分析,对每增加一个流水线级所减少的临界路径延迟进行建模,以确定适当的流水线级数。
- 每次迭代都需要第二种算法,将寄存器重新定时到最佳位置,以最大限度地缩短关键路径。
自动化应用程序流水线 ¶
- 如果 PE 有流水线寄存亲,那么这个操作需要多个周期,相应地也需要更多的寄存器来保持功能。
- 从寄存器链到寄存器文件的转换是完全自动化的。我们对长度大于 2 的寄存器链进行转换
。 (作为 FIFO 的寄存器文件替代了在分支延迟匹配过程中可能添加的长流水线寄存器链)
实验 ¶
TODO